Содержание статьи

Граф – это структура данных, состоящая из вершин и рёбер, которые описывают связи между элементами. Такой подход используется в задачах, где объекты взаимосвязаны: от построения маршрутов и сетевых топологий до анализа социальных взаимодействий и зависимостей между файлами в проекте.
В программировании графы часто представляют в виде списков смежности или матриц смежности. Первый вариант экономит память при разреженных графах, второй – ускоряет доступ к информации о связях. Выбор структуры зависит от частоты запросов и типа обрабатываемых данных.
Использование графов позволяет описывать сложные системы в виде понятных моделей. Например, алгоритмы поиска в глубину и ширину помогают анализировать маршруты, а методы Дейкстры и Беллмана–Форда вычисляют кратчайшие пути. Эти инструменты применяются в транспортных системах, планировании задач и работе рекомендательных сервисов.
Современные библиотеки, такие как NetworkX и Graph-tool в Python, дают возможность создавать, визуализировать и анализировать графы с минимальными усилиями. Они упрощают реализацию алгоритмов и позволяют сосредоточиться на логике решения, а не на технических деталях.
Представление графов в коде: списки смежности и матрицы
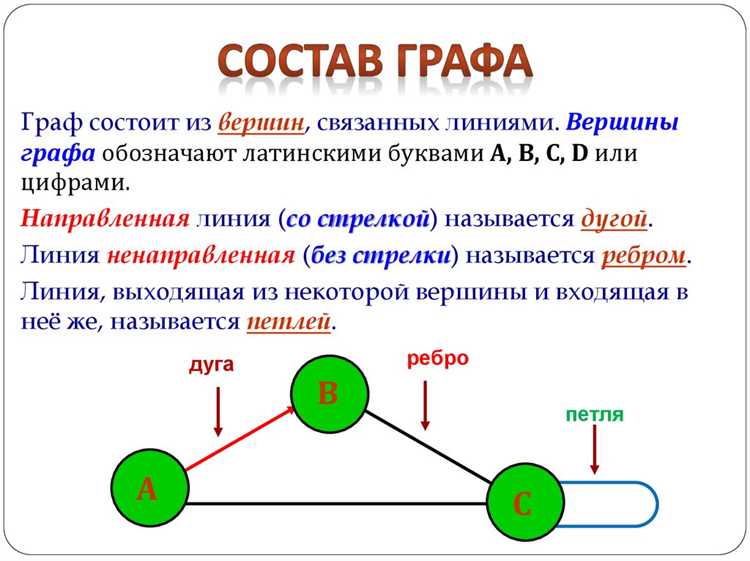
Граф можно хранить в программе разными способами, но чаще всего используют списки смежности и матрицы смежности. Оба метода позволяют описывать связи между вершинами, но различаются по памяти и скорости доступа к данным.
Список смежности представляет собой словарь или массив, где каждой вершине соответствует набор её соседей. Этот подход удобен при работе с разреженными графами, когда количество рёбер значительно меньше квадрата числа вершин. Добавление новых связей выполняется быстро, а объём памяти растёт пропорционально числу рёбер.
Матрица смежности – это квадратная таблица, в которой строки и столбцы соответствуют вершинам, а значения указывают наличие или вес ребра. Такой формат подходит для плотных графов, где большинство вершин соединены между собой. Основное преимущество – мгновенная проверка наличия связи между двумя элементами, что важно для задач с частыми запросами.
| Критерий | Список смежности | Матрица смежности |
|---|---|---|
| Память | Пропорциональна количеству рёбер | Пропорциональна квадрату числа вершин |
| Проверка наличия ребра | Медленнее (нужно искать соседа) | Быстрая (доступ по индексу) |
| Добавление вершины | Простое | Требует пересоздания матрицы |
| Подходит для | Разреженных графов | Плотных графов |
В Python списки смежности часто реализуют через словарь, где ключ – вершина, а значение – список соседей. Матрицы удобнее хранить с помощью библиотеки NumPy, особенно если граф имеет весовые рёбра и требуется быстро выполнять математические операции.
