Содержание статьи

Оператор для вычисления максимального значения поля позволяет быстро определить наибольшее значение в наборе данных без необходимости сортировки или ручного сравнения. В SQL это реализуется через MAX(), а в системах анализа данных, таких как Pandas, используется метод max() для серии или столбца DataFrame. Его применение снижает нагрузку на сервер и ускоряет агрегацию больших объемов информации.
Важно учитывать тип данных поля: для числовых типов оператор возвращает фактическое максимальное значение, для строковых – наибольшее значение в алфавитном порядке. При работе с датами MAX() возвращает самую позднюю дату, что особенно полезно для анализа временных рядов или логов событий. Некорректный тип данных может привести к ошибкам или неожиданным результатам.
При использовании оператора в сочетании с группировкой через GROUP BY можно одновременно получать максимальные значения для разных категорий. Например, определить самую высокую цену по каждому продукту или максимальный балл в каждой группе студентов. В больших базах данных рекомендуется индексировать поле, по которому вычисляется максимум, чтобы сократить время выполнения запроса.
Для динамических фильтров оператор легко интегрируется в подзапросы, позволяя получать максимальное значение с учетом условий. Например, можно вычислить максимальную зарплату среди сотрудников отдела или наибольшее количество продаж за определенный период. Такой подход снижает дублирование кода и повышает читаемость аналитических запросов.
Выбор подходящего оператора для числовых и текстовых полей
При работе с текстовыми полями MAX() ориентируется на лексикографический порядок Unicode. Это важно учитывать: строки с заглавными буквами будут восприниматься как «меньшие», чем строки с прописными буквами, а строки с цифрами в начале займут отдельное место в сортировке. Для выбора оператора MAX() по тексту рекомендуется предварительно нормализовать данные, используя функции приведения регистра или удаления лишних символов.
Если необходимо определить максимальное значение по дате или времени, MAX() корректно работает только с полями, хранящими значения в стандартном формате ISO или timestamp. Любые нестандартные форматы даты перед использованием оператора требуют преобразования в поддерживаемый тип.
Для комбинированного анализа, когда поле может содержать как текст, так и числа, допустимо создавать вспомогательные поля с явным типом данных. Это позволяет оператору MAX() возвращать корректные результаты, исключая некорректное сравнение чисел и строк.
При выборе оператора важно учитывать размер и индексирование поля. Для больших таблиц числовые поля с индексом обеспечивают мгновенный расчет максимального значения, в то время как текстовые поля без индекса могут замедлить выполнение запроса. Поэтому для текстовых полей с большим объемом данных рекомендуется использовать отдельные индексированные колонки с нормализованными строками.
Синтаксис запроса для извлечения максимального значения в SQL
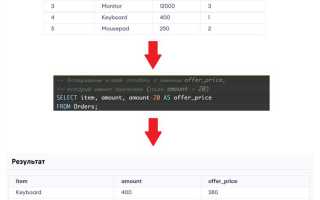
Для получения максимального значения конкретного поля в SQL используется агрегатная функция MAX(). Общий синтаксис запроса выглядит так:
SELECT MAX(имя_поля) FROM имя_таблицы;
Если необходимо ограничить выборку определенными условиями, применяется оператор WHERE. Например, чтобы получить максимальный доход среди сотрудников отдела «Продажи»:
SELECT MAX(доход) FROM сотрудники WHERE отдел = 'Продажи';
Для извлечения максимального значения вместе с другими полями используется GROUP BY. Это позволяет определить максимальные значения по категориям. Пример:
SELECT отдел, MAX(доход) FROM сотрудники GROUP BY отдел;
Важно учитывать, что MAX() игнорирует значения NULL. Если поле содержит NULL, они не влияют на результат. Для числовых и датированных полей функция работает одинаково, возвращая наибольшее существующее значение.
При объединении с сортировкой можно использовать ORDER BY и LIMIT для извлечения верхней записи, хотя это менее эффективно, чем прямой вызов MAX(). Например:
SELECT доход FROM сотрудники ORDER BY доход DESC LIMIT 1;
Функция MAX() поддерживается всеми основными СУБД: MySQL, PostgreSQL, Oracle, SQL Server. В Oracle для работы с группировками часто применяют HAVING для фильтрации агрегатных результатов:
SELECT отдел, MAX(доход) FROM сотрудники GROUP BY отдел HAVING MAX(доход) > 100000;
Использование агрегатной функции MAX() в разных СУБД

Функция MAX() позволяет получить наибольшее значение в столбце и применяется во всех популярных СУБД, однако синтаксис и возможности могут различаться.
В MySQL функция MAX() используется стандартно: SELECT MAX(column_name) FROM table_name;. Для работы с группировкой используется GROUP BY, а при работе с датами важно учитывать формат столбца – строковые даты потребуют преобразования через STR_TO_DATE() для корректного сравнения.
