Содержание статьи

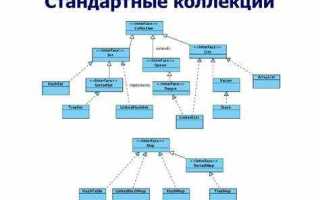
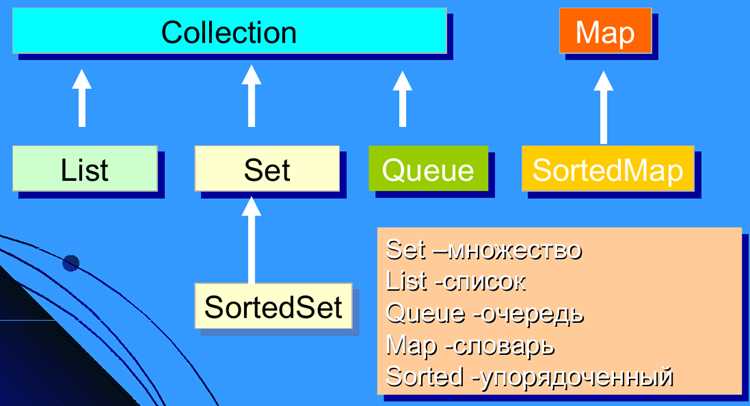
Коллекции представляют собой структуры данных, предназначенные для хранения и организации множества элементов одного или разных типов. На практике программисты чаще всего используют массивы, списки, множества и словари, выбирая их исходя из требований к скорости доступа, уникальности элементов и удобству обработки.
Массивы подходят для работы с фиксированным числом элементов, когда требуется быстрый доступ по индексу. Списки удобны при частом добавлении или удалении данных, так как позволяют изменять размер без перераспределения памяти. Множества обеспечивают автоматическое исключение дубликатов, что полезно для хранения уникальных идентификаторов, тегов или элементов конфигурации.
Словари и отображения реализуют ассоциативное хранение данных, позволяя быстро находить значение по ключу. Очереди и стеки применяются для управления порядком выполнения операций, например, при обработке задач в многопоточном окружении или при реализации алгоритмов поиска и обхода графов.
Правильный выбор коллекции напрямую влияет на производительность и надежность приложения. Анализ частоты операций чтения, записи и удаления элементов позволяет подобрать структуру данных, которая минимизирует затраты времени и ресурсов, снижает вероятность ошибок и упрощает поддержку кода.
Коллекции в программировании: их виды и применение
Коллекции в программировании классифицируются по способу хранения данных и доступу к элементам. Основные типы включают массивы, списки, множества, словари и специализированные структуры вроде очередей и стеков. Каждый тип имеет конкретные сценарии использования.
Массивы обеспечивают быстрый доступ по индексу и подходят для работы с фиксированным числом элементов. Списки позволяют динамически добавлять и удалять элементы без перераспределения памяти, что актуально при формировании коллекций во время выполнения программы.
Множества автоматически исключают дубликаты, поэтому их используют для хранения уникальных идентификаторов, тегов и ключей. Словари и отображения связывают ключи с данными, ускоряя поиск и модификацию элементов, что полезно при реализации кэширования и конфигурационных таблиц.
Очереди применяются для последовательной обработки задач, а стеки – для реализации обратного порядка действий, например, в алгоритмах обхода графов или обработки вызовов функций. Выбор структуры напрямую влияет на производительность: для больших коллекций с частыми вставками списки предпочтительнее массивов, а для поиска по ключу – словари.
При работе с многопоточными приложениями коллекции должны поддерживать синхронизацию, чтобы избежать состояния гонки. Многие языки предлагают специализированные потоко-безопасные реализации очередей, словарей и списков, что снижает риск ошибок при параллельной обработке данных.
Различия между массивами и списками в языках программирования
Списки, в том числе связные, обеспечивают динамическое изменение размера. Добавление или удаление элементов выполняется за O(1) при работе с указателями, однако доступ по индексу требует последовательного обхода, что увеличивает время операций чтения до O(n). Списки удобны для хранения коллекций, где количество элементов заранее неизвестно или часто меняется.
