Содержание статьи

Атрибут базы данных представляет собой конкретное свойство записи и определяет формат и структуру хранимой информации. Например, атрибут «дата_рождения» в таблице клиентов позволяет вычислять возраст пользователя автоматически, а атрибут «статус_заказа» облегчает фильтрацию активных и завершенных заказов.
Использование ключевых атрибутов обеспечивает точную идентификацию записей и поддержание связей между таблицами. Первичный ключ гарантирует уникальность каждой строки, а внешний ключ позволяет строить связи, например, между таблицей заказов и таблицей клиентов, без нарушения целостности данных.
Ограничения атрибутов повышают точность информации. NOT NULL исключает пустые значения в критичных полях, UNIQUE предотвращает дублирование, а CHECK задает допустимые диапазоны или форматы. Эти меры снижают количество ошибок и упрощают проверку корректности данных.
Атрибуты также помогают ускорить обработку и поиск информации. Индексация по полям, таким как номер заказа или код продукта, сокращает время выборки и фильтрации. Вычисляемые атрибуты, основанные на других полях, позволяют получать готовые результаты без дополнительных вычислений на стороне приложения.
Выбор типа атрибута для хранения конкретных данных

Тип атрибута определяет, какие данные и в каком формате можно хранить в таблице. Неправильный выбор типа приводит к ошибкам при вводе, перерасходу памяти и замедлению работы запросов. Например, для хранения числовых значений лучше использовать INT или DECIMAL, а для текстовой информации – VARCHAR или TEXT.
Рекомендуется выбирать типы атрибутов с учётом максимальной длины и точности данных. Для идентификаторов пользователей оптимально использовать BIGINT, чтобы избежать переполнения при росте базы. Для даты и времени подходят DATE и TIMESTAMP, что упрощает сортировку и расчёт интервалов.
| Тип атрибута | Применение | Рекомендации |
|---|---|---|
| INT | Целые числа, идентификаторы | Использовать для уникальных ID, диапазон до 2,1 млрд |
| DECIMAL(10,2) | Финансовые значения, цены | Указывать точность и масштаб для расчётов |
| VARCHAR(255) | Короткие текстовые поля, имена | Ограничивать длину, чтобы экономить память |
| TEXT | Длинные текстовые данные, описания | Использовать для больших блоков текста, индексацию применять с ограничением |
| DATE / TIMESTAMP | Дата и время событий | Выбирать в зависимости от необходимости хранения времени |
При выборе типа атрибута также важно учитывать частоту обновления и объём данных. Для больших таблиц рекомендуется минимизировать размер полей, чтобы ускорить выборку и снизить нагрузку на диск.
Использование ключевых атрибутов для связи таблиц
Ключевые атрибуты обеспечивают целостность данных и позволяют строить связи между таблицами. Первичный ключ задаёт уникальный идентификатор для каждой записи, исключая дубли и обеспечивая точное обращение к строкам.
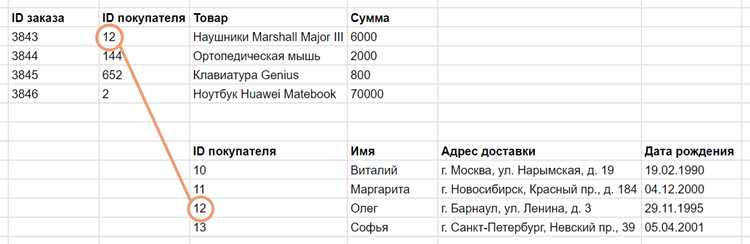
Внешний ключ связывает таблицы, указывая на первичный ключ другой таблицы. Например, в таблице заказов атрибут customer_id ссылается на первичный ключ таблицы клиентов, что гарантирует, что каждый заказ привязан к существующему пользователю.
При настройке внешнего ключа важно учитывать правила каскадного обновления и удаления. ON UPDATE CASCADE автоматически обновляет значения в дочерней таблице при изменении первичного ключа, а ON DELETE RESTRICT предотвращает удаление родительской записи, если на неё ссылаются другие таблицы.
Для оптимизации работы с ключами рекомендуется индексировать внешние ключи. Это ускоряет соединение таблиц в запросах JOIN и уменьшает нагрузку на базу при проверке ссылочной целостности.
