Содержание статьи

Кодировка текстового файла определяет, как байты интерпретируются в символы. Ошибка в её определении приводит к «кракозябрам», потере данных при импорте и сбоям в обработке текста скриптами и программами. Особенно часто это возникает при работе с файлами, созданными в разных операционных системах, устаревших редакторах или при передаче данных между серверами.
На практике чаще всего приходится иметь дело с кодировками UTF-8, UTF-16, Windows-1251 и KOI8-R. UTF-8 может содержать BOM или обходиться без него, что напрямую влияет на автоматическое распознавание. Windows-1251 и KOI8-R визуально похожи, но при неверном выборе одна кириллическая последовательность превращается в нечитаемый набор символов.
Перед изменением кодировки файл рекомендуется открывать в редакторе, который показывает текущий формат без преобразования содержимого. Если редактор автоматически перекодирует текст при открытии, восстановить исходные данные становится сложно. Для анализа также полезно проверять размер файла в байтах, наличие BOM и диапазоны используемых символов.
В серверной и скриптовой среде кодировку определяют через командные утилиты или анализ байтовых последовательностей. Это позволяет выявить формат без визуального просмотра и избежать искажения данных при автоматической обработке. Выбор метода зависит от операционной системы, доступных инструментов и задачи – просмотра, конвертации или отладки.
Определение кодировки файла через системные свойства в Windows
Проводник Windows не показывает кодировку текстового файла напрямую, но через системные свойства можно получить косвенные признаки. Для этого открой свойства файла и обрати внимание на тип файла, размер и дату изменения. Если файл создан стандартным «Блокнотом», он с высокой вероятностью использует UTF-8 без BOM в актуальных версиях Windows или ANSI в более старых сборках.
Размер файла в байтах помогает выявить кодировки с фиксированной длиной символа. Например, если файл содержит только кириллицу и его размер примерно в два раза больше количества символов, это может указывать на UTF-16. Для UTF-8 характерна переменная длина символов, поэтому размер будет нестабильным при смешении латиницы и кириллицы.
Через вкладку «Подробно» можно определить приложение, создавшее файл. Текстовые редакторы и IDE часто используют конкретные кодировки по умолчанию. Если источник – сторонняя программа или устаревшее ПО, велика вероятность использования Windows-1251. Эти данные особенно полезны при анализе логов и конфигурационных файлов.
Системные свойства не заменяют специализированные инструменты, но позволяют сузить круг вариантов до одного-двух форматов. Это снижает риск порчи данных при первом открытии файла в редакторе и помогает выбрать корректную кодировку для дальнейшей работы.
Проверка кодировки файла с помощью текстового редактора Notepad++
Notepad++ отображает текущую кодировку файла сразу после открытия. Актуальный формат подсвечивается в меню «Кодировки», где можно увидеть, открыт ли файл как UTF-8, UTF-8 с BOM, UTF-16 LE/BE или одна из ANSI-кодировок. Этот режим просмотра не изменяет содержимое, пока не выполнено сохранение.
Если текст отображается некорректно, следует последовательно переключаться между вариантами в разделе «Кодировать в», не используя «Преобразовать в». Перекодирование меняет байтовую структуру файла и может уничтожить исходные данные. Для проверки достаточно визуально оценить корректность символов после смены режима отображения.
Дополнительный ориентир – строка состояния в нижней части окна. В ней указывается кодировка и тип перевода строк. Это особенно полезно при работе с конфигурационными файлами и скриптами, где неверный формат приводит к ошибкам выполнения.
Для файлов без явных маркеров Notepad++ использует эвристическое распознавание. Если результат сомнительный, рекомендуется временно отключить автоматическое определение кодировки в настройках и повторно открыть файл с ручным выбором формата. Такой подход позволяет точно определить исходную кодировку перед сохранением.