Выбор между массивом и списком зависит от типа операций. Для алгоритмов, где критична скорость доступа к элементам, предпочтительны массивы. Если требуется частое добавление и удаление данных в середине коллекции, списки обеспечивают более предсказуемое поведение без дорогостоящего копирования.
В языках программирования, таких как Java и C#, массивы реализуются как встроенные структуры, а списки представлены классами List или LinkedList с дополнительными методами управления размером. В Python массивы заменяются списками, которые сочетают динамический размер с индексированным доступом, но под капотом используют перераспределение памяти.
Когда использовать множества для хранения уникальных элементов

Множества представляют коллекции, где каждый элемент встречается только один раз. Они реализованы через хеш-таблицы или деревья поиска, что обеспечивает быстрый поиск, вставку и удаление элементов.
Множества применяют в следующих случаях:
- Необходимость хранения уникальных идентификаторов, например, номеров пользователей или кодов транзакций.
- Фильтрация дубликатов из больших потоков данных без дополнительных проверок.
- Операции объединения, пересечения и разности коллекций для анализа множеств данных.
- Оптимизация проверки наличия элемента, когда частота запросов высока.
При выборе множества важно учитывать:
- Размер коллекции: для небольших наборов затраты на структуру могут быть выше, чем у списка.
- Тип данных: сложные объекты требуют корректной реализации методов сравнения и хеширования.
- Язык программирования: реализация множества влияет на скорость операций; в Python используется set, в Java – HashSet или TreeSet.
Использование множеств сокращает количество лишних проверок, упрощает код и ускоряет обработку данных при работе с уникальными элементами.
Словари и отображения: хранение данных с ключами
Словари и отображения позволяют хранить пары ключ-значение, обеспечивая быстрый доступ к данным по уникальному ключу. Они широко применяются для кэширования, настройки конфигураций и связывания связанных объектов.
Основные особенности и рекомендации при использовании:
- Ключи должны быть уникальными и неизменяемыми, чтобы структура корректно поддерживала поиск и вставку.
- Словари реализованы через хеш-таблицы или сбалансированные деревья, что определяет скорость операций: вставка, удаление и поиск обычно выполняются за O(1) для хеш-таблиц и O(log n) для деревьев.
- Для больших коллекций важно выбирать реализацию, оптимизированную под частые изменения или чтение.
- Отображения поддерживают объединение данных, фильтрацию по ключам и массовое обновление значений.
Примеры применения:
- Хранение профилей пользователей, где ключ – идентификатор, а значение – объект с данными.
- Подсчет частоты появления слов в тексте, где ключ – слово, а значение – счетчик.
- Реализация маршрутизации запросов в приложениях, когда ключи соответствуют URL или командам.
- Кэширование вычисленных значений для ускорения повторного доступа без повторных расчетов.
Выбор подходящего типа словаря зависит от требований к производительности и частоты операций чтения и записи. В Python используется dict, в Java – HashMap и TreeMap, в C# – Dictionary и SortedDictionary.
Очереди и стеки: управление порядком обработки данных
Очереди и стеки используются для управления последовательностью выполнения операций и хранения временных данных. Стек реализует принцип LIFO (Last In, First Out), что позволяет обрабатывать последний добавленный элемент первым. Очередь использует принцип FIFO (First In, First Out), гарантируя обработку элементов в порядке поступления.
Применение стеков:
- Реализация вызовов функций и сохранение состояния при рекурсии.
- Обратная польская запись и вычисление выражений.
- Отмена действий в приложениях, где необходимо возвращение к предыдущему состоянию.
Применение очередей:
- Организация обработки задач в многопоточных системах.
- Потоковая обработка данных, например, сообщений или событий.
- Реализация алгоритмов поиска в ширину в графах.