Различие между ориентированными и неориентированными графами
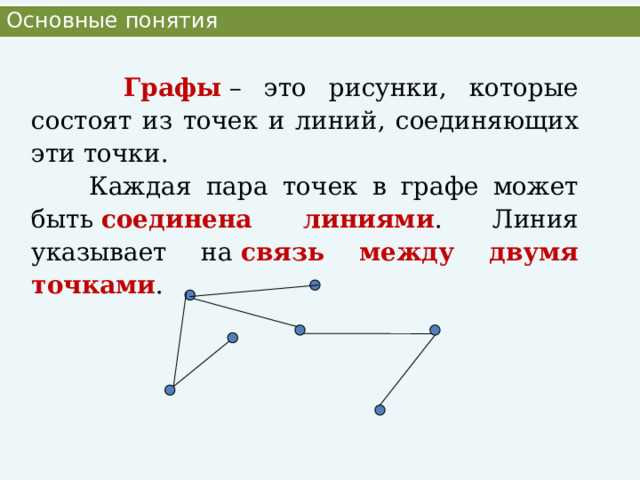
Граф может быть ориентированным или неориентированным. Главное различие заключается в том, имеют ли рёбра направление. В ориентированных графах каждое ребро указывает путь от одной вершины к другой, в неориентированных – связь считается двусторонней.
Ориентированные графы применяются там, где важно направление зависимости или потока данных. Примеры – маршрутизация запросов, анализ переходов между состояниями, построение иерархий. Неориентированные графы чаще используют для описания взаимных связей: социальных контактов, сетей дорог, соединений в инженерных схемах.
- Ориентированный граф хранит рёбра в виде упорядоченных пар (A → B). Если существует только одно ребро, то путь обратно (B → A) не гарантируется.
- Неориентированный граф хранит рёбра как неупорядоченные пары {A, B}, что означает взаимную доступность вершин.
Для реализации в коде различие проявляется в способе хранения связей:
- В ориентированном графе каждое направление добавляется отдельно – если требуется связь в обе стороны, нужно внести два ребра.
- В неориентированном достаточно одного ребра, которое автоматически учитывается в обеих вершинах списка смежности.
При работе с алгоритмами это различие влияет на поведение поиска, определение циклов и подсчёт степеней вершин. Например, в ориентированном графе различают входящую и исходящую степень, тогда как в неориентированном – только общую.
Выбор типа графа зависит от задачи: для направленных зависимостей и потоков данных подходит ориентированный вариант, для взаимных связей – неориентированный.
Поиск в глубину и поиск в ширину: как работают базовые алгоритмы
Поиск в глубину (DFS) и поиск в ширину (BFS) – два фундаментальных метода обхода графа. Оба алгоритма позволяют систематически посещать вершины, но используют разные стратегии движения по структуре.
Поиск в глубину продвигается как можно дальше вдоль одного пути, пока не достигнет вершины без непосещённых соседей, после чего возвращается назад. Его удобно реализовать с помощью рекурсии или стека. Такой подход подходит для анализа связности, поиска циклов и топологической сортировки.
Поиск в ширину исследует вершины слоями: сначала посещаются все соседи исходной вершины, затем их соседи и так далее. Для хранения вершин используется очередь. BFS применяют для нахождения кратчайших путей в невзвешенных графах и при моделировании пошаговых процессов.
Основные различия между алгоритмами:
- DFS использует стек или рекурсию, BFS – очередь.
- DFS подходит для задач, связанных с глубиной структуры, BFS – для поиска минимальных расстояний.
- DFS может использовать меньше памяти при узкой ветвистости, BFS – приоритетен, если важно исследовать все пути равномерно.
Пример реализации на Python:
def dfs(graph, start, visited=None):
if visited is None:
visited = set()
visited.add(start)
for neighbor in graph[start]:
if neighbor not in visited:
dfs(graph, neighbor, visited)
return visited
from collections import deque
def bfs(graph, start):
visited = set([start])
queue = deque([start])
while queue:
vertex = queue.popleft()
for neighbor in graph[vertex]:
if neighbor not in visited:
visited.add(neighbor)
queue.append(neighbor)
return visited
Выбор между DFS и BFS определяется структурой графа и типом задачи. Для анализа глубинных зависимостей эффективнее DFS, для поиска кратчайшего пути или минимального числа шагов – BFS.
