Содержание статьи

Мониторинг контейнеров Docker необходим для отслеживания нагрузки, использования ресурсов и стабильности приложений. Без него сложно понять, какие процессы создают избыточную нагрузку на CPU, память или диск, а также вовремя обнаружить сбои в сервисах. Практическая настройка мониторинга позволяет получать данные в реальном времени и оперативно реагировать на изменения в поведении контейнеров.
Перед установкой следует определить подходящий инструмент. Для простых сценариев подойдёт cAdvisor от Google – он отображает использование ресурсов по каждому контейнеру. Более гибкое решение – связка Prometheus + Grafana, обеспечивающая хранение метрик, визуализацию и настройку оповещений. В продакшене нередко применяют агенты Datadog или Zabbix, интегрирующиеся с Docker API.
Дальнейшие шаги включают подготовку Dockerfile с агентом мониторинга, настройку переменных окружения, подключение контейнера к сети и проверку работы системы через веб-интерфейс. Такой подход обеспечивает точный контроль за состоянием контейнеров и помогает выявлять проблемы до того, как они повлияют на производительность сервисов.
Подготовка окружения и выбор инструмента мониторинга

Перед установкой системы мониторинга необходимо убедиться, что на сервере установлен Docker Engine версии не ниже 20.10 и доступен docker-compose для управления многоконтейнерными приложениями. Проверить версии можно командами docker --version и docker-compose --version. Если Docker запускается от имени пользователя без прав root, стоит добавить его в группу docker с помощью команды sudo usermod -aG docker $USER.
Для тестовой установки достаточно хоста с 2 ГБ оперативной памяти и 10 ГБ свободного места. При использовании нескольких контейнеров рекомендуется включить системный демон systemd-journald или настроить отдельный том для логов, чтобы не перегружать основной диск контейнера.
Выбор инструмента зависит от целей. Если нужно контролировать потребление ресурсов, подойдёт cAdvisor, который работает без сложной настройки. Для сбора и анализа метрик на уровне сервисов лучше использовать Prometheus в связке с Grafana. Они позволяют сохранять данные в виде временных рядов и создавать панели с визуализацией. При интеграции с внешними системами уведомлений стоит рассмотреть Zabbix Agent или Datadog Agent, поддерживающие работу внутри контейнеров и обмен данными через Docker API.
Создание Dockerfile с агентом мониторинга
Для интеграции системы мониторинга в контейнер требуется создать отдельный Dockerfile, содержащий инструкции по установке агента и настройке его окружения. Это позволяет запускать сбор метрик автоматически при старте контейнера.
Пример базового Dockerfile для установки Prometheus Node Exporter:
FROM alpine:3.20
RUN apk add --no-cache curl
ADD https://github.com/prometheus/node_exporter/releases/download/v1.8.1/node_exporter-1.8.1.linux-amd64.tar.gz /tmp/
RUN tar -xzf /tmp/node_exporter-1.8.1.linux-amd64.tar.gz -C /usr/local/bin --strip-components=1
EXPOSE 9100
ENTRYPOINT ["/usr/local/bin/node_exporter"]
После создания Dockerfile нужно собрать образ:
docker build -t node-exporter:latest .Чтобы агент мог обращаться к ресурсам хоста, при запуске контейнера следует добавить параметры:
docker run -d \
--name node_exporter \
--net="host" \
--pid="host" \
-v "/:/host:ro,rslave" \
node-exporter:latest
Рекомендации при создании Dockerfile:
- Использовать минимальные базовые образы (alpine, scratch) для снижения нагрузки.
- Закреплять версии пакетов, чтобы избежать несовместимостей при обновлениях.
- Определять переменные окружения для конфигурации агента через
ENVили--env. - Добавлять инструкции
HEALTHCHECKдля проверки состояния агента.
Такой подход обеспечивает предсказуемую работу контейнера и упрощает развёртывание мониторинга на разных хостах.
Настройка переменных окружения для передачи метрик
Переменные окружения управляют тем, куда и как агент мониторинга отправляет метрики. Их можно задать в Dockerfile через инструкцию ENV или при запуске контейнера с помощью параметра -e. Правильная настройка позволяет изолировать конфигурацию от кода и изменять параметры без пересборки образа.
Основные типы переменных:
- Адрес сервера мониторинга:
PROMETHEUS_TARGET,ZABBIX_SERVER,DATADOG_SITE. Указывает, куда агент отправляет данные. - Интервал обновления:
SCRAPE_INTERVALилиCOLLECT_FREQUENCY. Определяет частоту сбора метрик, например 15s или 60s. - Параметры аутентификации:
API_KEY,ACCESS_TOKEN,USER_PASS. Используются для безопасного доступа к внешним сервисам. - Контроль источников данных:
DOCKER_HOST(например, unix:///var/run/docker.sock),MONITORED_SERVICES– список контейнеров или сервисов, для которых собираются метрики.
