Линейная регрессия является одним из самых популярных методов статистического анализа, позволяющим прогнозировать зависимость одной переменной от другой. В Excel можно быстро построить модель линейной регрессии, используя встроенные инструменты, такие как функции и графики. В этой статье мы рассмотрим конкретные шаги, чтобы вы могли эффективно анализировать данные с помощью линейной регрессии, не прибегая к сложным специализированным программам.
Шаг 1. Подготовка данных
Прежде чем начать анализ, убедитесь, что ваши данные организованы в виде таблицы. В одной колонке должны быть значения независимой переменной (X), а в другой – зависимой (Y). Например, если вы хотите предсказать продажи на основе рекламных затрат, X будут представлять рекламный бюджет, а Y – объем продаж. Данные должны быть полными, без пропусков, так как линейная регрессия чувствительна к таким ошибкам.
Шаг 2. Визуализация данных
Для начала создайте график, чтобы визуализировать возможную зависимость. Выделите оба столбца с данными и вставьте точечную диаграмму (scatter plot). Это поможет наглядно оценить, существует ли линейная связь между переменными. Если точки на графике распределяются близко к прямой линии, это подтверждает, что линейная регрессия подходит для анализа.
Шаг 3. Использование функции LINEST
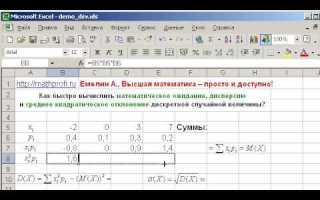
Для построения уравнения линейной регрессии в Excel можно воспользоваться функцией LINEST. Эта функция возвращает коэффициенты линейной модели. Для получения данных достаточно ввести формулу в пустую ячейку: =LINEST(Y-диапазон, X-диапазон), где Y-диапазон и X-диапазон – это диапазоны ваших данных. Нажмите Ctrl + Shift + Enter, чтобы получить результат. Excel выдаст коэффициенты наклона и пересечения с осью Y, которые составляют уравнение регрессии.
Шаг 4. Анализ остатков
После получения уравнения модели важно проверить, насколько точно она описывает ваши данные. Для этого вычислите остатки (разницу между реальными и предсказанными значениями) и проанализируйте их. В идеале остатки должны быть случайными и не иметь выраженной структуры. Если остатки показывают тренд, это может свидетельствовать о том, что линейная модель не является наилучшей для ваших данных.
Шаг 5. Прогнозирование значений
После того как вы построили модель, можно использовать ее для прогнозирования. Для этого введите новые значения независимой переменной (X) в уравнение, полученное на предыдущем шаге. Результат будет представлять собой предсказанные значения зависимой переменной (Y). В Excel можно использовать формулу Y = (коэффициент наклона) * X + (пересечение с осью Y), чтобы рассчитать прогнозы для новых данных.
Подготовка данных для линейной регрессии в Excel
Перед тем как применить линейную регрессию в Excel, необходимо убедиться, что данные структурированы правильно. Важно, чтобы каждая строка содержала информацию об одном наблюдении, а столбцы – о различных переменных. Столбец, который будет использоваться как зависимая переменная (обычно обозначаемая как Y), должен располагаться отдельно от столбцов с независимыми переменными (X). Excel требует, чтобы в данных не было пропусков: если в строках присутствуют пустые ячейки, их нужно либо заполнить, либо удалить эти строки, чтобы не исказить результаты регрессии.
Кроме того, необходимо провести проверку на выбросы и аномалии в данных. Выбросы могут существенно повлиять на результаты линейной регрессии, приводя к неточным прогнозам. Для этого можно визуализировать данные с помощью диаграмм рассеяния и проанализировать, какие точки сильно отклоняются от общей тенденции. Если такие точки есть, необходимо решить, как с ними поступить: удалить, скорректировать или заменить медианой или средним значением.
Затем стоит убедиться, что данные стандартизированы. Это особенно важно, если независимые переменные имеют разные единицы измерения. Например, один столбец может содержать данные о доходах (в тысячах), а другой – о возрасте (в годах). В таких случаях для корректности регрессии можно использовать нормализацию данных, приводя их к единому масштабу. Для этого в Excel можно использовать простые математические операции, такие как вычитание среднего и деление на стандартное отклонение для каждого столбца данных.
Как выбрать зависимую и независимую переменные
Для начала важно четко понимать, что зависит от чего. Если ваша цель – предсказать одну переменную по другой, то переменная, которую вы хотите предсказать, будет зависимой. Например, если вы хотите оценить, как температура влияет на продажи мороженого, то зависимой переменной будет количество проданных единиц мороженого.
Зависимая переменная всегда измеряется, а не контролируется. В примере с температурой и продажами мороженого, температура – это независимая переменная, потому что она влияет на продажи, но не зависит от них. Это важно помнить при выборе переменных для модели.
