Python предоставляет широкий набор инструментов для автоматизации работы с веб-сайтами. Основные библиотеки – requests для отправки HTTP-запросов и BeautifulSoup для парсинга HTML – позволяют извлекать данные, обрабатывать формы и взаимодействовать с API сайтов.
Для работы с современными веб-ресурсами важно учитывать структуру страниц и формат данных. Например, JSON чаще используется в API, тогда как статические страницы требуют анализа DOM. Использование правильного подхода к каждому типу данных ускоряет обработку и снижает риск ошибок.
Авторизация и работа с сессиями на сайтах требует хранения и передачи куки и заголовков. Библиотека requests.Session() позволяет поддерживать соединение между запросами, что особенно важно при авторизованном доступе или при скачивании последовательности файлов.
Обработка ошибок и управление тайм-аутами снижает вероятность зависаний и блокировок со стороны серверов. Настройка параметров запроса, таких как timeout и retry, помогает сделать взаимодействие с сайтом стабильным и предсказуемым.
Установка и настройка библиотеки requests для работы с веб-запросами
Библиотека requests используется для отправки HTTP-запросов и получения ответов от веб-серверов. Установку выполняют через команду pip install requests. Для проектов с зависимостями рекомендуется использовать виртуальное окружение venv, чтобы изолировать библиотеки и избежать конфликтов версий.
После установки важно проверить версию библиотеки командой python -m pip show requests, чтобы убедиться в совместимости с вашим Python-окружением. Requests поддерживает Python 3.7 и выше, а последние обновления включают улучшенную обработку тайм-аутов и перенаправлений.
Настройка библиотеки включает установку заголовков по умолчанию через словарь headers, управление куки через requests.Session() и настройку тайм-аутов для предотвращения зависаний при медленном соединении. Например, requests.get(url, headers=headers, timeout=10) устанавливает максимальное время ожидания ответа сервера в 10 секунд.
Для логирования запросов и ответов можно использовать встроенный модуль logging, что помогает отслеживать коды состояния, время ответа и заголовки. Это особенно полезно при работе с API и автоматизированной обработке больших объемов данных.
Отправка GET и POST запросов к веб-страницам

Метод GET используется для получения данных с сервера. Запрос формируется через requests.get(url, params=params, headers=headers), где params передает параметры строки запроса, а headers задает пользовательские заголовки. Ответ хранится в объекте Response, доступ к содержимому которого осуществляется через response.text для HTML и response.json() для JSON.
Метод POST отправляет данные на сервер, например, при заполнении форм или вызове API. Для передачи используют data или json: requests.post(url, data=data, json=json, headers=headers). Использование json автоматически задает заголовок Content-Type: application/json, что важно для большинства REST API.
При работе с обоими методами рекомендуется обрабатывать коды состояния через response.status_code и использовать timeout для предотвращения зависаний. Для многократных запросов удобнее применять requests.Session(), что сохраняет куки и ускоряет повторные соединения.
Дополнительно следует учитывать лимиты серверов и правила API, например, ограничение числа запросов в минуту. Применение time.sleep() между запросами помогает избежать блокировок и поддерживать стабильное взаимодействие.
Обработка и парсинг HTML с помощью BeautifulSoup
Для анализа HTML-страниц используют библиотеку BeautifulSoup, которая позволяет извлекать данные из структуры DOM. Установку выполняют через pip install beautifulsoup4, совместно с парсером lxml или встроенным html.parser для ускорения обработки.
Создание объекта BeautifulSoup выполняется так: soup = BeautifulSoup(response.text, ‘lxml’). После этого можно использовать методы find(), find_all() и CSS-селекторы через select() для поиска тегов, классов и идентификаторов.
Для получения текста внутри тегов применяется tag.get_text(strip=True), что удаляет лишние пробелы и переносы строк. Атрибуты элементов извлекаются через tag[‘атрибут’], например, tag[‘href’] для ссылок. Для массовой обработки удобно использовать списковые включения и циклы.
