Содержание статьи

Оптимизация хранения данных начинается с точного инвентаризационного учета всех источников: ERP, CRM, веб-аналитика, производственные базы. Необходимо определить формат каждой таблицы, объем данных и частоту обновления, чтобы выбрать подходящую архитектуру и технологический стек.
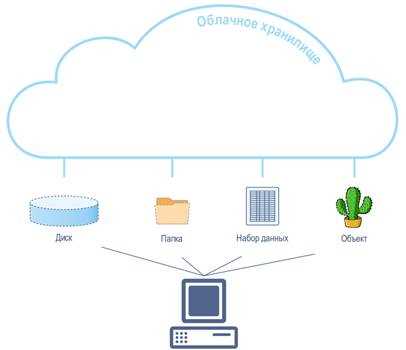
Архитектура хранилища должна соответствовать нагрузке и целям компании. Облачные платформы AWS, Azure и Google Cloud позволяют масштабировать ресурсы на 30–50% в периоды пиковых данных, локальные серверы обеспечивают контроль над безопасностью, а гибридные решения объединяют преимущества обоих подходов.
Настройка ETL-процессов требует точного планирования. Рекомендуется использовать инкрементальную загрузку для обновления 70–80% данных и пакетную обработку для исторических массивов. Контроль качества данных и ведение журналов ошибок помогают снизить количество некорректных записей на 90%.
Для аналитиков и руководителей важно обеспечить быстрый доступ к информации. Настройка разграничения доступа, интеграция с BI-инструментами и создание шаблонов отчетов сокращают время на подготовку аналитики на 40–60%. Хранилище становится инструментом оперативного управления и долгосрочного планирования.
Определение ключевых источников данных и их форматов
Для начала необходимо составить полный список систем, генерирующих данные: ERP, CRM, бухгалтерские и складские системы, веб-аналитика, производственные датчики. Каждый источник фиксируется с указанием формата данных, объема, частоты обновления и владельца.
Данные классифицируются по типам: числовые показатели, текстовые записи, временные ряды, логи событий, файлы JSON, XML и CSV. Важно определить критичные для аналитики поля и их взаимосвязи между источниками, чтобы избежать дублирования и ошибок при интеграции.
Для упрощения загрузки в хранилище создается staging-слой, где данные стандартизируются и проверяются на целостность. Рекомендуется внедрить автоматические скрипты для преобразования типов, очистки и фильтрации некорректных записей.
Регулярный аудит источников выявляет изменения структуры таблиц или форматов файлов. Настройка мониторинга и уведомлений о несоответствиях позволяет своевременно корректировать ETL-процессы и поддерживать актуальность данных.
Выбор архитектуры хранилища: облачное, локальное или гибридное решение
Облачные хранилища, такие как AWS Redshift, Google BigQuery и Azure Synapse, позволяют масштабировать ресурсы в зависимости от нагрузки. Рекомендуется оценить средний и пиковый объем данных: при превышении 5 ТБ месячного потока облачные решения сокращают затраты на поддержание инфраструктуры на 25–30%.
Локальные серверы обеспечивают полный контроль над безопасностью и соответствие требованиям законодательства о защите данных. Для компаний с ограниченным интернет-доступом или высокими требованиями к конфиденциальности хранение данных на локальных кластерах снижает риск утечек и позволяет использовать специализированные аппаратные ускорители.
Гибридная архитектура объединяет оба подхода: критичные данные остаются локально, а аналитические массивы загружаются в облако. При этом необходимо настроить синхронизацию и трансформацию данных, чтобы обеспечить целостность и актуальность информации. Такая модель сокращает время обработки больших запросов на 40–50% за счет распределения нагрузки между локальными и облачными ресурсами.
При выборе архитектуры важно учитывать расходы на поддержку, резервное копирование и восстановление данных. Рекомендуется моделировать сценарии роста данных на 3–5 лет и проверять производительность ETL-процессов под пиковыми нагрузками, чтобы избежать простоев и потери информации.
