Содержание статьи

Кодировка в Oracle определяет способ хранения и обработки символов, включая кириллицу и другие национальные алфавиты. От выбранной кодировки зависит корректность отображения данных, работа приложений и интеграция с внешними системами. Ошибки в настройках могут привести к искажению текстов и потере информации.
Проверка кодировки необходима при переносе базы между серверами, настройке новых клиентов или диагностике проблем с отображением символов. В Oracle параметры кодировки задаются на уровне базы данных, клиента и сеанса. Для каждой из этих областей существуют отдельные методы проверки, основанные на SQL-запросах и системных представлениях.
Чтобы избежать несоответствия между базой и клиентом, важно понимать, какие параметры отвечают за язык, территорию и набор символов. В статье подробно рассмотрены практические способы определения кодировки с использованием SQL*Plus, Oracle SQL Developer и JDBC-подключений.
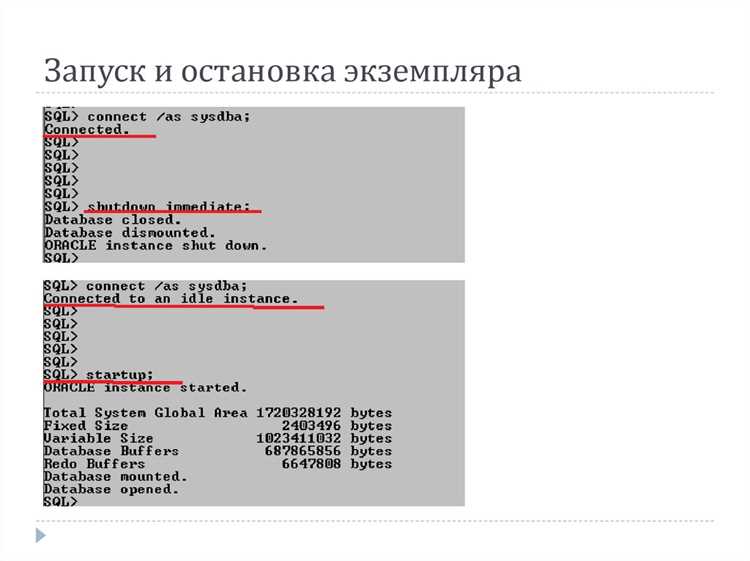
Как определить текущую кодировку базы через SQL*Plus
Чтобы узнать кодировку базы данных Oracle, подключитесь к экземпляру с помощью утилиты SQL*Plus под пользователем с правами на просмотр системных параметров. После входа выполните команду:
SELECT * FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER=’NLS_CHARACTERSET’;
Результат запроса отобразит значение параметра NLS_CHARACTERSET, которое определяет текущую кодировку базы данных, например AL32UTF8 или WE8MSWIN1251. Этот параметр фиксируется при создании базы и не может быть изменён без пересоздания или конвертации данных.
Для проверки вспомогательных языковых параметров можно вывести расширенный список командой:
SELECT PARAMETER, VALUE FROM NLS_DATABASE_PARAMETERS;
Здесь отображаются настройки, связанные с языком, территорией и форматом данных. Полученные значения стоит сравнить с параметрами клиента, чтобы убедиться в корректности отображения символов при работе с приложениями и инструментами администрирования.
Проверка кодировки с помощью представления NLS_DATABASE_PARAMETERS
Представление NLS_DATABASE_PARAMETERS используется для получения сведений о языковых и региональных настройках базы данных Oracle. Оно хранит значения всех параметров NLS, включая кодировку символов, применяемую при сохранении данных.
Чтобы определить кодировку, выполните SQL-запрос:
SELECT PARAMETER, VALUE FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER IN (‘NLS_CHARACTERSET’,’NLS_NCHAR_CHARACTERSET’);
Параметр NLS_CHARACTERSET указывает набор символов для типов CHAR и VARCHAR2, а NLS_NCHAR_CHARACTERSET – для NCHAR и NVARCHAR2. Например, AL32UTF8 обозначает многобайтовую кодировку Unicode, а CL8MSWIN1251 – однобайтовую кириллическую.