Определение кратчайшего пути: алгоритмы Дейкстры и Беллмана–Форда
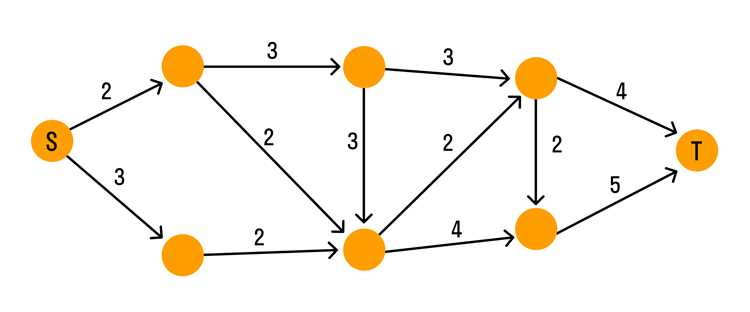
Поиск кратчайшего пути в графе необходим при решении задач маршрутизации, анализа сетей и моделирования зависимостей. Наиболее известные методы – алгоритм Дейкстры и алгоритм Беллмана–Форда. Оба вычисляют минимальную стоимость пути между вершинами, но различаются по условиям применения и сложности.
Алгоритм Дейкстры работает только с графами, где все веса рёбер неотрицательны. Он последовательно выбирает вершину с минимальной известной дистанцией, обновляет расстояния до соседей и фиксирует кратчайшие пути. Для ускорения часто используют приоритетную очередь из модуля heapq в Python.
Пример реализации алгоритма Дейкстры:
import heapq
def dijkstra(graph, start):
distances = {v: float('inf') for v in graph}
distances[start] = 0
queue = [(0, start)]
while queue:
current_distance, vertex = heapq.heappop(queue)
if current_distance > distances[vertex]:
continue
for neighbor, weight in graph[vertex]:
distance = current_distance + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
heapq.heappush(queue, (distance, neighbor))
return distances
Алгоритм Беллмана–Форда допускает отрицательные веса рёбер и выявляет отрицательные циклы. Он выполняет серию итераций по всем рёбрам, постепенно уточняя расстояния. Количество итераций не превышает числа вершин минус один. Если после этого хотя бы одно расстояние можно улучшить, значит граф содержит отрицательный цикл.
def bellman_ford(graph, start):
distances = {v: float('inf') for v in graph}
distances[start] = 0
for _ in range(len(graph) - 1):
for u in graph:
for v, w in graph[u]:
if distances[u] + w < distances[v]:
distances[v] = distances[u] + w
for u in graph:
for v, w in graph[u]:
if distances[u] + w < distances[v]:
raise ValueError("Обнаружен отрицательный цикл")
return distances
Алгоритм Дейкстры предпочтителен для сетей без отрицательных весов, где важна скорость. Беллман–Форд применяют при необходимости учитывать отрицательные рёбра или проверять корректность модели. Выбор зависит от характера данных и ограничений задачи.
Поиск циклов и связности в графах
Для проверки связности используют обход в глубину (DFS) или ширину (BFS). Если при запуске обхода из произвольной вершины удаётся посетить все остальные, граф считается связным. В ориентированных структурах применяют понятия сильной и слабой связности: сильная означает достижимость вершин в обоих направлениях, слабая – только при игнорировании направлений рёбер.
Для выявления циклов в неориентированном графе достаточно отслеживать, не ведёт ли очередное ребро к уже посещённой вершине, не являющейся родителем текущей. В ориентированном графе применяют DFS с отслеживанием вершин в текущем стеке рекурсии – если вершина повторно встречается в активном стеке, найден цикл.
