Содержание статьи

UTF-8 – это переменно-длиная кодировка символов, которая сохраняет совместимость с ASCII и позволяет представлять все символы Юникода. Каждый символ может занимать от 1 до 4 байт. Символы стандартного ASCII (код 0–127) кодируются одним байтом, а специальные символы, знаки и иероглифы занимают 2–4 байта. Это важно учитывать при обработке текста в разных системах и при работе с файлами, чтобы избежать потери данных.
При сохранении или передаче текста UTF-8 требует проверки порядка байтов. В большинстве современных систем используется порядок «big-endian» для корректной интерпретации многобайтовых символов. Неправильная обработка байтов может приводить к некорректному отображению, например, замене символов на � или появлению странных последовательностей, особенно при работе с базами данных и веб-страницами.
UTF-8 широко применяется в веб-разработке и при хранении данных. Практика показывает, что большинство современных браузеров и серверов автоматически распознают кодировку по метаданным HTTP или тегу <meta charset=»UTF-8″>. Рекомендуется использовать UTF-8 при создании сайтов и текстовых файлов для обеспечения совместимости и предотвращения проблем с локализацией и мультиязычным контентом.
Для конвертации файлов в UTF-8 на практике используют утилиты iconv, Notepad++ или встроенные функции IDE. Перед преобразованием важно определить исходную кодировку файла, чтобы избежать искажений символов. Также рекомендуется проверять содержимое через hex-редактор или специальные скрипты для обнаружения некорректных последовательностей байтов.
Что такое UTF-8 и как работает кодировка символов
Каждый многобайтовый символ в UTF-8 имеет определённый шаблон: первые байты начинаются с последовательности единиц, указывающей длину символа, а последующие байты всегда начинаются с 10. Это позволяет программам точно определять границы символов и корректно декодировать текст.
UTF-8 сохраняет совместимость с ASCII, что облегчает интеграцию с устаревшими системами и протоколами. Для практических задач важно проверять кодировку при открытии или сохранении файлов, особенно при работе с базами данных и веб-контентом. Использование неправильной кодировки может приводить к искажению текста и появлению знака �.
При обработке текста в UTF-8 рекомендуется использовать функции и библиотеки, которые учитывают длину символа в байтах, а не количество символов. Это важно при обрезке строк, подсчёте символов и работе с регулярными выражениями. Контроль корректной кодировки на этапе записи и чтения данных минимизирует ошибки при мультиязычной поддержке.
Как UTF-8 кодирует разные символы: от ASCII до Emoji
UTF-8 использует переменную длину для представления символов. Один и тот же механизм применяется ко всем символам Юникода, обеспечивая компактность и совместимость с ASCII. Конкретная длина байтов зависит от диапазона кодовой точки:
- 1 байт: символы ASCII (0–127). Пример: латинская буква A – 41 в шестнадцатеричной форме.
- 2 байта: символы от U+0080 до U+07FF. Пример: кириллическая буква Ж – D0 96.
- 3 байта: символы от U+0800 до U+FFFF. Пример: китайский иероглиф 你 – E4 BD A0.
- 4 байта: символы от U+10000 до U+10FFFF, включая большинство Emoji. Пример: Emoji 😊 – F0 9F 98 8A.
Каждый многобайтовый символ имеет строгую структуру: первый байт указывает количество байтов символа, последующие начинаются с 10. Это обеспечивает правильное разделение символов при чтении и минимизирует ошибки декодирования.
Для практического использования важно учитывать длину символа при:
- Обработке строк в программировании – функции подсчёта символов должны оперировать кодовыми точками, а не байтами.
- Сохранении файлов и работе с базами данных – проверка кодировки предотвращает появление � и неправильное отображение Emoji.
- Передаче данных через сеть – корректная сериализация UTF-8 гарантирует совместимость с различными системами и протоколами.
Порядок байтов в UTF-8 и влияние на совместимость
UTF-8 не зависит от порядка байтов в отличие от UTF-16 или UTF-32. Каждый символ кодируется последовательностью байтов, где структура позволяет однозначно определить начало и продолжение символа. Это исключает необходимость использования BOM (Byte Order Mark) для распознавания порядка байтов.
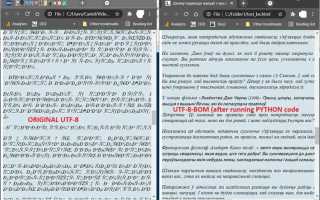
Несмотря на это, некоторые системы добавляют BOM в начало файла для совместимости с текстовыми редакторами Windows. Например, последовательность EF BB BF обозначает UTF-8 с BOM. При обработке файлов на Linux или в веб-среде BOM может вызывать неожиданные символы в начале текста.
