Тег <meta name=»robots»> управляет поведением поисковых систем при обходе страниц. Он размещается внутри раздела <head> и передаёт инструкцию роботам о том, можно ли индексировать страницу и переходить по ссылкам.
Параметр content=»index, follow» сообщает поисковику, что страницу следует включить в индекс и учитывать все ссылки на ней. Этот вариант используется по умолчанию, но его явное указание помогает избежать неоднозначностей при анализе кода сайта.
Правильное применение метатега важно для контроля за индексацией технических страниц, дублей и контента, не предназначенного для выдачи. Например, для скрытия внутренних страниц используют noindex или nofollow, комбинируя их в зависимости от задач.
При работе с meta name=»robots» важно проверять, не противоречат ли его инструкции правилам в файле robots.txt. Несогласованность между ними может привести к частичной потере видимости сайта в поиске или к пропуску нужных ссылок.
Что обозначает атрибут meta name=»robots» в HTML

Атрибут meta name=»robots» применяется для управления действиями поисковых систем на уровне отдельной страницы. Он сообщает роботам, можно ли индексировать содержимое и переходить по ссылкам, расположенным внутри документа.
Элемент размещается в разделе <head> и имеет синтаксис: <meta name=»robots» content=»index, follow»>. Атрибут name указывает, что инструкция адресована поисковым роботам, а параметр content определяет набор разрешений или ограничений.
Тег поддерживает комбинации значений: index – разрешает индексацию, noindex – запрещает, follow – разрешает переход по ссылкам, nofollow – блокирует их анализ. Это даёт возможность гибко настраивать видимость страниц без изменения конфигурации сервера или файла robots.txt.
Для разных поисковых систем допускается использование специфичных метатегов, например meta name=»googlebot» или meta name=»yandex». Это позволяет задавать индивидуальные правила обхода в зависимости от особенностей алгоритмов конкретного робота.
Как работает параметр content=»index follow» и зачем он нужен
Параметр content=»index, follow» определяет поведение поисковых роботов при анализе страницы. Ключ index разрешает включение страницы в поисковый индекс, а follow сообщает системе, что ссылки внутри документа можно использовать для перехода к другим ресурсам.
Если эти значения заданы, поисковый робот не только сохраняет страницу в базе, но и продолжает обход по всем найденным ссылкам. Это способствует корректному построению структуры сайта в индексе и улучшает распределение ссылочного веса между страницами.
Когда тег отсутствует, большинство поисковых систем применяют режим index, follow по умолчанию. Однако явное указание параметров полезно при программной генерации HTML, особенно в шаблонах CMS или динамических страницах, где ошибки в настройках могут привести к потере индексации.
Использовать index, follow рекомендуется на всех страницах, которые должны участвовать в поисковом ранжировании и содержат ссылки на важные разделы сайта. Для закрытых разделов, тестовых или дублирующих страниц следует применять противоположные комбинации – noindex и nofollow.
Различия между значениями index, noindex, follow и nofollow

Значения параметра content в теге <meta name=»robots»> определяют, как поисковик будет обрабатывать страницу и её ссылки. Каждое значение выполняет конкретную функцию и влияет на видимость ресурса в выдаче.
index – разрешает добавление страницы в индекс. Контент доступен для поиска, заголовки и фрагменты могут отображаться в результатах. Этот вариант подходит для всех публичных материалов сайта.
noindex – запрещает индексацию содержимого. Страница остаётся доступной пользователям, но не отображается в поиске. Такой параметр используют для административных разделов, корзины, фильтров или страниц с повторяющимся контентом.
follow – указывает роботу, что ссылки на странице можно обходить. Это позволяет поисковым системам находить новые URL и формировать карту сайта без дополнительных файлов.
nofollow – запрещает переход по ссылкам и передачу ссылочного веса. Его применяют для комментариев, рекламных блоков или внешних ресурсов, к которым не требуется доверие.
Комбинации этих значений задают точную стратегию индексации. Например, noindex, follow скрывает саму страницу, но сохраняет активность ссылок, а index, nofollow делает наоборот – страница видна, но ссылки игнорируются.
Как тег robots влияет на индексацию страниц поисковыми системами
Тег <meta name=»robots»> управляет доступом поисковых систем к содержимому страницы. Его значения напрямую определяют, попадёт ли документ в индекс и будут ли учтены ссылки, размещённые на нём.
Если используется параметр index, поисковый робот сохраняет страницу в своей базе и включает её в результаты поиска. При указании noindex содержимое остаётся проиндексированным локально, но не отображается в выдаче, даже если на страницу ведут внешние ссылки.
Инструкция follow позволяет роботу переходить по ссылкам и находить новые ресурсы, поддерживая связность структуры сайта. В сочетании с nofollow поисковик прекращает передачу ссылочного веса и не использует ссылки для обхода.
Тег robots обрабатывается на этапе сканирования HTML-кода. Если на странице присутствует противоречие между этим тегом и правилами в robots.txt, приоритет получает файл robots.txt. Поэтому при настройке рекомендуется проверять согласованность обоих источников.
Для контроля индексации стоит применять robots-теги на уровне шаблонов или CMS, чтобы исключить появление технических страниц, параметрических URL и фильтров в поисковой выдаче.