Настройка ограничений уникальности и целостности данных

Ограничения атрибутов обеспечивают точность и непротиворечивость данных. Они предотвращают дублирование, пропуски и нарушение логики взаимосвязей между таблицами.
Основные типы ограничений:
- NOT NULL – запрещает пустые значения в критичных полях. Например, поле email в таблице пользователей должно быть всегда заполнено.
- UNIQUE – гарантирует уникальность значения в столбце. Подходит для идентификаторов, номеров заказов или серийных кодов.
- PRIMARY KEY – объединяет уникальность и отсутствие пустых значений. Используется для идентификации каждой записи.
- FOREIGN KEY – поддерживает ссылочную целостность между таблицами. Например, product_id в таблице заказов должен существовать в таблице продуктов.
- CHECK – задаёт допустимые диапазоны или форматы значений. Например, age >= 0 AND age <= 120.
Рекомендации по настройке ограничений:
- Выбирать ограничение в зависимости от логики бизнеса и критичности поля.
- Для больших таблиц комбинировать UNIQUE с индексами для ускорения поиска.
- Использовать FOREIGN KEY с каскадными правилами ON UPDATE и ON DELETE, чтобы поддерживать целостность при изменениях.
- Применять CHECK для числовых и текстовых полей с фиксированными форматами или диапазонами.
Применение атрибутов для индексации и ускорения поиска
Индексация атрибутов ускоряет выборку данных в таблицах с большим объёмом записей. Индексы создаются на колонках, по которым выполняются частые фильтры, сортировки и соединения таблиц. Например, атрибут «order_date» в таблице заказов позволяет быстро получать все заказы за конкретный период.
Для числовых и строковых атрибутов рекомендуется использовать B-TREE индекс, который поддерживает диапазонные запросы и сортировку. Для текстовых полей с полнотекстовым поиском применяются FULLTEXT индексы, обеспечивающие быстрый поиск по ключевым словам.
При работе с индексами важно учитывать нагрузку на запись и обновление данных. Создание индекса на колонке, которая часто изменяется, увеличивает время вставки и обновления. Рекомендуется индексировать только те атрибуты, которые активно используются в запросах.
Для составных запросов эффективны комбинированные индексы. Например, индекс на (customer_id, order_date) ускоряет выборку заказов конкретного клиента за указанный период без необходимости отдельной фильтрации по каждому атрибуту.
Регулярный анализ использования индексов позволяет выявлять неэффективные и устаревшие индексы, освобождая ресурсы и повышая производительность базы данных.
Использование вычисляемых атрибутов в запросах

Вычисляемые атрибуты позволяют получать значения на основе других колонок без необходимости сохранять результат в отдельном поле. Например, в таблице заказов можно создать атрибут total_price, который вычисляется как quantity * unit_price при каждом запросе.
Использование вычисляемых атрибутов снижает избыточное хранение данных и упрощает обновление информации. При изменении исходных колонок значения вычисляемых атрибутов автоматически отражают актуальные данные.
Для оптимизации запросов рекомендуется применять вычисляемые атрибуты с индексами только в критичных полях. Например, вычисление discounted_price в запросах с фильтром по цене может быть индексировано для ускорения выборки крупных таблиц.
В SQL вычисляемые атрибуты задаются через выражения в SELECT или с использованием GENERATED COLUMN. Пример: SELECT quantity, unit_price, (quantity * unit_price) AS total_price FROM orders; позволяет сразу получать итоговую стоимость заказа без отдельного поля.
Вычисляемые атрибуты удобны для аналитических отчётов. Например, profit_margin можно вычислять как (sale_price — cost_price) / sale_price, что позволяет строить динамические отчёты по рентабельности без дополнительных вычислений на стороне приложения.
Работа с атрибутами для фильтрации и сортировки записей
Атрибуты используются для точного отбора и упорядочивания данных в запросах. Например, фильтрация по атрибуту status в таблице заказов позволяет выделить только активные или завершённые заказы.
Для текстовых полей применяются условия =, LIKE, IN. Например, WHERE customer_name LIKE ‘Иван%’ выбирает всех клиентов, имена которых начинаются с «Иван». Для числовых и датированных атрибутов применяются диапазоны: BETWEEN, >, <, что позволяет отобрать значения в заданном интервале.
