Apache Kafka – это распределённая платформа для обработки потоков данных в реальном времени, способная обрабатывать миллионы сообщений в секунду. Она организует данные в топики и разделы, позволяя масштабировать хранение и обработку информации на нескольких серверах одновременно.
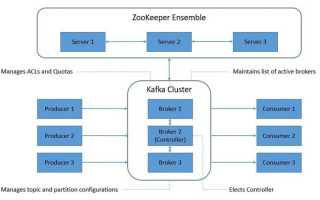
Zookeeper выполняет роль координатора для Kafka. Он отслеживает состояние брокеров, управляет лидерами разделов и хранит метаданные кластера. Без Zookeeper синхронизация между брокерами становится сложной и ненадёжной, особенно при добавлении или удалении узлов.
Kafka использует Zookeeper для выбора лидера раздела и отслеживания доступных реплик. Это обеспечивает устойчивость к сбоям: если брокер выходит из строя, Zookeeper инициирует выбор нового лидера, предотвращая потерю данных и нарушений в обработке сообщений.
Для развертывания кластера Kafka важно правильно настроить Zookeeper. Рекомендуется минимум три узла Zookeeper для обеспечения отказоустойчивости и согласованности. Kafka-брокеры должны быть настроены на автоматическое повторное подключение к Zookeeper, чтобы минимизировать время простоя при сбоях.
Взаимодействие Kafka и Zookeeper можно визуализировать как архитектуру с координатором и исполнителями: Zookeeper управляет состоянием и распределением задач, а Kafka обеспечивает высокоскоростную передачу сообщений и их хранение с гарантией последовательности и репликации.
Роль Zookeeper в управлении кластерами Kafka
Zookeeper выполняет функцию координации и управления состоянием кластера Kafka. Он хранит метаданные брокеров, информацию о топиках, партициях и лидерах партиций. Благодаря этому Kafka может автоматически переназначать лидеров при сбое брокера и поддерживать согласованное состояние кластера.
Zookeeper следит за доступностью брокеров и уведомляет Kafka о подключении или отключении узлов. Это обеспечивает отказоустойчивость и стабильность распределенной системы, минимизируя риск потери данных при сбоях.
Каждый топик в Kafka разбивается на партиции. Zookeeper отслеживает, какой брокер является лидером каждой партиции, и обеспечивает репликацию данных между брокерами. В случае падения лидера Zookeeper инициирует выбор нового лидера из доступных реплик.
Для управления конфигурациями Zookeeper хранит данные в иерархической структуре znodes. Администраторы могут изменять конфигурации брокеров и топиков централизованно, что упрощает масштабирование кластера и добавление новых узлов.
| Функция Zookeeper | Описание |
|---|---|
| Координация брокеров | Следит за состоянием всех брокеров, уведомляет Kafka о подключении и отключении |
| Выбор лидеров партиций | Определяет лидера каждой партиции и обеспечивает автоматическое переключение при сбоях |
| Хранение метаданных | Сохраняет информацию о топиках, партициях и конфигурациях |
| Поддержка репликации | Следит за синхронизацией реплик и целостностью данных |
| Централизованное управление | Позволяет изменять конфигурации кластера без перезапуска брокеров |
Использование Zookeeper снижает сложность администрирования кластера Kafka и обеспечивает высокую надежность распределенной системы. Рекомендуется держать Zookeeper отдельным кластером с минимум тремя узлами для обеспечения консенсуса и отказоустойчивости.
Как Kafka хранит и распределяет сообщения
Kafka хранит данные в виде топиков, каждый из которых делится на несколько партиций. Партиции позволяют распределять нагрузку между брокерами кластера и обеспечивают параллельную обработку сообщений. Каждое сообщение в партиции имеет уникальный смещённый индекс (offset), который фиксирует порядок записи и позволяет потребителям точно определять, какие сообщения были прочитаны.
Сообщения в Kafka записываются последовательно в журналы (log files) на диск. Это обеспечивает высокую скорость записи и возможность повторного чтения сообщений без потери производительности. Для устойчивости данных используется репликация: каждая партиция копируется на несколько брокеров. Один брокер назначается лидером партиции, остальные – репликами. Лидер обрабатывает все операции записи и чтения, реплики синхронизируются с лидером.
