В Bash обрезка строк позволяет получать конкретные части текста без использования внешних языков программирования. Операции с подстроками ускоряют обработку данных в скриптах, особенно при работе с логами, конфигурационными файлами и результатами команд.
Синтаксис ${variable:start:length} позволяет извлекать подстроку из строки переменной по индексу начала и длине. Например, text=»abcdef» и ${text:2:3} вернут «cde». Это удобно для динамического выделения данных без вызова дополнительных утилит.
Удаление префиксов и суффиксов с помощью ${variable#pattern} и ${variable%pattern} упрощает очистку имен файлов и путей. Комбинируя символы # и %, можно удалять как минимальное совпадение, так и максимально возможное, что полезно для обработки строк с повторяющимися разделителями.
Команды cut, awk и sed обеспечивают гибкую обрезку строк на основе символов, разделителей или регулярных выражений. Cut подходит для простого разделения по столбцам, awk – для выборки полей с условием, а sed позволяет изменять строки на лету без сохранения во временные переменные.
Правильный выбор метода обрезки зависит от объема данных и задачи. Простые подстроки используют встроенные средства Bash, сложные шаблоны или фильтрацию выполняют через утилиты, что снижает риск ошибок и ускоряет выполнение скриптов.
Использование синтаксиса ${variable:start:length} для подстрок
Синтаксис ${variable:start:length} позволяет извлекать подстроку из значения переменной без вызова внешних команд. Параметр start указывает индекс первого символа, начиная с нуля, а length определяет количество символов для извлечения. Если length опущен, возвращается вся оставшаяся часть строки.
Пример: text=»server_log_2025″. Команда ${text:7:3} вернет «log», что удобно для выделения частей имени файла по позиции. Отрицательные индексы позволяют считать символы с конца строки: ${text: -4:4} вернет «2025».
Для динамического извлечения подстрок можно использовать переменные в параметрах: start=$(( ${#prefix} + 1 )); ${text:start:5} извлечет 5 символов после длины префикса. Такой подход снижает необходимость ручного подсчета индексов.
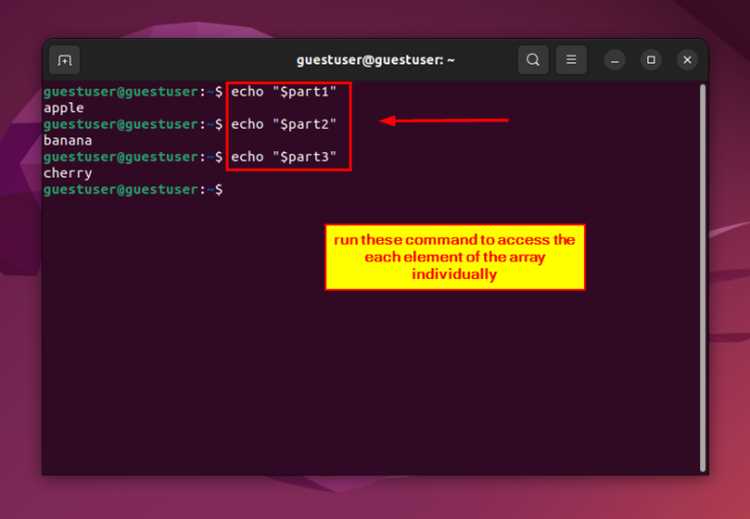
При обработке массивов файлов или строк через цикл for синтаксис ${variable:start:length} позволяет сразу выделять ключевые части имени или содержимого без создания дополнительных функций. Это ускоряет скрипты и упрощает поддержку.
Удаление префиксов и суффиксов с помощью ${variable#pattern} и ${variable%pattern}
Конструкция ${variable#pattern} удаляет кратчайшее совпадение шаблона в начале строки, а ${variable##pattern} – самое длинное. Аналогично, ${variable%pattern} удаляет кратчайшее совпадение в конце строки, а ${variable%%pattern} – самое длинное.
Примеры использования:
- filename=»backup_2025.tar.gz»
${filename#backup_} вернет «2025.tar.gz» – удален префикс «backup_». - ${filename##*_} вернет «gz» – удалено все до последнего символа «_».
- ${filename%.tar.gz} вернет «backup_2025» – удален суффикс «.tar.gz».
- ${filename%%.*} вернет «backup_2025» – удалено все после первого «.».
Практические рекомендации:
- Использовать # и ## для очистки префиксов при обработке имен файлов и путей.
- Применять % и %% для удаления расширений или лишних суффиксов.
- Комбинировать с переменными и циклами для массовой обработки списков файлов без вызова внешних утилит.
- С шаблонами можно использовать символы подстановки, например *, для гибкой фильтрации частей строк.
Обрезка строк с помощью команды cut по символам и разделителям
Команда cut позволяет извлекать части строки по номеру символа или разделителю без использования циклов и дополнительных утилит. Для выбора символов применяется опция -c, для работы с разделителями – -d и -f.
Примеры:
- echo «abcdef» | cut -c2-4 вернет «bcd» – извлечение символов со второго по четвертый.
- echo «user:1001:staff» | cut -d»:» -f1 вернет «user» – выбор первого поля по разделителю «:».
- echo «log_2025_error.log» | cut -d»_» -f2 вернет «2025» – извлечение второго сегмента строки.
