Содержание статьи

Коэффициент достоверности аппроксимации R2 (или R-квадрат) широко используется в статистике для оценки качества моделей, основанных на регрессии. Он измеряет, насколько хорошо линейная модель объясняет вариацию зависимой переменной. Значение R2 варьируется от 0 до 1, где 1 указывает на полное объяснение вариации, а 0 на отсутствие объясняющей силы модели.
R2 не является абсолютным показателем качества модели. Например, в случае сложных зависимостей или малых выборок R2 может демонстрировать завышенные значения, что создаёт ложное ощущение высокой точности модели. В таких случаях стоит учитывать дополнительные метрики, такие как RMSE (среднеквадратическая ошибка), для более точной оценки.
Особенно важно понимать, что значение R2 может быть негативным, если модель не учитывает основные закономерности данных. Это указывает на то, что линейная модель хуже простой модели, основанной на среднем значении зависимой переменной. Важно помнить, что высокое значение R2 не всегда гарантирует хорошую прогностическую способность модели.
Рекомендуется использовать коэффициент R2 в сочетании с другими статистическими тестами и графическим анализом остатков, чтобы выявить возможные проблемы в модели, такие как автокорреляция или гетероскедастичность. Это позволит более точно оценить качество прогноза и избежать ошибок при интерпретации результатов.
Как интерпретировать значение R2 в контексте линейной регрессии

Коэффициент R2 в линейной регрессии показывает долю дисперсии зависимой переменной, которая объясняется моделью. Он вычисляется как отношение объяснённой дисперсии к общей дисперсии. Значение R2, равное 1, означает, что модель идеально прогнозирует зависимую переменную. Однако, даже при высоком R2, модель не всегда будет хорошо предсказывать новые данные, если она переобучена.
Значение R2 = 0.8 означает, что модель объясняет 80% вариации зависимой переменной. Остальные 20% остаются необъяснёнными. Однако это не означает, что ошибка прогноза составляет 20%. Важно учитывать, что наличие ошибок может не означать плохую модель, если остаточные ошибки случайны и не систематичны.
Значение R2 < 0.5 указывает на то, что модель объясняет менее половины вариации данных. В таких случаях может быть полезно добавить дополнительные переменные или рассмотреть использование другой модели. Тем не менее, низкий R2 не всегда свидетельствует о бесполезности модели – он может быть нормальным для сложных или шумных данных.
При интерпретации R2 важно учитывать контекст задачи и природу данных. Например, в социальных науках и экономике R2 может быть значительно ниже, чем в точных науках, и это не обязательно означает плохую модель. Иногда в таких областях модель с R2 около 0.3-0.4 уже может быть полезной, если объясняемые факторы сильно влияют на результаты, но не полностью их детерминируют.
Почему R2 не всегда отражает качество модели
- Переобучение (overfitting): Модель может показывать высокий R2, если она слишком точно подогнана под тренировочные данные, включая шум или случайные колебания. В таких случаях R2 не отражает способность модели к обоснованному прогнозированию на новых данных.
- Линейность модели: R2 измеряет только качество линейной аппроксимации, поэтому для сложных нелинейных зависимостей он может быть недостаточным. Модели, которые лучше отражают реальные отношения (например, полиномиальные или деревья решений), могут иметь низкий R2, несмотря на хорошее качество прогноза.
- Неоднородность данных: В некоторых случаях данные могут быть неоднородными или содержать выбросы, что делает использование R2 менее информативным. Модель, которая плохо справляется с выбросами, может иметь низкий R2, даже если её предсказания для большинства наблюдений точны.
- Равновесие между ошибками: Даже при высоком значении R2 модель может иметь большую ошибку прогноза для определённых подмножеств данных. Например, модель может хорошо работать в одной области значений, но плохо – в другой, что делает общий R2 неполным индикатором её реальной прогностической способности.
Важно помнить, что для более точной оценки качества модели следует использовать другие метрики, такие как среднеквадратичная ошибка (MSE), средняя абсолютная ошибка (MAE) или проверка остаточных ошибок. Эти показатели дают более полное представление о том, насколько модель будет успешной при работе с новыми данными.
Как определить, является ли высокий R2 индикатором хорошей модели

- Проверка на переобучение (overfitting): Высокий R2 может быть результатом переобучения, когда модель подгоняет данные слишком точно, включая шум. Для проверки этого стоит использовать кросс-валидацию и оценить, как модель работает на разных подмножествах данных. Если модель показывает высокие результаты на тренировочных данных, но плохо справляется с тестовыми, это признак переобучения.
- Реальные данные и выбросы: В некоторых случаях высокий R2 может быть достигнут за счёт плохой обработки выбросов или необычных значений. Чтобы избежать искажения, стоит проанализировать остатки и убедиться, что модель правильно учитывает все особенности данных. Важно, чтобы остатки распределялись случайным образом, без признаков систематической ошибки.