Распределение сообщений между брокерами и партициями управляется продюсером. По умолчанию продюсер может использовать ключ сообщения для определения конкретной партиции. Если ключ не задан, Kafka распределяет сообщения равномерно между партициями. Такой подход минимизирует перегрузку отдельных брокеров и обеспечивает балансировку нагрузки.
Потребители получают сообщения из партиций последовательно, используя offset. Kafka хранит состояние последнего прочитанного сообщения для каждого потребителя в специальном внутреннем топике __consumer_offsets. Это позволяет легко масштабировать группы потребителей и обеспечивать точное повторное чтение сообщений при сбоях.
Для оптимизации хранения Kafka поддерживает настройку времени хранения сообщений (retention time) или максимального объема данных в партиции. Старые сообщения автоматически удаляются или архивируются, что позволяет контролировать использование дискового пространства без вмешательства администратора.
Механизм репликации данных в Kafka
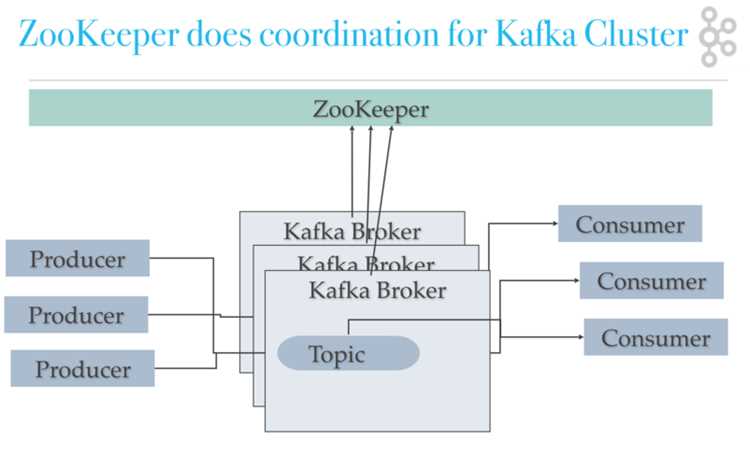
В Kafka репликация данных обеспечивает отказоустойчивость и согласованность сообщений между брокерами. Каждый топик разбивается на партиции, и каждая партиция имеет один лидер и один или несколько реплик (followers).
Лидер отвечает за все операции записи и чтения данных для своей партиции. Реплики синхронизируются с лидером, получая новые сообщения асинхронно. Такой подход позволяет распределять нагрузку и сохранять данные при сбое отдельных брокеров.
Основные элементы механизма репликации:
- ISR (In-Sync Replicas) – список реплик, которые полностью синхронизированы с лидером. Только данные из ISR считаются подтвержденными.
- acks – параметр продюсера, определяющий, сколько реплик должно подтвердить запись. Возможные значения: 0, 1, all. Значение all гарантирует, что сообщение записано на все реплики из ISR.
- Контроль лидера – Zookeeper следит за состоянием брокеров. Если лидер недоступен, один из реплик из ISR автоматически становится новым лидером.
Рекомендации при настройке репликации:
- Минимум три брокера для критически важных данных, чтобы обеспечить репликацию и отказоустойчивость.
- Использовать replication.factor ≥ 2, чтобы каждая партиция имела резервные копии.
- Настроить продюсерские acks=all для подтверждения записи на всех синхронизированных репликах.
- Регулярно проверять состояние ISR через Kafka API или инструменты мониторинга, чтобы выявлять отстающие реплики.
Такой механизм позволяет Kafka сохранять целостность данных даже при выходе отдельных брокеров из строя, обеспечивая стабильность потоковой передачи сообщений и минимальное время простоя.
Как Zookeeper отслеживает состояние брокеров
Zookeeper хранит актуальную информацию о каждом брокере Kafka в виде узлов (znodes) в своей иерархической структуре. Каждый брокер регистрируется в Zookeeper при запуске, создавая ephemeral znode, который автоматически удаляется при потере соединения с Zookeeper.