Просмотр кодировки текстового файла в Visual Studio Code
Visual Studio Code показывает текущую кодировку файла в строке состояния в правой нижней части окна. Значение отображается сразу после открытия и обычно выглядит как UTF-8 или UTF-16 LE. Этот индикатор отражает режим, в котором файл был интерпретирован редактором, без изменения исходных байтов.
При нажатии на обозначение кодировки открывается список доступных вариантов с разделением на просмотр и преобразование. Для анализа следует выбирать режим повторного открытия с другой кодировкой, а не сохранение в новом формате. Это позволяет сравнить отображение текста и определить корректный вариант без риска повреждения данных.
Если файл содержит BOM, редактор определяет кодировку однозначно. При его отсутствии используется эвристика, основанная на частоте символов. В случае кириллического текста это может приводить к неверному распознаванию, особенно при коротком содержимом или смешении алфавитов.
Для точной диагностики рекомендуется временно отключить автоматическое определение кодировки в настройках и вручную открыть файл в предполагаемых форматах. Такой подход полезен при работе с логами, выгрузками из баз данных и файлами, полученными из внешних систем.
Определение кодировки файла через командную строку Windows
Для диагностики используются стандартные средства системы и внешние утилиты, если они доступны. Практический порядок действий выглядит так:
- проверить активную кодовую страницу консоли и при необходимости временно изменить её на 65001 для работы с UTF-8;
- вывести первые строки файла в консоль и оценить корректность отображения кириллицы;
- сравнить результат при разных кодовых страницах, фиксируя вариант с читаемым текстом.
Для более точного определения применяются сторонние консольные инструменты, которые анализируют байтовые последовательности и вероятностное распределение символов. Такой подход особенно полезен для логов, дампов и больших текстовых файлов, где визуальная проверка затруднена.
Проверка кодировки текстового файла в Linux с помощью утилиты file
Утилита file определяет тип содержимого по сигнатурам и статистическому анализу байтов, а не по расширению. При проверке текстовых файлов она часто указывает предполагаемую кодировку, например UTF-8 Unicode text, UTF-16 Unicode text или ISO-8859. Это позволяет быстро оценить формат без открытия файла.
Определение кодировки файла через Python-скрипт
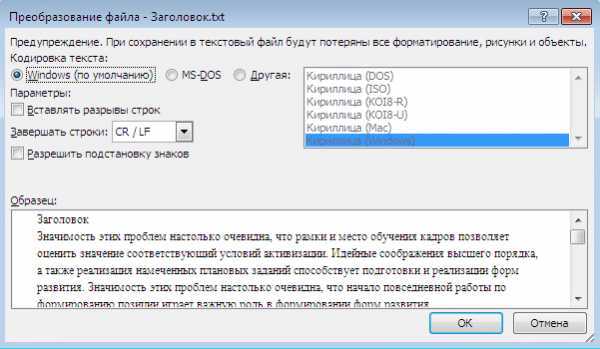
Python позволяет анализировать кодировку текстового файла с высокой точностью, используя стандартные и сторонние библиотеки. Наиболее популярный подход – применение модуля chardet или charset-normalizer, которые оценивают байтовые последовательности и вероятность конкретной кодировки.
Пример алгоритма проверки кодировки файла выглядит так:
- Открыть файл в бинарном режиме, чтобы не произошло автоматического декодирования.
- Считать фрагмент или весь файл в байтовый массив.
- Передать массив в функцию распознавания кодировки из выбранной библиотеки.
- Получить результат с указанием кодировки и вероятности точности.
Для файлов с BOM Python автоматически определяет формат, если использовать utf-8-sig или utf-16. В случае отсутствия маркера рекомендуется считывать первые несколько килобайт для анализа статистики символов, что ускоряет процесс и снижает нагрузку на память при больших файлах.
При обработке серии файлов полезно сохранять результаты проверки в лог или словарь, сопоставляя имя файла, выявленную кодировку и вероятность. Это облегчает массовую конвертацию и предотвращает повреждение данных при автоматическом сохранении в новом формате.