- Контекст задачи: Высокий R2 не всегда гарантирует хорошее качество модели, особенно в задачах с большим количеством факторов, влияющих на результат. Например, в экономике или социальных науках R2 может быть ниже 0.5, и это всё равно будет приемлемым показателем. Важно оценивать R2 в контексте области применения модели.
- Проверка других метрик: Даже при высоком R2 модель может иметь значительные ошибки прогноза. Использование других метрик, таких как среднеквадратичная ошибка (MSE) или средняя абсолютная ошибка (MAE), поможет оценить, насколько точными являются предсказания модели.
Таким образом, высокий R2 не всегда означает, что модель хороша. Для окончательной оценки стоит учитывать дополнительные факторы, такие как качество остатков, переобучение и проверку модели на новых данных. Только комплексный подход позволит дать точную оценку её качества.
Что означает отрицательное значение R2 и когда оно возможно
Отрицательное значение R2 встречается реже, чем положительные, но оно имеет важное значение для интерпретации результатов регрессионного анализа. Если коэффициент R2 отрицателен, это означает, что модель хуже, чем простая модель, которая использует только среднее значение зависимой переменной для предсказаний. Это может указывать на значительные проблемы с моделью или с данными.
Отрицательное значение R2 возможно в следующих случаях:
- Модель не объясняет вариацию данных: Когда модель не способна адекватно подогнать данные, остаточная ошибка будет велика, и R2 может быть отрицательным. Это означает, что модель дает худшие прогнозы, чем просто использование среднего значения зависимой переменной.
- Неверно выбранная модель: Если используется неподходящий тип модели (например, линейная модель для нелинейных данных), она может не уловить основные зависимости, и R2 окажется отрицательным.
- Ошибки в данных: Наличие выбросов или неправильно подготовленных данных может привести к неправильной подгонке модели и получению отрицательного значения R2. Это также может происходить из-за ошибок в предобработке или неверной спецификации модели.
Негативное значение R2 сигнализирует о проблемах, которые следует устранить до того, как продолжить использование модели. Важно понимать, что это не просто низкая оценка модели, а явный признак того, что модель не выполняет свою функцию должным образом.
| Причина | Возможное решение |
|---|---|
| Неверная спецификация модели | Пересмотрите выбор модели, возможно, стоит использовать более сложную или другую модель (например, полиномиальную регрессию). |
| Неадекватная предобработка данных | Проверьте наличие выбросов и их влияние на модель, а также корректность нормализации и обработки данных. |
| Плохая подгонка модели | Используйте более подходящие методы для нахождения параметров модели, или попробуйте другую технику машинного обучения. |
Таким образом, отрицательное значение R2 всегда должно быть сигналом для пересмотра модели или данных, поскольку оно указывает на существенные проблемы, требующие исправления.
Как использовать R2 для сравнения моделей с разными наборами данных

Коэффициент R2 может быть полезным инструментом при сравнении качества разных моделей, но важно учитывать, что он сам по себе не всегда даёт полную картину. При сравнении моделей с разными наборами данных стоит обратить внимание на несколько ключевых аспектов.
- Сравнение моделей на одном наборе данных: Если модели обучены на одном и том же наборе данных, R2 помогает напрямую оценить, какая из них лучше объясняет вариацию зависимой переменной. Модель с более высоким R2 будет показывать большую способность предсказывать данные, при условии, что она не переобучена.
- Сравнение моделей на разных наборах данных: Когда модели обучаются на разных наборах данных, важно учитывать, что коэффициент R2 будет зависеть от характеристик этих данных. Например, если один набор данных содержит больше шума или выбросов, R2 модели на этом наборе может быть ниже. В таких случаях стоит дополнительно анализировать остаточные ошибки и учитывать контекст данных.
- Использование кросс-валидации: Для более надёжного сравнения моделей на разных наборах данных рекомендуется использовать кросс-валидацию. Это позволит оценить, как модель будет работать на новых, не входящих в тренировочную выборку, данных. Важно, чтобы модели проходили одинаковые этапы валидации, чтобы результат сравнения был объективным.
- Рассмотрение других метрик: R2 не всегда достаточен для полноценного сравнения. Модели, которые имеют схожие значения R2, могут сильно отличаться по точности предсказаний. Поэтому дополнительно стоит использовать такие метрики, как среднеквадратичная ошибка (MSE) или средняя абсолютная ошибка (MAE), чтобы оценить не только качество аппроксимации, но и точность прогноза.
При сравнении моделей на разных наборах данных важно помнить, что R2 нужно воспринимать в контексте специфики каждого набора. Высокий R2 на одном наборе данных не гарантирует аналогичного результата на другом, особенно если наборы имеют разные распределения или содержат разные типы ошибок. Тщательное использование дополнительных метрик и кросс-валидации поможет более точно оценить способности моделей.