Механизм отслеживания состояния брокеров работает следующим образом:
- Регистрация брокеров: при старте брокер отправляет в Zookeeper информацию о своём ID, адресе и портах, создавая ephemeral znode в пути
/brokers/ids/[brokerId]. - Периодические heartbeat: брокеры отправляют heartbeat-запросы, чтобы поддерживать znode активным. Отсутствие heartbeat приводит к удалению znode.
- Мониторинг директорий: Kafka контроллер следит за изменениями в
/brokers/idsи получает уведомления о добавлении или удалении брокеров. - Обнаружение сбоев: если znode брокера исчезает, контроллер считает брокера недоступным и инициирует перераспределение партиций и выбор нового лидера для каждой партиции, где этот брокер был лидером.
Для надежности рекомендуется использовать кластер Zookeeper из 3–5 узлов. Это предотвращает ложные срабатывания при кратковременных разрывах соединения и обеспечивает согласованное состояние брокеров для всего кластера Kafka.
Также важно контролировать таймауты сессий брокеров (zookeeper.session.timeout.ms) и интервал heartbeat (zookeeper.connection.timeout.ms), чтобы балансировать между быстрой реакцией на сбои и предотвращением лишних перераспределений.
Принцип работы продюсеров и консьюмеров Kafka

Продюсер в Kafka отвечает за отправку сообщений в определённые топики. Каждое сообщение получает ключ, который может использоваться для определения партиции внутри топика. Если ключ отсутствует, Kafka распределяет сообщения по партициям с помощью алгоритма round-robin, обеспечивая балансировку нагрузки между брокерами.
Продюсер может настроить параметры acks и retries. Параметр acks определяет, сколько брокеров должны подтвердить запись сообщения перед возвратом успешного статуса. Значение 0 означает отсутствие подтверждений, 1 – подтверждение от лидера партиции, all – подтверждение от всех реплик. Параметр retries задаёт количество попыток повторной отправки при ошибках.
Консьюмер читает сообщения из топиков и группируется в consumer group. Каждой партиции назначается один консьюмер в группе, что исключает дублирующее чтение сообщений и позволяет масштабировать обработку. Консьюмеры используют offset для отслеживания позиции в партиции. Offset может управляться автоматически или вручную, обеспечивая точный контроль над тем, какие сообщения обработаны.
Для повышения устойчивости консьюмеры могут использовать heartbeat и session timeout. Heartbeat информирует брокера о том, что консьюмер активен, а session timeout позволяет брокеру переназначить партиции другому консьюмеру при сбое.
Продюсеры и консьюмеры взаимодействуют через брокеры, а Zookeeper следит за метаданными кластера и состоянием брокеров. Это обеспечивает согласованность распределения сообщений и стабильность обработки данных в реальном времени.
Обработка отказов и восстановление брокеров
Kafka использует механизм репликации для обеспечения доступности данных при сбое брокера. Каждый топик разделён на партиции, и каждая партиция имеет один лидер и несколько реплик. Лидер обрабатывает все операции записи и чтения, а реплики синхронизируются с ним.
При падении брокера, который является лидером одной или нескольких партиций, Zookeeper фиксирует недоступность и инициирует выбор нового лидера из числа синхронизированных реплик. Этот процесс обычно занимает миллисекунды, что минимизирует простои.
Для снижения риска потери данных рекомендуется настроить параметр min.insync.replicas, который определяет минимальное количество реплик, подтверждающих запись. Если число доступных реплик меньше указанного, запись отклоняется, что предотвращает потерю данных.
После восстановления брокера он автоматически синхронизирует пропущенные сообщения с текущим лидером соответствующих партиций. В Kafka доступен режим «controlled shutdown», который позволяет корректно завершить работу брокера, передав лидерство другим репликам и уменьшив вероятность расхождений данных.
Для оперативного мониторинга отказов рекомендуется использовать встроенные метрики Kafka и Zookeeper, включая статус брокеров, состояние партиций и задержки репликации. Это позволяет быстро реагировать на сбои и предотвращать накопление проблем.