Практические рекомендации:
- При создании веб-страниц и API рекомендуется использовать UTF-8 без BOM, чтобы избежать проблем с парсерами и библиотеками.
- При работе с текстовыми файлами на разных платформах проверяйте наличие BOM с помощью hex-редактора или встроенных функций IDE.
- Для баз данных и логов использовать строгую настройку кодировки UTF-8 без BOM, чтобы обеспечить корректную совместимость и избежать появления � при чтении.
Контроль порядка байтов особенно важен при интеграции с внешними системами или импортом данных, чтобы сохранить корректное отображение символов и избежать ошибок декодирования.
Определение длины символа в UTF-8 и правила декодирования
В UTF-8 длина символа определяется по значению первого байта в последовательности. Каждый многобайтовый символ начинается с определённого шаблона:
| Первый байт | Количество байтов символа | Пример |
|---|---|---|
| 0xxxxxxx | 1 | ASCII: A – 41 |
| 110xxxxx | 2 | Кириллица: Ж – D0 96 |
| 1110xxxx | 3 | Иероглиф: 你 – E4 BD A0 |
| 11110xxx | 4 | Emoji: 😊 – F0 9F 98 8A |
Последующие байты многобайтового символа всегда начинаются с 10xxxxxx. Это позволяет однозначно отделять символы и выявлять ошибки при декодировании.
Рекомендации по обработке:
- При чтении текста необходимо анализировать первый байт для определения длины символа перед декодированием.
- Функции подсчёта длины строки должны учитывать количество кодовых точек, а не количество байтов.
- При обрезке строк или разборе данных на части контролировать границы символов, чтобы не разрушить многобайтовые последовательности.
Проблемы неправильного отображения текста и способы их решения
Неправильное отображение текста в UTF-8 чаще всего возникает из-за несоответствия кодировок при чтении или сохранении данных. Символы могут заменяться на � или отображаться как странные последовательности, если файл был записан в одной кодировке, а читается в другой.
Основные причины проблем:
- Файл создан в UTF-8, но открыт как ISO-8859-1 или Windows-1251.
- Присутствие BOM, который некоторые редакторы интерпретируют некорректно.
- Некорректная обработка многобайтовых символов при разбиении строк или подсчёте символов.
Рекомендации по решению:
- Проверять и указывать кодировку при открытии файлов в текстовых редакторах и IDE.
- Использовать UTF-8 без BOM для веб-страниц и баз данных, чтобы избежать появления лишних символов.
- При обработке текста в программах применять функции, которые работают с кодовыми точками, а не с байтами, чтобы корректно обрезать и считать строки.
- Для существующих файлов использовать конвертацию через утилиты iconv или встроенные функции редакторов, проверяя результат через hex-редактор.
Следование этим рекомендациям минимизирует проблемы с отображением текста, особенно при работе с мультиязычными данными и Emoji.
Сравнение UTF-8 с другими кодировками: UTF-16 и ISO-8859-1
UTF-8 кодирует символы переменной длиной от 1 до 4 байт, сохраняя совместимость с ASCII. UTF-16 использует 2 или 4 байта на символ, а ISO-8859-1 фиксированно использует 1 байт для 256 символов, что ограничивает набор поддерживаемых языков.
Таблица сравнения:
| Кодировка | Длина байта | Совместимость с ASCII | Поддержка Emoji и нестандартных символов |
|---|---|---|---|
| UTF-8 | 1–4 | Да | Полная |
| UTF-16 | 2–4 | Нет | Полная |
| ISO-8859-1 | 1 | Частичная | Нет |
Рекомендации по выбору:
- UTF-8 подходит для веб-приложений, баз данных и мульти-язычных проектов, обеспечивая универсальность и компактность.
- UTF-16 используют при работе с большими массивами символов Юникода, например, в некоторых текстовых процессорах и API Windows.
- ISO-8859-1 применим только для старых систем с ограниченным набором символов западноевропейских языков.
При интеграции систем с разными кодировками важно конвертировать текст в UTF-8, чтобы избежать проблем с совместимостью, потерей символов и некорректным отображением.
Использование UTF-8 в веб-страницах и базах данных

UTF-8 обеспечивает корректное отображение текста на веб-страницах и при хранении данных в базах. Современные браузеры распознают кодировку через метатег <meta charset=»UTF-8″> или заголовок HTTP Content-Type.
Рекомендации для веб-разработки:
- Указывать UTF-8 в метатеге или HTTP-заголовках для всех страниц, чтобы избежать некорректного отображения символов.
- При работе с формами использовать атрибут accept-charset=»UTF-8″ для правильной передачи данных.
- При сохранении файлов HTML и CSS убедиться, что редактор сохраняет их в UTF-8 без BOM, чтобы избежать появления лишних символов.