При работе с большими таблицами рекомендуется индексировать атрибуты, которые участвуют в фильтрах и сортировках. Это снижает время выполнения запросов и уменьшает нагрузку на сервер базы данных.
Для динамической фильтрации удобно использовать вычисляемые атрибуты. Например, атрибут total_price, вычисляемый как quantity * unit_price, позволяет фильтровать заказы по сумме без необходимости сохранять это значение в таблице.
Анализ влияния атрибутов на производительность базы данных
Размер и тип атрибутов напрямую влияют на скорость операций чтения и записи. Например, хранение больших текстовых блоков в TEXT вместо VARCHAR увеличивает нагрузку на диск и замедляет выборку.
Количество индексов на атрибутах также влияет на производительность. Каждый индекс ускоряет поиск по соответствующей колонке, но увеличивает время вставки и обновления. Оптимально индексировать только поля, используемые в фильтрах, сортировках и соединениях таблиц.
Часто изменяемые атрибуты стоит хранить в отдельных таблицах или использовать вычисляемые колонки, чтобы уменьшить нагрузку на основную таблицу. Например, поле total_price можно вычислять на лету для аналитики, вместо постоянного обновления при каждой модификации заказа.
Регулярный мониторинг статистики запросов позволяет выявить атрибуты, вызывающие узкие места. Использование инструментов, таких как EXPLAIN в SQL, помогает определить, какие колонки замедляют выборку и требуют оптимизации.
Сбалансированное сочетание типов данных, индексов и вычисляемых атрибутов снижает нагрузку на базу и ускоряет обработку запросов, особенно при больших объёмах данных и сложных соединениях таблиц.
Вопрос-ответ:
Что такое вычисляемый атрибут и когда его стоит использовать?
Вычисляемый атрибут — это колонка, значение которой формируется на основе других атрибутов таблицы через выражения или формулы. Его используют для получения данных без дополнительного хранения, например, расчёт итоговой стоимости заказа через умножение количества на цену за единицу. Такой подход уменьшает избыточность и автоматически отражает актуальные значения при изменении исходных данных. Вычисляемые атрибуты особенно полезны для аналитики и отчётов, где значения формируются динамически.
Как выбрать тип атрибута для текстовых данных в базе?
При выборе типа текстового атрибута учитывают предполагаемый размер данных и частоту обработки. Для коротких значений, таких как имена или коды, используют VARCHAR с ограничением длины, что экономит место и ускоряет выборку. Для больших блоков текста, например описаний или комментариев, применяют TEXT. Если планируется поиск по части текста, стоит рассмотреть полнотекстовые индексы. Важно избегать избыточной длины, чтобы не замедлять работу запросов и операции сортировки.
Какая разница между первичным и внешним ключом?
Первичный ключ назначается для уникальной идентификации каждой записи в таблице. Он запрещает дубли и пустые значения, обеспечивая однозначность строк. Внешний ключ используется для связи с другой таблицей и указывает на существующий первичный ключ. Он поддерживает ссылочную целостность: запрещает создание записей с несущестующими ссылками и позволяет управлять обновлениями и удалениями с помощью каскадных правил.
Как индексация атрибутов влияет на производительность базы данных?
Индексы ускоряют выборку данных по конкретным атрибутам, особенно при фильтрах, сортировках и соединениях таблиц. Например, индекс по дате заказа позволяет быстро получить записи за заданный период. Однако создание индексов увеличивает время вставки и обновления данных, так как индексы тоже нужно обновлять. Поэтому важно индексировать только колонки, активно используемые в запросах, и периодически проверять их влияние на нагрузку.
Какие ограничения атрибутов помогают поддерживать качество данных?
Для контроля качества данных применяются несколько типов ограничений: NOT NULL запрещает пустые значения, UNIQUE предотвращает дубли, PRIMARY KEY объединяет уникальность и обязательность, FOREIGN KEY поддерживает правильные связи между таблицами, а CHECK задаёт допустимые диапазоны или форматы значений. Эти ограничения позволяют исключить ошибки ввода и гарантируют корректность данных при массовых обновлениях и аналитике.