Настройка взаимодействия Kafka с Zookeeper

Для корректной работы Kafka требуется подключение к Zookeeper, который управляет метаданными кластера. Основной параметр конфигурации находится в файле server.properties брокера Kafka и задается через zookeeper.connect. Значение должно содержать список хостов Zookeeper с портами, например: zookeeper.connect=zk1:2181,zk2:2181,zk3:2181.
Важно, чтобы версии Kafka и Zookeeper были совместимы. Для Kafka 2.x рекомендуется использовать Zookeeper 3.5 или выше. Несоответствие версий может привести к ошибкам регистрации брокеров и сбоям репликации.
При многоброкерной конфигурации каждый брокер должен иметь уникальный broker.id и указывать один и тот же кластер Zookeeper. Это позволяет Zookeeper отслеживать состояние каждого брокера и управлять лидером разделов (partition leader).
Для повышения устойчивости к отказам рекомендуется использовать ensemble из 3–5 узлов Zookeeper. Все брокеры Kafka должны подключаться ко всем узлам ensemble для синхронизации метаданных.
После изменения конфигурации server.properties перезапуск брокеров обязателен. Проверка успешного подключения выполняется через команды Kafka: kafka-topics.sh --list --zookeeper zk1:2181 или через логи брокера, где должно появляться сообщение о регистрации в Zookeeper.
В случае сетевых задержек или отказов узлов Zookeeper стоит настроить параметры zookeeper.session.timeout.ms и zookeeper.connection.timeout.ms для устойчивого взаимодействия брокеров с кластером Zookeeper.
Вопрос-ответ:
Зачем Kafka нужен Zookeeper?
Zookeeper выполняет роль координатора для кластера Kafka. Он хранит информацию о конфигурации брокеров, отслеживает их состояние и распределение партиций между ними. Без Zookeeper Kafka не смогла бы автоматически определять лидеров партиций и корректно управлять репликацией данных.
Как Kafka распределяет сообщения между брокерами?
Сообщения в Kafka распределяются по топикам, которые делятся на партиции. Каждая партиция имеет одного лидера и несколько реплик. Продюсеры отправляют сообщения в партиции по ключу или случайно. Лидер партиции сохраняет сообщения и синхронизирует их с репликами на других брокерах, обеспечивая баланс нагрузки и отказоустойчивость.
Что происходит, когда один из брокеров Kafka выходит из строя?
Если брокер выходит из строя, Zookeeper фиксирует его недоступность. Для партиций, лидер которых находился на этом брокере, автоматически выбирается новый лидер из доступных реплик. Консьюмеры перенаправляются к новому лидеру, что позволяет продолжать обработку сообщений без потери данных.
Какая роль продюсеров и консьюмеров в Kafka?
Продюсеры отправляют сообщения в топики Kafka, выбирая партицию по ключу или случайно. Консьюмеры читают сообщения из партиций и могут объединяться в группы для параллельной обработки. Такой подход позволяет масштабировать обработку данных, управлять нагрузкой и обеспечивать последовательность сообщений для каждой партиции.
Как настроить взаимодействие Kafka с Zookeeper?
Для работы Kafka с Zookeeper необходимо указать адрес Zookeeper в конфигурационном файле Kafka (server.properties). Это позволяет брокерам регистрироваться в кластере и обмениваться информацией о состоянии партиций и реплик. Важно настроить корректные порты, разрешить доступ между узлами и убедиться, что Zookeeper запущен до старта брокеров Kafka.
Как Zookeeper помогает Kafka управлять состоянием брокеров?
Zookeeper выполняет функцию централизованного координационного сервиса для кластера Kafka. Он хранит метаданные о брокерах, топиках и разделах, а также отслеживает доступность каждого брокера. Когда брокер выходит из строя или перестаёт отвечать, Zookeeper уведомляет контроллера Kafka, который назначает лидеров для разделов и распределяет задачи репликации между оставшимися брокерами. Благодаря этому Kafka поддерживает целостность данных и правильное распределение нагрузки без ручного вмешательства. Кроме того, Zookeeper помогает синхронизировать конфигурацию кластера и обеспечивает согласованность информации о топиках и правах доступа клиентов.