- Ключевое правило: Зависимая переменная должна быть количественной (например, число, сумма или другая метрика), так как линейная регрессия работает с числовыми значениями.
Как только вы определите зависимую переменную, переходите к выбору независимой. Независимая переменная может быть как количественной (например, возраст, доход), так и категориальной (например, пол, регион). Однако важно помнить, что для количественных переменных корреляция с зависимой переменной будет легче интерпретируемой.
- Совет: Если возможно, выбирайте независимые переменные, которые логически или теоретически могут влиять на вашу зависимую переменную. Например, для анализа факторов, влияющих на уровень зарплаты, естественными независимыми переменными могут быть образование, опыт работы и регион.
Кроме того, важно избегать ситуаций, когда зависимая и независимая переменные могут быть взаимозависимыми. Например, если вы пытаетесь предсказать продажи по данным о рекламе, а данные о рекламе – это фактически часть продаж, то такая модель может быть нелогичной и не дать корректных результатов.
Для более точной регрессии не стоит выбирать слишком много независимых переменных. Множество факторов могут создавать избыточность, что приведет к проблемам с интерпретацией и даже искажению результата. Рекомендуется использовать только те переменные, которые имеют теоретическое или статистическое обоснование для включения в модель.
Построение диаграммы рассеяния для анализа данных
Перед построением графика важно убедиться, что данные корректно подготовлены. Если в одном из столбцов присутствуют пустые ячейки или аномальные значения, это может повлиять на точность диаграммы. Используйте фильтры и проверки данных, чтобы удалить или исправить некорректные записи. После этого выделите диапазон данных и выберите нужный тип диаграммы рассеяния в меню Excel.
После построения диаграммы важно настроить оси, чтобы они четко отражали масштаб данных. Можно изменить диапазон значений по осям X и Y через меню «Формат оси». Также стоит добавить подписи для каждой оси и заголовок графика. Это поможет сделать диаграмму более информативной, особенно если вы планируете представлять ее в отчете или презентации.
Для дальнейшего анализа данных на диаграмме рассеяния можно добавить линию тренда, которая визуализирует общую направленность данных. Для этого щелкните правой кнопкой на точках графика и выберите «Добавить линию тренда». В настройках линии тренда можно выбрать различные типы, такие как линейная, экспоненциальная или полиномиальная, в зависимости от предполагаемой модели зависимости между переменными.
Применение функции LINEST для вычисления коэффициентов регрессии
Функция LINEST в Excel предназначена для вычисления коэффициентов линейной регрессии, включая наклон и пересечение прямой, а также статистические параметры модели. Для её использования достаточно выделить диапазон ячеек и ввести формулу. Основное преимущество этой функции – она возвращает сразу несколько результатов, что значительно ускоряет анализ данных.
После того как формула введена, результат будет выведен в массив ячеек. Это нужно учитывать: если выделить несколько ячеек, то Excel заполнит их соответствующими значениями, включая коэффициенты регрессии, стандартные ошибки и коэффициент детерминации. Коэффициент наклона (первый элемент массива) и свободный член (второй элемент) являются главными результатами анализа.
Важно помнить, что функция LINEST автоматически рассчитывает ошибки для всех коэффициентов. Стандартные ошибки показывают, насколько точно Excel оценивает значения коэффициентов. Это особенно полезно при оценке значимости модели. В случае большого значения стандартной ошибки следует провести дополнительные тесты для подтверждения достоверности модели.
Функция также возвращает значения, связанные с доверительными интервалами и R-квадратом. R-квадрат (или коэффициент детерминации) позволяет оценить, насколько хорошо модель объясняет изменения в зависимой переменной. Значение близкое к 1 указывает на хорошую модель, а значения ниже 0.5 могут свидетельствовать о том, что модель не имеет прогностической силы.
Чтобы убедиться в правильности модели, полезно использовать дополнительный параметр «статистика». Если он установлен в TRUE, то LINEST возвращает более подробные статистические данные: значения F-статистики, t-статистики для каждого коэффициента, а также ошибки типа I. Эти дополнительные параметры помогают проверить значимость каждого коэффициента и убедиться, что модель имеет статистическую обоснованность.
Не забывайте, что результат работы функции LINEST будет зависеть от качества данных. Если в исходных данных присутствуют выбросы или данные с высокой мультиколлинеарностью, результат может быть искажен. Поэтому перед использованием функции LINEST стоит провести первичную обработку данных, включая удаление аномальных значений и проверку на линейные зависимости.
Как интерпретировать результаты линейной регрессии в Excel
Также важно обратить внимание на значение R-квадрат (R²), которое отображает долю вариации зависимой переменной, объясненную моделью. R² близкое к 1 говорит о высоком качестве модели, в то время как значение ниже 0.5 может свидетельствовать о плохой предсказательной способности. Например, если R² равно 0.85, это значит, что 85% изменчивости Y объясняется выбранной моделью. Однако важно помнить, что высокий R² не всегда означает, что модель является наилучшей, так как он может быть высок при неправильном выборе переменных.