Ограничения коэффициента R2 при анализе сложных зависимостей
Коэффициент R2, несмотря на свою популярность, имеет несколько ограничений, особенно когда речь идет о сложных зависимостях между переменными. В таких случаях использование только этого показателя может ввести в заблуждение и не дать полной картины качества модели.
- Ограничение на линейность: R2 отражает качество линейной модели, и его значение может быть некорректным при анализе нелинейных зависимостей. В случае сложных нелинейных отношений между переменными R2 может не отражать реальную способность модели предсказывать зависимую переменную. В таких случаях стоит использовать другие метрики или модели, такие как полиномиальная регрессия, деревья решений или нейронные сети.
- Не учитывает взаимозависимости между переменными: При наличии нескольких независимых переменных с сильными взаимодействиями (например, мультиколлинеарности) R2 может показывать высокое значение, несмотря на то, что модель плохо обрабатывает связи между переменными. В таких случаях важно дополнительно оценить степень мультиколлинеарности или использовать методы, которые не зависят от линейных предположений, такие как метод главных компонент (PCA).
- Не учитывает сложность модели: Высокий R2 не всегда означает, что модель является оптимальной. Особенно при использовании сложных моделей (например, с большим числом параметров) существует риск переобучения, при котором модель будет подгонять данные, но плохо работать на новых, не входящих в тренировочную выборку, данных. В таких случаях важно использовать методы регуляризации или кросс-валидацию для проверки устойчивости модели.
Вопрос-ответ:
Что означает коэффициент достоверности аппроксимации R² в статистике?
Коэффициент R² показывает, насколько хорошо модель описывает реальные данные. Он отражает долю вариации зависимой переменной, объясняемую выбранной моделью. Например, значение R² = 0,85 означает, что 85% изменений результирующего показателя объясняются независимыми переменными, включёнными в модель.
Может ли коэффициент R² быть отрицательным?
Да, это возможно, если модель построена неудачно. Обычно R² находится в пределах от 0 до 1, но при использовании моделей, не проходящих через исходные данные или при отсутствии константы, значение может быть отрицательным. Это указывает на то, что модель описывает данные хуже, чем простое среднее значение.
Почему высокий R² не всегда означает хорошую модель?
Высокое значение R² не гарантирует, что модель подходит для прогнозирования или анализа. Модель может «подгоняться» под конкретные данные, теряя способность работать с новыми наблюдениями. Это называют переобучением. Чтобы оценить качество модели, дополнительно используют статистические тесты, анализ остатков и проверку на новых выборках.
Чем отличается скорректированный R² от обычного?
Скорректированный коэффициент R² учитывает количество переменных в модели и размер выборки. В отличие от обычного R², он может уменьшаться, если добавленные факторы не улучшают объясняющую способность модели. Это помогает избежать избыточного включения переменных и выбрать действительно значимые признаки.
Какое значение R² считается хорошим?
Единого «нормативного» значения нет — допустимый уровень зависит от предметной области и типа данных. В технических измерениях R² выше 0,9 может считаться отличным результатом, а в экономике или социологии уже 0,5 нередко воспринимается как приемлемое качество модели. Главное — оценивать R² вместе с другими показателями и контекстом исследования.
Почему при одинаковых данных разные модели могут иметь разные значения R²?
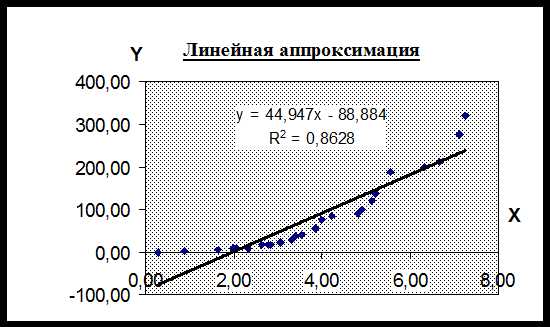
Разница в значениях R² связана с тем, как именно модель описывает взаимосвязь между переменными. Линейная, квадратичная или экспоненциальная аппроксимация дают разные результаты, так как каждая по-своему приближает экспериментальные точки. Если форма модели ближе к реальной зависимости, R² будет выше, что говорит о лучшем соответствии данных выбранной функции.
Можно ли использовать R² для сравнения моделей, построенных на разных данных?
Нет, напрямую сравнивать такие модели по R² нельзя. Этот показатель зависит от разброса исходных значений и масштаба выборки. Если данные собраны при разных условиях или относятся к разным процессам, сравнение теряет смысл. Корректнее оценивать R² только в пределах одной задачи и одного набора наблюдений, где сохраняются одинаковые предпосылки и структура данных.