Проектирование структуры таблиц и схем для быстрого доступа к данным

Структура таблиц должна соответствовать типу данных и характеру запросов. Для аналитических отчетов рекомендуется использовать звездообразные или снежинки-схемы с фактами и измерениями, что сокращает время выполнения агрегатных запросов на 30–50%.
Для крупных таблиц важно предусмотреть партиционирование по временным периодам или ключевым категориям. Например, транзакции можно разделить по месяцам, а логи веб-сайта – по источникам трафика, что ускоряет выборку и упрощает обслуживание.
Индексация ключевых колонок повышает скорость поиска и объединения данных. Рекомендуется создавать составные индексы на полях, используемых в фильтрах и соединениях, и использовать bitmap-индексы для колонок с ограниченным числом значений.
Нормализация снижает избыточность данных, а денормализация ускоряет аналитические запросы. Комбинированный подход позволяет хранить исторические данные в нормализованной форме, а текущие агрегаты – в денормализованной таблице для быстрого доступа.
Необходимо заранее планировать объем хранения и резервирование. Рекомендуется оценивать рост данных на 20–40% в год и включать механизмы архивирования старых записей без снижения производительности основных операций.
Настройка процессов извлечения, трансформации и загрузки данных (ETL)
Для корректной интеграции данных необходимо определить последовательность ETL-процессов. Процесс состоит из трех этапов: извлечение, трансформация и загрузка, каждый из которых требует точной настройки и контроля.
Этап извлечения включает:
- Определение источников данных и форматов файлов (CSV, JSON, XML, SQL-базы);
- Настройку периодичности выгрузки: пакетная загрузка для больших массивов и инкрементальная для ежедневных обновлений;
- Реализацию проверки целостности данных при выгрузке.
Этап трансформации включает:
- Преобразование типов данных и нормализация полей;
- Очистку и фильтрацию некорректных или дублирующихся записей;
- Агрегацию и расчет производных показателей для аналитики.
Этап загрузки в хранилище включает:
- Определение схемы таблиц и партиционирования;
- Настройку индексов для ускорения запросов;
- Логирование успешных и ошибочных загрузок для последующего анализа.
Рекомендуется внедрять автоматизированные мониторинговые системы для контроля выполнения ETL-процессов и своевременного уведомления о сбоях, что позволяет поддерживать актуальность данных и предотвращать накопление ошибок.
Обеспечение контроля качества данных и управления версиями

Контроль качества данных начинается с определения правил валидации: допустимые диапазоны значений, уникальность ключей, соответствие форматов. Рекомендуется внедрять автоматические проверки на уровне ETL для обнаружения некорректных записей до загрузки в хранилище.
Для анализа ошибок используются отчеты с указанием источника, типа нарушения и объема затронутых данных. Регулярный аудит позволяет снизить количество некорректных записей на 80–90% и предотвращает накопление ошибок.
Управление версиями данных требует фиксации изменений схем таблиц и исторических значений. Используется стратегия версионирования с хранением изменений на уровне строк или полей, что позволяет восстановить состояние данных на любую дату.
Внедрение метаданных о происхождении данных облегчает отслеживание цепочки их преобразований. Для критичных систем рекомендуется хранить лог изменений с указанием времени, автора и причины модификации, что обеспечивает прозрачность и контроль при анализе данных.
Внедрение инструментов анализа и визуализации для пользователей
После создания хранилища важно обеспечить аналитикам и менеджерам доступ к данным через удобные интерфейсы. Рекомендуется интеграция с BI-платформами, такими как Power BI, Tableau или Looker, для построения отчетов и дашбордов.
Для упрощения анализа целесообразно подготовить набор предопределенных метрик и агрегатов. Например, показатели продаж по регионам, конверсии рекламных кампаний, среднее время обработки заказов. Это снижает нагрузку на ETL и ускоряет получение результатов.
Необходим контроль доступа к данным. Таблица ниже демонстрирует пример распределения прав:
| Роль | Доступ к данным | Тип отчетов |
|---|---|---|
| Аналитик | Полный доступ к таблицам фактов и измерений | Детализированные дашборды, тренды, прогнозы |
| Менеджер отдела | Только агрегированные показатели своего подразделения | Сводные отчеты и KPI |
| Руководитель компании | Агрегированные данные по всем подразделениям | Консолидированные отчеты, сравнение периодов |
Рекомендуется автоматическая генерация обновлений дашбордов по расписанию и уведомления при изменении ключевых показателей, что позволяет своевременно реагировать на изменения в бизнес-процессах.