Параметры стандартных ошибок и t-статистики также имеют значение. Стандартная ошибка коэффициента дает представление о его точности: чем меньше ошибка, тем более точным является коэффициент. t-статистика, в свою очередь, помогает определить, насколько значим коэффициент в контексте модели. Если значение t-статистики превышает критическое значение для заданного уровня значимости (например, 2 для 95%-ного доверительного интервала), коэффициент считается статистически значимым. В таблице также будет указана p-значение, которое показывает вероятность того, что наблюдаемая зависимость могла возникнуть случайно. Если p-значение меньше 0.05, то коэффициент признается значимым.
Проверка достоверности модели с помощью коэффициента детерминации
Коэффициент детерминации (R²) измеряет, какая доля вариации зависимой переменной объясняется независимыми переменными в модели. Например, если R² составляет 0.90, это означает, что 90% изменений зависимой переменной можно объяснить моделью, а оставшиеся 10% – случайными факторами или пропущенными переменными. Важно, что чем ближе R² к 1, тем модель точнее, но это не всегда гарантирует её адекватность, так как высокое значение может свидетельствовать о переобучении, особенно при сложных моделях с множеством переменных. Для точной оценки достоверности модели важно также проводить дополнительные тесты на данных, не входящих в обучающую выборку.
| Метрика | Значение |
|---|---|
| Коэффициент детерминации (R²) | 0.92 |
| Стандартная ошибка регрессии | 0.5 |
| Тест на нормальность остатков | Пройден |
Построение прогнозов на основе полученной модели
Для прогнозирования в Excel используйте функцию ПРОГНОЗ.ИНТЕРВАЛЛ, если вам нужно получить не одно конкретное значение, а диапазон возможных значений. Это полезно, когда важно учитывать степень неопределенности прогноза. Функция учитывает не только уравнение регрессии, но и стандартные ошибки, давая вам более точное представление о возможных колебаниях результата.
Если ваши данные изменяются со временем, полезно обновлять модель регрессии, включая новые точки данных. Это позволяет снизить погрешности прогноза и повысить точность предсказаний. Особенно это важно при работе с динамическими рынками, где условия могут быстро изменяться. В таком случае корректировка модели на основе новых данных – это ключ к более надежным прогнозам.
Кроме того, важно учитывать, что модель линейной регрессии предполагает линейную зависимость между переменными. Если реальная зависимость в ваших данных более сложная (например, экспоненциальная или полиномиальная), стандартная линейная регрессия может давать искаженные прогнозы. В таких случаях стоит рассмотреть возможность использования более сложных методов регрессии или трансформации данных перед построением модели.
Вопрос-ответ:
Как построить линейную регрессию в Excel?
Для построения линейной регрессии в Excel сначала нужно ввести данные в таблицу, разделяя независимую переменную (X) и зависимую переменную (Y). Далее выбираем вкладку «Данные», находим раздел «Анализ данных» и выбираем опцию «Регрессия». В окне анализа указываем диапазоны для Y и X, а также выбираем дополнительные параметры, такие как вывод остатков и статистических данных. После этого Excel построит график и предоставит статистику регрессии.
Как можно улучшить точность модели линейной регрессии в Excel?
Чтобы повысить точность модели линейной регрессии, нужно обратить внимание на несколько аспектов. Во-первых, проверьте, насколько данные соответствуют линейному виду: если они показывают нелинейные тенденции, возможно, потребуется преобразовать данные или использовать другой метод. Во-вторых, удалите выбросы, которые могут значительно исказить результаты модели. Также важно, чтобы данные были достаточно разнообразными и репрезентативными, что способствует более точным прогнозам.
Какие результаты я получу после анализа линейной регрессии в Excel?
После выполнения анализа линейной регрессии в Excel вы получите несколько важных показателей. Включают в себя коэффициенты регрессии, стандартные ошибки, значения t-статистики и p-значения, которые помогут оценить значимость модели и каждого из параметров. Также будет построен график, отображающий зависимость между переменными, и расчет остаточной суммы квадратов, что помогает определить, насколько хорошо модель объясняет данные.
Можно ли использовать линейную регрессию в Excel для прогнозирования?
Да, линейная регрессия в Excel часто используется для прогнозирования. После построения модели регрессии, можно использовать полученные коэффициенты для предсказания значений зависимой переменной (Y) при изменении независимой переменной (X). Для этого достаточно ввести новые значения X в соответствующие ячейки, и Excel автоматически вычислит прогнозируемые значения Y. Это может быть полезно для различных задач, таких как финансовое планирование или прогнозирование продаж.