Для проверки всех доступных языковых параметров можно выполнить:
SELECT PARAMETER, VALUE FROM NLS_DATABASE_PARAMETERS ORDER BY PARAMETER;
Рекомендуется сохранять значения этих параметров при миграции или создании резервных копий, чтобы при восстановлении базы можно было сохранить исходную кодировку и избежать несовместимости данных между различными системами.
Просмотр кодировки в Oracle SQL Developer

В Oracle SQL Developer определить кодировку базы данных можно без выполнения SQL-запросов. После подключения к нужной базе откройте раздел View → DBA и выберите подключение с правами администратора. В дереве объектов перейдите к пункту Database → NLS Parameters.
В списке параметров отображаются значения NLS_CHARACTERSET и NLS_NCHAR_CHARACTERSET. Первый параметр задаёт набор символов для типов CHAR и VARCHAR2, второй – для NCHAR и NVARCHAR2. Эти значения можно экспортировать в файл для документирования конфигурации.
Если доступ к представлению DBA ограничен, кодировку можно узнать через выполнение запроса прямо из окна SQL Worksheet:
SELECT PARAMETER, VALUE FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER LIKE ‘%CHARACTERSET%’;
Рекомендуется сверить полученные значения с настройками клиентского соединения, которые можно посмотреть через меню Tools → Preferences → Environment → Encoding. Совпадение кодировок базы и клиента гарантирует корректное отображение национальных символов в интерфейсе SQL Developer.
Как узнать кодировку клиента и сеанса в Oracle
Кодировка клиента и текущего сеанса влияет на интерпретацию символов при передаче данных между приложением и сервером. Несоответствие этих параметров может привести к искажению текста, особенно при работе с национальными алфавитами.
Чтобы проверить текущие настройки в Oracle, используйте следующие запросы:
- SELECT * FROM NLS_SESSION_PARAMETERS WHERE PARAMETER LIKE ‘%CHARACTERSET%’; – показывает кодировку, используемую в текущем сеансе.
Для проверки клиентской кодировки можно выполнить запрос:
SELECT USERENV(‘LANG’) FROM DUAL;
Результат включает сведения о языке, территории и наборе символов клиента. Например, строка RUSSIAN_RUSSIA.CL8MSWIN1251 означает использование кириллической кодировки Windows-1251.
Сравните полученные значения с параметрами базы (NLS_CHARACTERSET) – при несовпадении наборов символов необходимо скорректировать переменную окружения NLS_LANG на клиенте. Это обеспечит правильное отображение и сохранение текстовых данных.
Определение кодировки при подключении через JDBC

При подключении к Oracle через JDBC кодировка определяется настройками Java и параметрами соединения. Ошибка в указании набора символов может вызвать искажение текста при обмене данными между клиентом и сервером.
Текущую кодировку среды Java можно проверить с помощью команды:
System.getProperty(«file.encoding»);
Чтобы узнать, какая кодировка используется в базе, выполните SQL-запрос через JDBC:
SELECT VALUE FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER=’NLS_CHARACTERSET’;
Сравнение этих значений позволяет определить, совпадают ли кодировки клиента и сервера. При несовпадении символы национальных алфавитов могут отображаться некорректно.
Для устранения несоответствия в строке подключения следует указать параметры:
jdbc:oracle:thin:@host:port:sid?useUnicode=true&characterEncoding=UTF-8
Если приложение использует Oracle JDBC Thin Driver, рекомендуется настроить JVM на использование Unicode-кодировки (UTF-8) через параметр запуска:
-Dfile.encoding=UTF-8
Совпадение кодировок на уровне базы, клиента и соединения предотвращает ошибки при вводе и хранении символов разных языков.
Как проверить соответствие кодировок базы и операционной системы

Несовпадение кодировок базы данных и операционной системы вызывает искажение текста при загрузке данных, экспорте и работе клиентских приложений. Проверка параметров обеих сторон помогает исключить ошибки при передаче символов.