Где размещать meta name=»robots» в структуре HTML-документа
Тег <meta name=»robots»> должен находиться внутри раздела <head> до загрузки основного содержимого страницы. Поисковый робот считывает инструкции только в этом блоке, поэтому размещение в теле документа делает тег нерабочим.
Оптимальная структура включает размещение метатега сразу после <meta charset> и перед <title> или другими метаданными. Такой порядок гарантирует корректную обработку инструкции до начала анализа контента.
Пример корректного кода:
<head>
<meta charset=»UTF-8″>
<meta name=»robots» content=»index, follow»>
<title>Пример страницы</title>
</head>
При генерации страниц через CMS или фреймворки стоит убедиться, что тег вставляется в шаблон именно в раздел <head>. Размещение через плагины или скрипты, выполняемые после загрузки страницы, не гарантирует корректного восприятия поисковыми системами.
Если на сайте используются разные правила для отдельных разделов, можно задавать теги robots на уровне шаблонов. Это позволяет централизованно управлять индексацией без изменения HTML вручную.
Примеры правильного и ошибочного использования тега robots
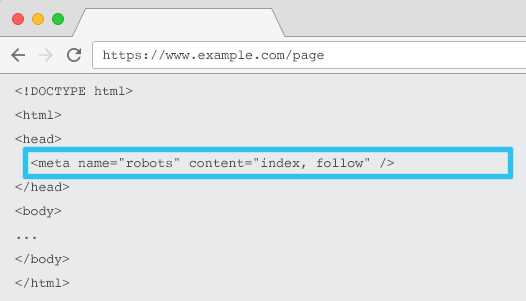
Корректное применение тега <meta name=»robots»> позволяет контролировать индексацию и обход ссылок. Ошибки в синтаксисе или размещении приводят к нежелательной видимости страниц в поиске.
| Сценарий | Пример кода | Описание |
|---|---|---|
| Правильное использование для индексации и обхода ссылок | <meta name=»robots» content=»index, follow»> | Страница включается в индекс, все ссылки анализируются поисковиком. Размещается в <head> перед контентом. |
| Закрытие административной страницы | <meta name=»robots» content=»noindex, nofollow»> | Страница не индексируется, ссылки не учитываются. Подходит для корзины или панели управления. |
| Ошибка: тег в теле документа | <body>…<meta name=»robots» content=»noindex»>…</body> | Поисковики часто игнорируют метатег, так как он должен находиться в <head>. |
| Ошибка: опечатка в имени атрибута | <meta name=»robot» content=»index, follow»> | Роботы не распознают тег, индексация и обход ссылок проходят по умолчанию. |
| Использование специфичного робота | <meta name=»googlebot» content=»noindex, follow»> | Страница скрыта только от Google, ссылки остаются доступными для обхода. Другие поисковики игнорируют инструкцию. |
Регулярная проверка HTML и тестирование через инструменты типа Google Search Console помогает выявлять ошибки в тегах robots и корректировать стратегию индексации.
Как проверить, видят ли поисковые системы meta name=»robots»
Для проверки восприятия тега <meta name=»robots»> поисковыми системами используют несколько методов, позволяющих убедиться, что инструкции корректно обрабатываются.
- Google Search Console: Используйте инструмент «Проверка URL», чтобы увидеть, как Google видит страницу и какие метатеги распознаются.
- Yandex.Webmaster: Раздел «Проверка страницы» показывает, есть ли тег robots и его текущее значение для обхода и индексации.
- Просмотр исходного кода: Убедитесь, что тег находится в <head> и синтаксис корректен:
<meta name="robots" content="index, follow"> - Инструменты для веб-разработчиков: Расширения браузеров или онлайн-сервисы типа SEO Site Checkup выявляют ошибки и опечатки в метатегах.
Регулярная проверка помогает избежать ситуаций, когда страница не индексируется или ссылки игнорируются из-за неправильного размещения или синтаксиса метатега.
Вопрос-ответ:
Что делает тег <meta name=»robots» content=»index, follow»> и зачем он нужен?
Тег <meta name=»robots»> управляет поведением поисковых роботов на конкретной странице. Значение index разрешает включение страницы в индекс, а follow позволяет обходить ссылки на странице и учитывать их для поиска. Этот тег помогает контролировать видимость страниц и распространение ссылочного веса внутри сайта.
Какая разница между значениями index и noindex в meta robots?
Значение index указывает поисковикам добавлять страницу в индекс, а noindex запрещает индексацию. Если страница имеет noindex, её содержимое не появится в поисковой выдаче, даже если на неё ведут внешние ссылки. Правильное применение этих значений помогает скрывать технические или дублирующие страницы.
Можно ли использовать meta name=»robots» для отдельных поисковых систем?
Да, существуют специальные версии тега, например <meta name=»googlebot»> или <meta name=»yandex»>, которые применяются только к указанной системе. Это позволяет задавать уникальные правила для разных роботов: одни страницы могут индексироваться Google, но быть скрыты от Yandex, или наоборот.
Как проверить, что поисковые системы видят тег robots и выполняют его инструкции?
Проверку проводят через инструменты типа Google Search Console и Yandex.Webmaster, используя функции «Проверка URL» или «Анализ страницы». Также можно просмотреть исходный код страницы, убедившись, что тег находится в разделе <head> и синтаксис корректен. Онлайн-сервисы и расширения для SEO позволяют выявить ошибки или опечатки в метатеге, которые мешают его работе.