При работе с динамическим контентом, который формируется JavaScript, BeautifulSoup обрабатывает только исходный HTML. В таких случаях рекомендуется предварительно получать страницу через selenium или API, а затем применять парсинг для извлечения данных.
Работа с API сайтов и получение данных в формате JSON
Для взаимодействия с API используют HTTP-запросы через библиотеку requests. GET-запросы позволяют получать данные: response = requests.get(api_url, headers=headers, params=params). Параметры params формируют строку запроса, а headers задают ключи авторизации или токены.
Ответ API чаще всего приходит в формате JSON. Для его обработки используют метод response.json(), который преобразует данные в словари и списки Python. Например, data = response.json() позволяет обращаться к элементам через ключи: data[‘results’][0][‘name’].
POST-запросы применяются для отправки данных на сервер, например, при создании записи через API: requests.post(api_url, json=payload, headers=headers). Использование параметра json автоматически задает заголовок Content-Type: application/json.
Для стабильного взаимодействия важно проверять response.status_code и обрабатывать ошибки, такие как 429 (слишком много запросов) или 500 (ошибка сервера). При частых запросах применяют задержки между вызовами через time.sleep() или библиотеку ratelimit для соблюдения лимитов API.
Использование сессий и куки для авторизации на сайтах

Для работы с авторизованными разделами сайта используют объект requests.Session(), который сохраняет куки и заголовки между запросами. Это позволяет выполнять последовательные действия без повторной авторизации.
Пример использования сессии:
- Создание сессии: session = requests.Session()
- Установка заголовков: session.headers.update({‘User-Agent’: ‘Mozilla/5.0’})
- Отправка POST-запроса для авторизации: session.post(login_url, data=payload)
- Доступ к защищенным страницам через session.get(protected_url)
Куки можно просматривать и модифицировать через session.cookies. Для добавления новой куки используется session.cookies.set(‘имя’, ‘значение’). Это позволяет обходить ограничения некоторых сайтов, требующих сохранения состояния между запросами.
При работе с авторизацией важно учитывать:
- Срок жизни куки: устаревшие значения приведут к ошибкам доступа.
- Использование HTTPS: передача данных без шифрования небезопасна.
- Обновление токенов CSRF или сессионных ключей, если сайт их требует для POST-запросов.
Загрузка файлов и изображений через Python

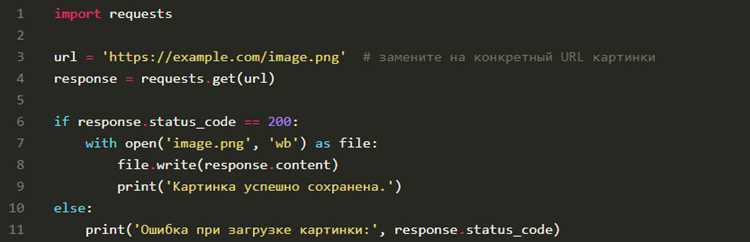
Для скачивания файлов с веб-сайтов используют метод requests.get() с параметром stream=True, что позволяет получать данные частями и экономить память при больших файлах. Пример: response = requests.get(url, stream=True).
Запись данных на диск выполняется циклом:
with open('имя_файла', 'wb') as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
Для скачивания изображений удобно проверять заголовок Content-Type, чтобы убедиться, что получен корректный формат: if ‘image’ in response.headers[‘Content-Type’]. Это позволяет фильтровать нежелательные файлы.
При работе с защищенными ресурсами используют сессии и куки, передавая их в запросы: session.get(url, headers=headers). Для сайтов с ограничением скорости рекомендуется добавлять паузы между запросами через time.sleep(), чтобы избежать блокировок.
Обработка ошибок и управление тайм-аутами при взаимодействии с сайтами
При работе с веб-запросами важно контролировать ошибки и задержки, чтобы скрипт не зависал и корректно обрабатывал непредвиденные ситуации. Тайм-ауты задаются параметром timeout в функциях requests.get() и requests.post(), например: requests.get(url, timeout=10) – ожидание ответа сервера не более 10 секунд.