Пример поиска цикла в ориентированном графе:
def has_cycle(graph):
visited = set()
stack = set()
def dfs(vertex):
visited.add(vertex)
stack.add(vertex)
for neighbor in graph[vertex]:
if neighbor not in visited:
if dfs(neighbor):
return True
elif neighbor in stack:
return True
stack.remove(vertex)
return False
for v in graph:
if v not in visited:
if dfs(v):
return True
return False
Для оценки структуры больших графов используют алгоритмы Косарайю и Тарьяна, которые выделяют сильно связные компоненты. Они позволяют разбить сложную сеть на отдельные группы вершин, внутри которых существуют взаимные пути, что упрощает анализ зависимостей и поиск аномалий.
Проверка связности и наличие циклов часто входят в этап валидации данных – особенно в системах зависимостей пакетов, графах задач и схемах вычислений. Эти проверки позволяют обнаружить логические ошибки и определить точки возможных зависаний в процессе выполнения.
Применение графов для моделирования социальных сетей и маршрутов
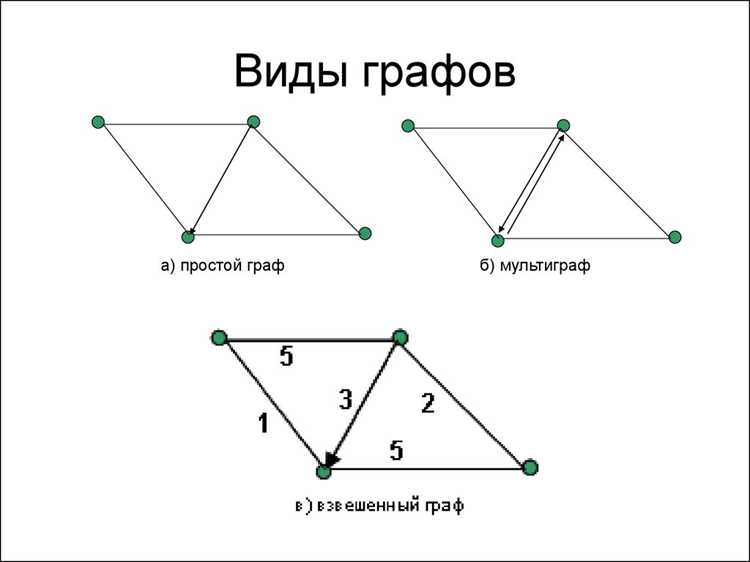
Примеры применения:
- Социальные сети:
- Выявление влиятельных пользователей через подсчёт степени вершины или центральности.
- Определение сообществ и групп с помощью алгоритмов поиска связных компонентов.
- Рекомендательные системы на основе кратчайших путей и общих соседей.
- Маршруты и транспорт:
- Поиск оптимального маршрута с использованием алгоритмов Дейкстры или Беллмана–Форда.
- Анализ загруженности сетей и выявление узких мест через циклы и связность.
- Моделирование альтернативных путей при авариях или ремонте дорог.
Для построения таких моделей используют списки смежности для разреженных сетей и матрицы смежности для плотных графов. В социальных сетях удобно хранить данные в виде словарей с наборами друзей, а в транспортных системах – использовать весовые рёбра для отражения времени или расстояния.
Практическая рекомендация: при работе с динамическими сетями или маршрутами стоит обновлять граф после изменений (новые пользователи, дороги, рейсы) и пересчитывать ключевые метрики только для затронутых частей, чтобы уменьшить вычислительную нагрузку.
Использование библиотек Python для работы с графами: NetworkX и Graph-tool
NetworkX – библиотека на Python для создания, анализа и визуализации графов. Она поддерживает ориентированные и неориентированные графы, позволяет хранить весовые и атрибутные рёбра, а также вершины. С помощью NetworkX удобно реализовывать DFS, BFS, алгоритмы Дейкстры, Беллмана–Форда и находить компоненты связности.
Пример создания графа и добавления рёбер:
import networkx as nx
G = nx.DiGraph()
G.add_edge('A', 'B', weight=5)
G.add_edge('B', 'C', weight=3)
distances = nx.single_source_dijkstra_path_length(G, 'A')
Graph-tool – более производительная библиотека, оптимизированная для больших графов. Она использует C++ на бэкенде и поддерживает параллельные вычисления. Graph-tool полезна при анализе больших социальных сетей, транспортных систем и сложных графовых моделей с тысячами вершин и рёбер.