При работе с базами данных:
- Настроить таблицы и колонки на кодировку UTF-8, например utf8mb4 в MySQL, чтобы поддерживать Emoji и полные наборы Юникода.
- Проверять соединение с базой данных и клиентские библиотеки на поддержку UTF-8, используя соответствующие параметры, например SET NAMES utf8mb4;
- При миграции данных из старых кодировок выполнять конвертацию с проверкой отображения символов через hex-редактор или специализированные скрипты.
Соблюдение этих правил гарантирует, что текст будет корректно отображаться и обрабатываться как на клиентской, так и на серверной стороне.
Проверка и конвертация файлов в UTF-8 на практике
Перед конвертацией файлов необходимо определить текущую кодировку. В Linux это можно сделать с помощью команды file -i filename или утилиты enca. В Windows текстовые редакторы, такие как Notepad++, позволяют определить и изменить кодировку через меню Encoding.
Для конвертации в UTF-8 используют:
- Команду iconv -f исходная_кодировка -t UTF-8 input.txt -o output.txt на Linux и macOS.
- Notepad++: открыть файл → Encoding → Convert to UTF-8 without BOM → сохранить.
- Инструменты IDE или скрипты на Python: open(‘file.txt’, encoding=’old’).read() с последующей записью через encoding=’utf-8′.
Рекомендации при конвертации:
- Создавать резервную копию файла перед преобразованием.
- Проверять результат через hex-редактор или просмотр специальных символов, чтобы убедиться, что многобайтовые символы не повреждены.
- При пакетной конвертации нескольких файлов использовать скрипты с проверкой каждой кодировки, чтобы избежать потери данных.
Регулярная проверка и конвертация в UTF-8 позволяет поддерживать корректное отображение текста и совместимость с современными системами и приложениями.
Вопрос-ответ:
Что такое UTF-8 и чем эта кодировка отличается от ASCII?
UTF-8 — это кодировка символов, которая использует от 1 до 4 байт для представления любого символа Юникода. Символы ASCII (0–127) кодируются одним байтом, что обеспечивает совместимость с устаревшими системами. Остальные символы, включая кириллицу, иероглифы и Emoji, занимают 2–4 байта, что позволяет хранить и передавать текст на любых языках без потери данных.
Как UTF-8 кодирует символы разной длины и почему это важно?
UTF-8 применяет переменно-длиное кодирование: один байт для стандартных ASCII, два байта для большинства европейских символов, три байта для восточноазиатских знаков и четыре байта для Emoji. Первый байт указывает длину символа, а последующие начинаются с 10. Этот механизм позволяет программам корректно разделять символы и предотвращает ошибки декодирования при работе с мультиязычным текстом.
Почему возникают ошибки отображения текста при использовании UTF-8?
Ошибки появляются, если файл был сохранён в одной кодировке, а читается в другой. Например, текст в UTF-8, открытый как ISO-8859-1, покажет странные символы или �. Другой причиной может быть наличие BOM, которое некоторые программы интерпретируют неправильно. Решение — проверка кодировки и использование корректных функций для чтения и записи данных.
Какие преимущества UTF-8 при работе с веб-страницами и базами данных?
UTF-8 обеспечивает поддержку всех символов Юникода и Emoji, сохраняя совместимость с ASCII. Для веб-страниц важно указывать кодировку через метатег <meta charset=»UTF-8″> или HTTP-заголовок. В базах данных рекомендуется использовать колонки с utf8mb4, чтобы корректно хранить и извлекать любой текст без искажений.
Как проверить и конвертировать файлы в UTF-8 без потери данных?
Сначала определите исходную кодировку с помощью утилит file -i или enca на Linux, либо через меню редактора в Windows. Для конвертации используют iconv, Notepad++ или скрипты на Python. Рекомендуется создавать резервные копии файлов и проверять результат через hex-редактор или специальные проверки, чтобы убедиться, что многобайтовые символы и Emoji остались корректными.
Почему UTF-8 стал стандартом для веб-страниц и приложений?
UTF-8 поддерживает все символы Юникода и сохраняет совместимость с ASCII, что позволяет передавать текст на любых языках без потери данных. Для веб-страниц важно указывать кодировку через метатег <meta charset=»UTF-8″> или HTTP-заголовок, а для приложений — использовать функции и библиотеки, корректно работающие с многобайтовыми символами.
Как отличить UTF-8 от других кодировок при работе с файлами?
Определить кодировку можно через команду file -i filename или утилиту enca в Linux, а в Windows — через Notepad++ в меню Encoding. UTF-8 без BOM не использует порядок байтов, а многобайтовые символы начинаются с определённого шаблона. Конвертацию выполняют с проверкой целостности символов, чтобы избежать искажений текста и появления знака �.