В PostgreSQL MAX() поддерживает те же возможности, что и в MySQL, но позволяет использовать фильтры через конструкцию FILTER (WHERE condition). Это позволяет получать максимальные значения с условием без необходимости использования подзапросов.
В Oracle синтаксис идентичен стандартному SQL: SELECT MAX(column_name) FROM table_name;. Для числовых и символьных столбцов важно учитывать сортировку NLS (National Language Support), чтобы корректно определять максимальные значения в многоязычных наборах данных.
В SQL Server MAX() поддерживает работу с OVER(PARTITION BY ...), что позволяет получать максимальное значение по каждой группе строк без использования отдельного агрегирования. Для datetime столбцов рекомендуется явное приведение типов при сравнении с литералами.
Рекомендации при работе с MAX() в разных СУБД:
- Проверяйте тип столбца: числовые, символьные и даты обрабатываются по-разному.
- Используйте
GROUP BYилиPARTITION BYдля групповых вычислений. - В PostgreSQL применяйте
FILTERдля условного вычисления максимума без подзапросов. - В Oracle учитывайте настройки сортировки NLS для символьных данных.
- Для больших таблиц используйте индекс на столбец, по которому вычисляется MAX(), чтобы ускорить выполнение запроса.
Различия между СУБД чаще всего касаются работы с фильтрацией и типами данных, поэтому при переносе запросов MAX() между системами необходимо учитывать особенности обработки строк и дат.
Фильтрация данных перед применением оператора MAX()
Перед использованием функции MAX() важно ограничить набор данных до релевантных записей. Например, если нужно найти максимальную цену продукта в конкретной категории, следует применять условие WHERE, фильтрующее записи по категории, чтобы исключить товары из других сегментов. Неправильная фильтрация может привести к выбору максимального значения, которое не отражает нужный контекст.
Для временных интервалов фильтруйте данные по датам через условия типа `BETWEEN` или `>=`/`<=`. Если в таблице есть пропущенные значения, их необходимо исключить через `IS NOT NULL`, иначе MAX() может вернуть неожиданный результат. Это особенно важно для числовых полей, где NULL трактуется как отсутствие значения, а не как ноль.
При работе с большими таблицами рекомендуется применять фильтры до агрегации, чтобы снизить нагрузку на базу данных. Например, сначала выбрать только записи текущего года, а затем вычислить максимальное значение. Использование индексов по полям фильтра ускоряет выполнение запроса и делает выборку более точной.
Для сложных условий можно комбинировать фильтры через AND/OR. Например, если нужно получить максимальную цену для определенного поставщика и конкретного типа товара, фильтры по полю `supplier_id` и `product_type` помогут исключить лишние строки до применения MAX(). Это гарантирует корректность вычисления и точное соответствие бизнес-логике.
Дополнительно стоит проверять типы данных: фильтры должны соответствовать типу столбца, иначе MAX() может работать некорректно. Для числовых значений избегайте строковых сравнений, а для дат используйте стандартные форматы базы данных. Правильная фильтрация на этапе подготовки данных делает оператор MAX() максимально информативным и надежным.
Получение максимального значения с группировкой по категориям
Для анализа данных по категориям необходимо использовать оператор MAX совместно с GROUP BY. Это позволяет определить наибольшее значение в каждой группе, сохраняя структурированность данных. Например, при работе с таблицей Продажи для каждой категории продуктов можно получить максимальную цену товара.
Запрос должен включать столбец категории в GROUP BY и оператор MAX для вычисления максимального значения. Важно проверять тип данных, чтобы функция корректно сравнивала значения: для чисел и дат результат будет точным, для строк – определяется по алфавиту.
При использовании нескольких условий фильтрации оптимально применять WHERE до группировки. Это уменьшает объем обрабатываемых данных и ускоряет выполнение запроса. Например, ограничение по дате продаж позволяет получить актуальные максимальные показатели по каждой категории.
Если требуется дополнительная информация о строке, содержащей максимальное значение, рекомендуется использовать подзапрос или JOIN с исходной таблицей, чтобы извлечь все сопутствующие поля. Это важно для аналитических отчетов, где необходимо видеть не только максимум, но и связанные данные, такие как идентификатор товара или дата продажи.
Для повышения производительности следует индексировать поля, участвующие в GROUP BY и в вычислении MAX. Особенно эффективно это при работе с большими таблицами, где без индекса запрос может выполняться значительно медленнее.
Использование агрегирования с группировкой по категориям позволяет формировать точные отчеты по максимумам, выявлять лидеров в каждой группе и анализировать распределение значений без необходимости обработки каждой записи вручную.
Обработка пустых значений и NULL при поиске максимума
При вычислении максимального значения поля важно учитывать пустые значения и NULL, поскольку их наличие может изменить результат или вызвать ошибки в запросах и вычислениях.