Распознавание кодировки при загрузке файла в онлайн-сервисе
Онлайн-сервисы для анализа текстовых файлов часто используют встроенные алгоритмы распознавания кодировки на основе BOM и статистического распределения байтов. При загрузке файла сервис определяет вероятный формат и отображает текст в читаемом виде без изменения исходных данных.
Для корректной работы рекомендуется:
- Загружать файлы с расширением, соответствующим типу текста (.txt, .csv, .log), чтобы сервис применил правильные фильтры.
- Проверять предварительный просмотр содержимого перед сохранением или экспортом.
- Обращать внимание на предупреждения о нераспознанных символах или смешанных кодировках, что может потребовать ручного выбора формата.
Некоторые сервисы предоставляют детальную информацию по байтовым последовательностям. Это удобно при сравнении результатов нескольких файлов или при необходимости конвертации в другую кодировку.
| Сервис | Поддерживаемые кодировки | Особенности |
|---|---|---|
| Online-Convert | UTF-8, UTF-16, ISO-8859-1, Windows-1251 | Автоматическое распознавание BOM и предварительный просмотр текста |
| Encode Explorer | UTF-8, UTF-16, ASCII | Отображает вероятности кодировок и поддерживает пакетную проверку файлов |
| TextFixer | UTF-8, Windows-1251, ISO-8859-5 | Подсветка некорректных символов и возможность ручного выбора кодировки |
Использование онлайн-сервисов удобно для быстрого анализа и проверки небольших файлов, но при работе с конфиденциальными данными рекомендуется применять локальные инструменты для предотвращения утечки информации.
Вопрос-ответ:
Как определить кодировку файла, если он открывается как набор странных символов в блокноте?
Если при открытии файла в стандартном Блокноте текст отображается некорректно, это значит, что кодировка файла не совпадает с настройками редактора. Первым шагом стоит открыть файл в Notepad++ или Visual Studio Code, которые показывают текущую кодировку. В Notepad++ это делается через меню «Кодировки», в VS Code — в строке состояния справа внизу. Если текст по-прежнему нечитаемый, попробуйте переключить кодировку на UTF-8, UTF-16 или Windows-1251, не сохраняя файл сразу, чтобы не изменить байты. Также полезно проверить, есть ли в начале файла BOM, так как он влияет на распознавание кодировки.
Можно ли узнать кодировку файла через командную строку Windows?
Да, это возможно, хотя стандартная командная строка не выдаёт кодировку напрямую. Можно использовать команду type для просмотра содержимого и сопоставления с текущей кодовой страницей консоли. Если текст отображается корректно при кодовой странице 65001, вероятно, файл в UTF-8. Для более точного определения можно применять внешние утилиты, которые анализируют байтовые последовательности и указывают предполагаемый формат. Этот метод особенно удобен для проверки больших файлов без их открытия в редакторе.
Как Python помогает определить кодировку текстового файла?
Python позволяет считывать файл в бинарном режиме и анализировать байты без риска изменения содержимого. Для этого применяются библиотеки вроде chardet или charset-normalizer. Алгоритм работы обычно включает чтение первых нескольких килобайт файла, передачу их в функцию распознавания и получение кодировки с вероятностью точности. Такой подход полезен для автоматической обработки серии файлов или проверки неизвестных источников. При наличии BOM определение происходит автоматически, что ускоряет процесс.
Как онлайн-сервисы определяют кодировку и можно ли им доверять?
Онлайн-сервисы анализируют файл на основе сигнатур и статистики байтов, выявляя вероятность конкретной кодировки. Они часто показывают предварительный просмотр текста и предлагают выбор вариантов для ручной корректировки. Для небольших файлов сервисы дают точные результаты, но при работе с файлами, содержащими нестандартные символы или короткий текст, распознавание может быть неточным. Если данные конфиденциальные, лучше использовать локальные инструменты, чтобы не передавать их через интернет.