- Комбинация диапазонов: cut -c1-3,5-6 возвращает символы 1–3 и 5–6 одновременно.
Рекомендации:
- Использовать -c для фиксированных позиций символов в коротких строках.
- Применять -d и -f для разделенных данных, например CSV или логов.
- Комбинировать с конвейерами (|) для последовательной обработки строк в скриптах.
Применение команды awk для извлечения частей строк

Примеры использования:
- echo «user 1001 staff» | awk ‘{print $2}’ вернет «1001» – выбор второго поля.
- echo «log_2025_error.log» | awk -F»_» ‘{print $2}’ вернет «2025» – указание пользовательского разделителя.
- Комбинация полей: awk ‘{print $1 «-» $3}’ формирует новые строки из первого и третьего поля с соединителем «-«.
Рекомендации:
- Использовать -F для разделителей, отличных от пробела, включая двоеточие, точку или символ подчеркивания.
- Применять условия для фильтрации строк по значению поля.
- Сочетать с циклом for или конвейером для пакетной обработки файлов.
Использование команды sed для удаления или замены частей строки
Команда sed позволяет изменять строки на лету с использованием регулярных выражений. Для удаления используется пустая замена s/шаблон//, для замены – s/шаблон/новый_текст/.
Примеры:
- echo «backup_2025.tar.gz» | sed ‘s/backup_//’ вернет «2025.tar.gz» – удаление префикса.
- echo «log_error.log» | sed ‘s/\.log$//’ вернет «log_error» – удаление суффикса с помощью символа конца строки.
- echo «user123» | sed ‘s/[0-9]//g’ вернет «user» – удаление всех цифр из строки.
- echo «file_old.txt» | sed ‘s/_old/_new/’ вернет «file_new.txt» – замена части строки.
Рекомендации:
- Использовать $ для обозначения конца строки при удалении суффиксов.
- Применять флаг g для глобальной замены всех совпадений в строке.
- Комбинировать sed с конвейерами и циклами для пакетной обработки файлов и динамической замены данных.
- Тестировать регулярные выражения на отдельных примерах перед массовым применением в скриптах.
Комбинирование нескольких методов для сложной обработки строк
Для извлечения и преобразования сложных строк в Bash часто используют сочетание встроенных средств и внешних утилит. Например, ${variable:start:length} совместно с sed позволяет выделять подстроку и одновременно удалять нежелательные символы.
Примеры:
- filename=»backup_2025_error.log»
${filename:7} | sed ‘s/_error//’ вернет «2025.log» – сначала выделяется часть строки с позиции 7, затем удаляется сегмент «_error». - Комбинация cut и awk: echo «user:1001:staff» | cut -d»:» -f2 | awk ‘{print «ID-» $1}’ возвращает «ID-1001» – сначала выбирается поле, затем добавляется префикс.
- Использование sed и awk для очистки и фильтрации строк логов: awk ‘{print $3}’ logfile | sed ‘s/error/fail/’.
Рекомендации:
- Сначала применять встроенные подстрочные операции Bash для минимизации вызовов внешних программ.
- Для сложных шаблонов использовать sed и awk, комбинируя их с конвейерами.
- Разбивать обработку на несколько последовательных шагов, чтобы облегчить отладку и поддержку скриптов.
- Тестировать каждый этап обработки на отдельных примерах до применения к реальным файлам или массивам данных.
Вопрос-ответ:
Как извлечь конкретные символы из строки в Bash без использования внешних утилит?
В Bash можно использовать синтаксис ${variable:start:length}. Например, если text=»abcdef», то ${text:2:3} вернет «cde» — символы со второго по четвертый. Если указать отрицательный индекс, например ${text: -3:2}, то отсчет будет с конца строки.
Чем отличается удаление префикса с помощью ${variable#pattern} и ${variable##pattern}?
Конструкция ${variable#pattern} удаляет кратчайшее совпадение шаблона в начале строки, а ${variable##pattern} — самое длинное. Например, filename=»backup_2025.tar.gz»: ${filename#backup_} вернет «2025.tar.gz», а ${filename##*_} вернет «gz», удалив все до последнего символа «_».
Как использовать cut для выделения поля по разделителю в строке?
Команда cut с опциями -d и -f позволяет выбирать сегменты строки по разделителю. Например, echo «user:1001:staff» | cut -d»:» -f2 вернет «1001». Для выбора нескольких полей можно использовать диапазон: -f1,3 выберет первое и третье поле.
Когда стоит применять awk вместо cut для обработки строк?
awk подходит для более сложной фильтрации и форматирования. С его помощью можно выбирать поля, проверять условия, добавлять текст или вычислять значения. Например, awk -F»:» ‘$3==»staff»{print $1}’ /etc/passwd выведет всех пользователей с группой staff, чего нельзя сделать с помощью простого cut без дополнительной обработки.
Как комбинировать несколько методов для обработки строки с префиксом, суффиксом и разделителем?
Можно использовать последовательность инструментов. Например, filename=»backup_2025_error.log»: сначала выделяем подстроку с позиции 7 с помощью ${filename:7}, затем удаляем сегмент «_error» через sed: ${filename:7} | sed ‘s/_error//’. Для сложных данных часто комбинируют cut, awk и sed через конвейеры, чтобы последовательно извлекать, фильтровать и заменять части строк.