Пример запуска агента Prometheus Node Exporter с переменными окружения:
docker run -d \
--name node_exporter \
-e SCRAPE_INTERVAL=15s \
-e PROMETHEUS_TARGET=http://prometheus:9090 \
-v /proc:/host/proc:ro \
-v /sys:/host/sys:ro \
-v /:/rootfs:ro \
node-exporter:latest
Для упрощения конфигурации можно использовать файл .env и подключать его через --env-file .env. Это позволяет централизованно хранить параметры подключения и исключить ошибки при ручном вводе.
Рекомендуется не хранить ключи доступа в открытом виде. Для этого можно использовать Docker secrets или внешние менеджеры конфигурации, такие как Vault или AWS Systems Manager Parameter Store.
Подключение контейнера к сети для обмена данными с сервером мониторинга
Для корректной передачи метрик контейнер должен иметь сетевое соединение с сервером мониторинга. В Docker существует несколько режимов сетевого взаимодействия, каждый из которых подходит для разных сценариев интеграции.
| Режим сети | Описание | Применение |
|---|---|---|
bridge |
Контейнер получает отдельный IP внутри внутренней сети Docker. Связь с другими контейнерами осуществляется по имени сервиса. | Подходит для изолированных сред с несколькими контейнерами и внутренним сбором метрик. |
host |
Контейнер использует сетевой стек хоста без NAT. Метрики доступны напрямую по IP хоста. | Оптимален для систем, где важна минимальная задержка при передаче данных. |
overlay |
Создаёт виртуальную сеть между контейнерами на разных узлах кластера Docker Swarm. | Используется при распределённом мониторинге на нескольких серверах. |
Создание пользовательской сети упрощает адресацию и настройку взаимодействия между агентом и сервером:
docker network create monitoring_netПосле этого контейнер можно подключить к сети при запуске:
docker run -d \
--name node_exporter \
--network monitoring_net \
node-exporter:latest
Если сервер мониторинга (например, Prometheus) работает в том же Docker Compose-проекте, рекомендуется указать общую сеть в конфигурации docker-compose.yml:
networks:
monitoring_net:
driver: bridge
Проверить сетевое подключение можно командой docker exec -it node_exporter ping prometheus. Отсутствие ответа указывает на ошибку в настройке сети или имени сервиса.
Конфигурирование сборщиков метрик и логов внутри контейнера
После подключения агента мониторинга необходимо задать параметры сбора метрик и логов. Для большинства систем конфигурация хранится в YAML или JSON-файлах, которые можно передавать в контейнер через тома или переменные окружения.
В Prometheus Node Exporter сбор метрик осуществляется автоматически, но можно ограничить доступные ресурсы с помощью флагов запуска, например --collector.cpu, --collector.meminfo, --collector.filesystem. Это позволяет исключить ненужные источники и уменьшить объём передаваемых данных.
Для агентов Datadog и Zabbix используется конфигурация через файлы datadog.yaml или zabbix_agentd.conf. В них задаются параметры:
- log_level – уровень детализации логов (info, warn, error);
- log_to_file – путь к файлу журнала внутри контейнера;
- tags – метки для идентификации контейнера в панели мониторинга;
- remote_write – адрес сервера для передачи метрик.
Если требуется собирать логи приложений, работающих в контейнере, рекомендуется перенаправлять стандартные потоки stdout и stderr в системный лог Docker. Это упрощает интеграцию с внешними средствами, такими как Fluent Bit или Logstash, которые могут забирать данные через сокет /var/lib/docker/containers/<id>/json.log.
Для изоляции логов разных сервисов полезно использовать отдельные каталоги в контейнере и монтировать их как внешние тома. Пример монтирования:
docker run -d \
-v /var/log/monitoring:/var/log/agent \
-v /proc:/host/proc:ro \
-v /sys:/host/sys:ro \
monitoring-agent:latest
Перед перезапуском контейнера следует проверить права на каталоги с логами и наличие доступа к системным ресурсам. Ошибки чтения /proc или /sys приводят к неполному сбору метрик.
Проверка работы мониторинга через веб-интерфейс или API
После настройки агента и сети необходимо убедиться, что метрики собираются и передаются корректно. Для этого используют веб-интерфейсы и API серверов мониторинга.