Основные подходы обработки:
- Игнорирование NULL: большинство SQL-операторов MAX автоматически пропускают NULL. Например, если столбец содержит значения (5, NULL, 8), оператор вернет 8.
- Замена NULL на дефолтное значение: иногда полезно использовать функцию COALESCE, чтобы NULL преобразовать в минимальное значение или 0. Это гарантирует, что функция MAX всегда вернет число, даже если все записи NULL.
- Фильтрация данных: использование WHERE для исключения NULL перед вычислением максимума повышает точность анализа, особенно при сложных агрегатах.
- Использование условных выражений: в некоторых системах можно применять CASE, чтобы задавать особую обработку NULL. Например, CASE WHEN поле IS NULL THEN 0 ELSE поле END.
Рекомендации:
- Перед вычислением MAX проверить, сколько значений NULL в столбце. Если их большинство, лучше обработать их отдельно.
- При анализе финансовых или статистических данных заменяйте NULL на логически оправданное значение, чтобы не искажать максимум.
- Для отчетов с динамическими фильтрами используйте комбинированный подход: фильтрация NULL и замена оставшихся пустых значений через COALESCE.
- Документируйте выбранный метод обработки NULL, чтобы в будущем было понятно, как рассчитывается максимум и почему он может отличаться от простого подсчета.
Правильная обработка пустых значений гарантирует корректное определение максимума и предотвращает ошибки при агрегации и аналитике.
Сравнение максимального значения между несколькими таблицами
Для сравнения максимального значения одного и того же поля в разных таблицах используют объединение агрегатных функций с подзапросами. Например, если нужно определить наибольший заказ по сумме в таблицах sales_january и sales_february, применяют отдельные SELECT с MAX и объединяют их через GREATEST или UNION. Это позволяет избежать выборки всех записей и ускоряет выполнение при больших объемах данных.
Важно учитывать тип данных полей: числовые значения сравниваются напрямую, а даты требуют явного преобразования в одинаковый формат. При работе с текстовыми полями необходимо использовать длину строки или числовой идентификатор для корректного сравнения.
Для оптимизации запроса рекомендуется проверять наличие индексов на поле, из которого выбирается максимальное значение. Если индекса нет, выполнение MAX по всей таблице может быть затратным по времени. В сложных случаях используют материализованные представления, чтобы хранить уже вычисленные максимумы и обновлять их по мере поступления новых данных.
При объединении результатов нескольких таблиц важно учитывать возможные NULL-значения: агрегатная функция MAX их игнорирует, но при использовании GREATEST NULL может привести к некорректному результату. Решение – использовать COALESCE для подстановки минимального значения.
Для динамического сравнения между большим количеством таблиц целесообразно генерировать подзапросы программно или использовать CTE с последующим вычислением глобального максимума. Такой подход сокращает вероятность ошибок и упрощает поддержку запросов при расширении структуры базы данных.
В конечном итоге, сравнение максимального значения между таблицами требует строгого контроля типов данных, обработки NULL и оптимизации индексов для обеспечения корректности и производительности.
Вопрос-ответ:
Что делает оператор для получения максимального значения поля?
Оператор для получения максимального значения поля выбирает наибольшее значение из заданного набора данных по указанному признаку. Он позволяет быстро определить, какая запись имеет наибольший показатель в конкретной колонке таблицы, что полезно при анализе числовых данных, статистике или при составлении отчетов.
В каких случаях полезно применять этот оператор?
Оператор применяют, когда нужно определить наиболее высокое значение среди множества записей. Например, можно найти самую дорогую продукцию в каталоге, максимальную зарплату сотрудников или наибольший балл студента по тесту. Он упрощает анализ данных и помогает выделять лидирующие позиции в наборе информации.
Как правильно использовать оператор в запросе к базе данных?
Чтобы применить оператор, необходимо указать поле, для которого нужно определить максимальное значение. В SQL, например, используется конструкция SELECT MAX(название_поля) FROM название_таблицы. Это возвращает одно значение — наибольшее в выбранной колонке. При необходимости можно добавить условия фильтрации через WHERE, чтобы ограничить поиск конкретными записями.
Можно ли получить сразу запись с максимальным значением, а не только само значение?
Да, это возможно. Обычно сначала вычисляют максимальное значение поля, а затем используют его для фильтрации записи. Например, в SQL: SELECT * FROM таблица WHERE поле = (SELECT MAX(поле) FROM таблица). Такой подход возвращает все строки, где поле достигает наибольшего значения, что позволяет получить полный контекст записи.
Есть ли ограничения при использовании оператора MAX для разных типов данных?
Оператор работает только с упорядочиваемыми типами данных, такими как числа, даты или строки в некоторых СУБД. Он не применим к сложным объектам или массивам. Кроме того, в случае пустого набора данных результат может быть NULL, а при работе с текстом учитывается сортировка символов в алфавитном порядке.