Для просмотра кодировки базы данных выполните запрос:
SELECT VALUE FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER=’NLS_CHARACTERSET’;
Для проверки кодировки операционной системы используйте соответствующую команду:
| Операционная система | Команда для проверки кодировки |
|---|---|
| Linux / Unix | locale | grep LANG |
| Windows | chcp или systeminfo | find «System Locale» |
Полученные значения необходимо сопоставить с параметром NLS_CHARACTERSET. Если база использует, например, AL32UTF8, а ОС – однобайтовую кодировку CP1251, требуется перенастройка клиентской переменной NLS_LANG для корректного обмена данными.
Рекомендуется использовать единый стандарт кодировки UTF-8 как в базе, так и на уровне системы. Это обеспечивает совместимость с приложениями, поддерживающими многобайтовые символы, и предотвращает ошибки при миграции данных между серверами.
Что делать при несовпадении кодировок между базой и клиентом
Несовпадение кодировок между клиентом и базой Oracle приводит к искажению текста при вводе, сохранении или экспорте данных. Для устранения проблемы требуется корректировка параметров среды и соединения.
Порядок действий:
- Определите кодировку базы данных командой:
SELECT VALUE FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER=’NLS_CHARACTERSET’; - Проверьте текущие настройки клиента:
SELECT USERENV(‘LANG’) FROM DUAL; - Сравните оба значения. Если они различаются, настройте переменную окружения NLS_LANG на стороне клиента в соответствии с кодировкой базы. Формат переменной:
NLS_LANG=LANGUAGE_TERRITORY.CHARACTERSET - Пример для базы с кодировкой UTF-8:
NLS_LANG=RUSSIAN_RUSSIA.AL32UTF8 - После изменения параметра перезапустите клиентское приложение или сеанс подключения.
При использовании JDBC кодировку можно задать в строке подключения:
jdbc:oracle:thin:@host:port:sid?useUnicode=true&characterEncoding=UTF-8
Если приложение работает через OCI, параметр NLS_LANG задаётся в системных переменных операционной системы. На Linux – через export NLS_LANG, на Windows – в разделе реестра HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE.
После изменения настроек рекомендуется выполнить тестовую запись и чтение данных с национальными символами, чтобы убедиться в корректности передачи текста между клиентом и сервером.
Вопрос-ответ:
Как узнать, в какой кодировке создана база данных Oracle?
Проверить кодировку можно через SQL*Plus, выполнив запрос: SELECT VALUE FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER=’NLS_CHARACTERSET’;. Результат укажет, какой набор символов используется для хранения текстовых данных, например AL32UTF8 или CL8MSWIN1251.
Можно ли изменить кодировку базы данных без пересоздания?
Кодировка, заданная при создании базы, не изменяется напрямую. Чтобы перейти к другой кодировке, требуется использовать утилиту DMU (Database Migration Assistant for Unicode) или выполнить экспорт данных в новую базу с нужным набором символов.
Как проверить, какая кодировка используется на клиенте Oracle?
Текущие настройки клиента можно узнать командой SELECT USERENV(‘LANG’) FROM DUAL;. В ответе содержится строка вида AMERICAN_AMERICA.AL32UTF8 или RUSSIAN_RUSSIA.CL8MSWIN1251, где последняя часть обозначает кодировку. Её следует сравнить с параметром NLS_CHARACTERSET базы.
Почему текст в приложении отображается с ошибками при работе с Oracle?
Проблема возникает, если кодировка клиента не совпадает с кодировкой базы данных. Например, при подключении клиента Windows с CP1251 к базе с AL32UTF8. Для устранения несоответствия необходимо установить переменную NLS_LANG в значение, соответствующее кодировке базы, и перезапустить приложение.
Как узнать кодировку при подключении к Oracle через JDBC?
В JDBC кодировка задаётся параметром characterEncoding в строке подключения. Для проверки кодировки базы можно выполнить запрос: SELECT VALUE FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER=’NLS_CHARACTERSET’;. Если значения отличаются, в строке подключения следует указать useUnicode=true&characterEncoding=UTF-8.