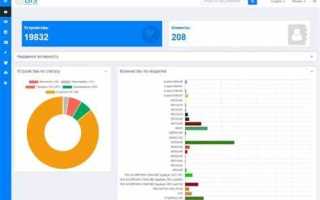
Для Prometheus проверка выполняется через веб-интерфейс по адресу http://<адрес_сервера>:9090/targets. Здесь отображаются все подключенные контейнеры, статус их метрик и последние успешные обращения. В колонке LAST SCRAPE можно увидеть время последнего обновления данных.
Для визуальной проверки через Grafana создают панели и графики на основе метрик Prometheus. Если данные не отображаются, необходимо проверить настройки scrape_configs в prometheus.yml и сетевые подключения контейнеров.
API проверка подходит для автоматизированного контроля. Пример запроса к Prometheus для получения значения метрики CPU:
curl -g 'http://<адрес_сервера>:9090/api/v1/query?query=node_cpu_seconds_total'
Если используется Datadog, можно проверить отправку метрик через API:
curl -X GET "https://api.datadoghq.com/api/v1/metrics" \
-H "DD-API-KEY: <ваш_ключ>" \
-H "DD-APPLICATION-KEY: <ваш_ключ_приложения>"
Для регулярного контроля полезно настроить healthcheck в Docker, который обращается к API агента каждые 30–60 секунд. Пример в Dockerfile:
HEALTHCHECK --interval=30s --timeout=5s \
CMD curl -f http://localhost:9100/metrics || exit 1
Такая проверка позволяет оперативно обнаруживать сбои сбора метрик и реагировать до появления проблем в производственной среде.
Автоматизация запуска и обновления мониторинга через Docker Compose
Docker Compose позволяет управлять многоконтейнерными приложениями и упрощает развертывание систем мониторинга. Для автоматизации запуска создают файл docker-compose.yml, в котором задаются образы, сети, тома и переменные окружения для каждого агента.
Пример конфигурации для Prometheus и Node Exporter:
version: '3.9'
services:
prometheus:
image: prom/prometheus:v2.50.0
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml:ro
ports:
- "9090:9090"
networks:
- monitoring_net
node_exporter:
image: prom/node-exporter:v1.8.1
network_mode: "host"
pid: "host"
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
networks:
monitoring_net:
driver: bridge
Для обновления образов без остановки всей системы используют команду:
docker-compose pull && docker-compose up -dЭто позволяет подтянуть новые версии агентов и Prometheus, сохранив текущие тома и конфигурацию. Для ежедневного контроля обновлений можно настроить cron job на хосте с проверкой новых версий образов и автоматическим перезапуском контейнеров.
При изменении конфигурации достаточно обновить локальные файлы prometheus.yml или переменные окружения, после чего выполнить:
docker-compose up -d --no-deps --build <имя_сервиса>
Это гарантирует, что обновления применяются только к изменённым сервисам, не нарушая работу остальных контейнеров мониторинга.
Вопрос-ответ:
Какие инструменты мониторинга лучше использовать для Docker-контейнеров?
Для базового контроля ресурсов подойдёт cAdvisor, который показывает использование CPU, памяти и диска по каждому контейнеру. Для более сложного анализа метрик используют связку Prometheus + Grafana, где Prometheus собирает данные, а Grafana визуализирует их на панелях. Если нужен сбор логов и оповещения, стоит рассмотреть Zabbix Agent или Datadog, которые интегрируются с Docker API и позволяют отслеживать контейнеры в реальном времени.
Как правильно настроить переменные окружения для агента мониторинга?
Переменные окружения задают адрес сервера мониторинга, интервал сбора метрик, ключи доступа и список контейнеров для наблюдения. Их можно прописать в Dockerfile через ENV или при запуске контейнера с параметром -e. Для безопасного хранения ключей лучше использовать Docker secrets или внешние менеджеры конфигурации, такие как Vault. Это позволяет менять настройки без пересборки образа и предотвращает утечки данных.
Как проверить, что сбор метрик и логов работает корректно?
Проверку проводят через веб-интерфейс или API сервера мониторинга. В Prometheus можно открыть http://<адрес_сервера>:9090/targets, где отображаются все подключённые контейнеры и время последнего обновления метрик. В Grafana создают панели с графиками, чтобы видеть динамику показателей. Для автоматизации контроля используют healthcheck в Docker, который периодически обращается к API агента и фиксирует ошибки сбора метрик.
Как упростить запуск и обновление мониторинга на нескольких контейнерах?
Для этого используют Docker Compose. В файле docker-compose.yml описывают образы, тома, сети и переменные окружения для каждого агента. При изменении конфигурации или обновлении образов достаточно выполнить docker-compose pull && docker-compose up -d. Если изменился только один сервис, можно запустить его отдельно с параметром --no-deps --build, чтобы остальные контейнеры продолжали работать без перезапуска.