Вопрос-ответ:
Как определить, какие источники данных стоит включить в хранилище?
Для выбора источников необходимо провести инвентаризацию всех систем, которые генерируют данные: ERP, CRM, веб-аналитика, производственные базы, бухгалтерия. Каждое приложение анализируется по объему данных, формату и частоте обновления. Затем выделяются показатели, критичные для аналитики: продажи по продуктам, посещаемость сайта, производственные метрики. После этого формируется список приоритетных источников для интеграции в хранилище.
Как выбрать между облачным, локальным и гибридным хранилищем?
Выбор зависит от требований к масштабированию, безопасности и затратам. Облачные платформы, например AWS Redshift или Google BigQuery, позволяют легко расширять ресурсы при росте объемов данных, но подразумевают регулярные расходы на хранение и передачу информации. Локальные серверы дают полный контроль над данными и соответствие нормативам, но требуют инвестиций в оборудование и администрирование. Гибридная схема объединяет оба подхода: критичные данные остаются локально, а аналитические массивы размещаются в облаке. Необходимо оценить прогнозируемый рост данных и нагрузку на аналитические запросы, чтобы подобрать оптимальное сочетание.
Какие методы организации таблиц ускоряют доступ к данным?
Для аналитических задач применяются схемы «звезда» и «снежинка», где есть таблица фактов и таблицы измерений. Это снижает количество соединений при запросах. Партиционирование больших таблиц по датам или категориям уменьшает время выборки. Индексация ключевых полей ускоряет поиск и объединение таблиц, а комбинированное использование нормализованных и денормализованных данных позволяет хранить историю и одновременно быстро получать агрегаты для отчетов.
Как настроить ETL-процессы для разных типов данных?
Сначала определяется источник и формат данных: SQL-базы, JSON, CSV, XML. Извлечение проводится пакетно для больших объемов и инкрементально для обновлений. На этапе трансформации выполняется очистка, фильтрация, проверка уникальности и типизация полей. Далее данные загружаются в хранилище с учетом схемы таблиц, индексов и партиционирования. Для контроля ошибок на каждом этапе полезно вести лог с указанием источника и причины отклонений.
Какие инструменты аналитики лучше подключать к хранилищу?
Для визуализации и анализа подходят BI-платформы вроде Power BI, Tableau или Looker. Рекомендуется подготовить набор готовых метрик и агрегатов: продажи по регионам, конверсии рекламных кампаний, среднее время обработки заказов. Настройка прав доступа к таблицам позволяет разграничить данные для аналитиков, руководителей отделов и топ-менеджмента. Автоматическая генерация дашбордов и уведомления о изменении ключевых показателей помогают быстрее реагировать на отклонения.
Как определить оптимальный способ хранения данных для разных отделов компании?
Для разных подразделений стоит анализировать объемы данных, частоту обновления и требования к безопасности. Например, бухгалтерия и юридический отдел чаще работают с конфиденциальной информацией, поэтому локальное хранение или гибрид с локальной частью предпочтительнее. Маркетинг и аналитика могут использовать облачные решения для быстрого масштабирования и обработки больших объемов логов и веб-данных. Важно оценить прогнозируемый рост информации и нагрузку на запросы, чтобы выбрать подходящий тип хранилища для каждого отдела.
Какие меры контроля качества данных позволяют минимизировать ошибки в аналитике?
Контроль качества включает проверку корректности форматов, уникальности ключевых полей и полноты данных. На этапе ETL рекомендуется внедрять скрипты для очистки дубликатов, фильтрации некорректных значений и преобразования типов. Логирование ошибок с указанием источника и причины позволяет отслеживать проблемные участки. Дополнительно полезно версионировать данные, чтобы можно было восстановить прежние состояния таблиц и анализировать изменения без потери информации. Регулярные проверки и автоматические уведомления помогают быстро выявлять и исправлять нарушения целостности данных.