Особенности Graph-tool:
- Высокая скорость операций с большими графами.
- Поддержка взвешенных и атрибутных рёбер.
- Встроенные алгоритмы для поиска циклов, центральности, кратчайших путей и кластеризации.
Рекомендация: использовать NetworkX для задач с небольшими и средними графами, где важна простота кода и быстрый прототип. Graph-tool подходит для анализа больших сетей и сложных вычислений, когда требуется производительность и работа с миллионами рёбер.
Вопрос-ответ:
В чем разница между списком смежности и матрицей смежности при хранении графа?
Список смежности хранит для каждой вершины список соседей, что экономит память при разреженных графах, где количество рёбер значительно меньше квадрата числа вершин. Матрица смежности — это квадратная таблица, где строки и столбцы соответствуют вершинам, а значения показывают наличие или вес ребра. Этот метод требует больше памяти, но позволяет мгновенно проверять наличие связи между двумя вершинами, что полезно при плотных графах или при частых запросах к рёбрам.
Как определить, содержит ли граф цикл?
Для неориентированного графа цикл можно обнаружить при обходе в глубину, проверяя, не ведёт ли очередное ребро к уже посещённой вершине, которая не является родительской. В ориентированном графе применяют DFS с отслеживанием вершин в текущем стеке рекурсии: если вершина встречается повторно в стеке, найден цикл. Дополнительно алгоритмы Косарайю и Тарьяна позволяют выявлять сильно связные компоненты и циклы внутри них, что полезно для анализа сложных сетей.
Когда стоит использовать алгоритм Дейкстры, а когда Беллмана–Форда?
Алгоритм Дейкстры подходит для графов без отрицательных рёбер и обеспечивает быстрый расчёт кратчайшего пути между вершинами. Беллмана–Форда применяется, если в графе могут быть отрицательные рёбра, и позволяет выявлять отрицательные циклы. Выбор алгоритма определяется наличием отрицательных весов и необходимостью обнаружить аномалии в графе.
Как графы помогают моделировать социальные сети?
В социальных сетях вершины графа соответствуют пользователям, а рёбра отражают связи между ними: подписки, сообщения, лайки. С помощью графов можно анализировать степень влияния пользователей, выявлять сообщества и кластеры, строить рекомендации на основе кратчайших путей или количества общих соседей. Такой подход позволяет выявлять ключевых участников сети и оценивать взаимосвязи внутри групп.
Какие преимущества дают библиотеки Python NetworkX и Graph-tool при работе с графами?
NetworkX удобен для небольших и средних графов, поддерживает ориентированные и неориентированные структуры, весовые рёбра и атрибуты вершин. Он позволяет реализовывать базовые алгоритмы обхода, поиска кратчайших путей, анализа связности и визуализации графа. Graph-tool ориентирован на большие графы и использует C++ на бэкенде для ускорения вычислений, поддерживает параллельную обработку, обнаружение циклов, центральности и кластеризацию. Он подходит для анализа сетей с тысячами вершин и миллионов рёбер.
В чем преимущество использования графов для анализа маршрутов в транспортной системе?
Граф позволяет представить дороги, остановки и станции в виде вершин и рёбер с указанием расстояния или времени. Это упрощает поиск оптимальных маршрутов с помощью алгоритмов Дейкстры или Беллмана–Форда. Кроме того, граф даёт возможность выявлять узкие места и альтернативные пути, моделировать изменение загруженности и быстро реагировать на закрытие дорог или задержки транспорта, что невозможно сделать при простой таблице маршрутов.
Как определить сильную и слабую связность в ориентированном графе?
Сильная связность означает, что из любой вершины можно добраться до любой другой по направленным рёбрам. Для её проверки используют алгоритмы Косарайю или Тарьяна, которые выделяют сильно связные компоненты. Слабая связность определяется при игнорировании направления рёбер: если после этого граф остаётся связным, он считается слабо связным. Этот анализ помогает понять структуру сети и выявить области, из которых невозможно попасть в другие вершины по направленным путям.