Обработка ошибок выполняется через блоки try-except. Основные исключения:
| Исключение | Описание |
|---|---|
| requests.exceptions.Timeout | Превышено время ожидания ответа сервера |
| requests.exceptions.ConnectionError | Ошибка соединения с сервером |
| requests.exceptions.HTTPError | Получен код ошибки HTTP (4xx или 5xx) |
| requests.exceptions.RequestException | Общее исключение для всех типов ошибок запросов |
Для стабильной работы при повторяющихся ошибках применяют повторные попытки запросов с задержкой:
for _ in range(3):
try:
response = requests.get(url, timeout=10)
response.raise_for_status()
break
except requests.exceptions.RequestException as e:
print(f"Ошибка запроса: {e}")
time.sleep(5)
Комбинация тайм-аутов, обработки исключений и контроля кода ответа сервера обеспечивает предсказуемое и безопасное взаимодействие с веб-сайтами, предотвращая зависания и блокировки.
Вопрос-ответ:
Как отправлять GET-запросы к сайту с помощью Python и получать данные?
Для отправки GET-запросов используют библиотеку requests. Создайте запрос через requests.get(url, params=params, headers=headers). Параметр params позволяет передавать данные в строке запроса, а headers — задавать заголовки. Ответ сохраняется в объекте Response, доступ к тексту страницы осуществляется через response.text, а для JSON — через response.json().
Как обрабатывать HTML-страницы и извлекать данные с помощью Python?
Для анализа HTML используют BeautifulSoup. Создайте объект парсера: soup = BeautifulSoup(response.text, ‘lxml’). Для поиска элементов применяются методы find(), find_all() и select(). Текст тегов получают через tag.get_text(strip=True), атрибуты — через tag[‘атрибут’]. Это позволяет извлекать ссылки, заголовки, таблицы и другие элементы страницы.
Как работать с API сайтов и получать данные в формате JSON?
API сайтов возвращают данные в формате JSON, который удобно обрабатывать в Python как словари и списки. GET-запрос выполняется через requests.get(url, headers=headers, params=params). После получения ответа используйте response.json() для преобразования данных в структуру Python. Для POST-запросов применяют requests.post(url, json=payload, headers=headers), где payload содержит отправляемые данные.
Как использовать сессии и куки для авторизации на сайтах?
Создайте объект сессии через session = requests.Session(). В сессии можно задавать заголовки и передавать данные авторизации. Например, session.post(login_url, data=payload) выполняет вход на сайт. После этого защищенные страницы открываются через session.get(protected_url). Куки можно просматривать через session.cookies и при необходимости изменять или добавлять новые значения.
Как скачивать файлы и изображения с сайтов с помощью Python?
Для загрузки файлов используют requests.get() с параметром stream=True. Данные записываются на диск частями через цикл: for chunk in response.iter_content(chunk_size=1024): f.write(chunk). Для изображений удобно проверять заголовок Content-Type, чтобы убедиться в корректности формата. При работе с защищенными ресурсами передавайте сессию или куки в запросе, а при частых скачиваниях используйте паузы между запросами для предотвращения блокировок.
Как правильно настроить тайм-ауты и обработку ошибок при работе с веб-запросами в Python?
При взаимодействии с веб-сайтами важно использовать параметр timeout в функциях requests.get() и requests.post(), чтобы ограничить время ожидания ответа сервера. Для перехвата возможных ошибок применяют блоки try-except, обрабатывая исключения, такие как requests.exceptions.Timeout для превышения времени ожидания, requests.exceptions.ConnectionError для проблем с соединением и requests.exceptions.HTTPError для ошибок HTTP-кода. Рекомендуется также проверять response.status_code после запроса и при необходимости повторять попытки с небольшими задержками через time.sleep(), чтобы предотвратить блокировки со стороны сайта и корректно завершать работу скрипта при недоступности сервера.