Выбор между стеком и очередью зависит от требуемого порядка обработки. Для очередей с высокой частотой вставки и удаления используют двусвязные списки или кольцевые буферы. Стек чаще реализуется массивом или списком, что позволяет минимизировать накладные расходы на память и ускорить доступ к верхнему элементу.
Работа с коллекциями в функциональном стиле
Функциональный стиль работы с коллекциями подразумевает использование неизменяемых структур данных и операций, которые не изменяют исходный набор элементов. Основные методы включают map, filter, reduce и flatMap, позволяющие преобразовывать, отбирать и агрегировать данные без побочных эффектов.
Метод map применяется для преобразования каждого элемента коллекции по заданной функции, сохраняя порядок элементов. Filter позволяет выбрать элементы, соответствующие определенному условию, что упрощает работу с большими объемами данных без явных циклов.
Reduce агрегирует элементы коллекции в одно значение, например, суммируя числа или объединяя строки. FlatMap полезен для работы с вложенными коллекциями, превращая их в единый поток элементов.
Функциональный подход снижает вероятность ошибок, связанных с изменением данных, и упрощает параллельную обработку коллекций. Языки, такие как Scala, Kotlin, Java и Python, предоставляют встроенные функции для функциональной работы с массивами, списками и словарями, обеспечивая лаконичный и предсказуемый код.
Коллекции в многопоточных приложениях: проблемы и решения
При использовании коллекций в многопоточных приложениях возникает риск состояния гонки и непредсказуемого поведения при одновременном доступе. Обычные массивы, списки и словари не обеспечивают встроенной синхронизации, что может приводить к повреждению данных или исключениям.
Для предотвращения проблем применяют следующие подходы:
- Использование потокобезопасных коллекций, например, ConcurrentHashMap в Java или ConcurrentQueue в C#.
- Оборачивание стандартных коллекций синхронизированными оболочками, например, Collections.synchronizedList в Java.
- Применение механизмов блокировок и мьютексов для контроля доступа к разделяемым структурам.
- Использование неизменяемых коллекций, когда изменение данных происходит через создание новых экземпляров, а старые остаются доступными для чтения другими потоками.
Выбор метода зависит от характера операций: для частого чтения и редких изменений предпочтительны неизменяемые структуры, для интенсивного параллельного обновления – специализированные потокобезопасные коллекции. Оптимизация доступа снижает накладные расходы на синхронизацию и предотвращает сбои при одновременной работе нескольких потоков.
Выбор подходящей коллекции для конкретной задачи

Выбор коллекции зависит от частоты операций чтения, вставки, удаления и поиска, а также от требований к уникальности элементов и порядку хранения. Разные структуры данных обеспечивают разные показатели производительности и поведение при изменении размера.
Ниже приведена таблица с рекомендациями по выбору коллекций для типовых задач:
| Задача | Подходящая коллекция | Особенности |
|---|---|---|
| Быстрый доступ по индексу | Массив | Постоянное время O(1) для чтения; размер фиксирован |
| Частое добавление и удаление элементов | Список (LinkedList) | O(1) для вставки/удаления; последовательный доступ к элементам |
| Хранение уникальных значений | Множество (Set) | Автоматическое исключение дубликатов; быстрый поиск |
| Сопоставление ключ-значение | Словарь / Отображение (Map) | Быстрый поиск по ключу; поддержка обновления значений |
| Управление порядком обработки задач | Очередь / Стек | FIFO для очереди, LIFO для стека; поддержка последовательного доступа |
| Параллельная обработка данных | Потокобезопасные коллекции | Защита от состояния гонки; поддержка многопоточного доступа |
Анализ характера операций и требований к уникальности и порядку элементов позволяет подобрать коллекцию, которая минимизирует накладные расходы, ускоряет обработку данных и упрощает поддержку кода.
Вопрос-ответ:
В чем разница между массивами и списками в программировании?
Массивы имеют фиксированный размер и обеспечивают доступ к элементам по индексу за постоянное время O(1), что удобно при чтении данных. Списки позволяют динамически добавлять или удалять элементы, но доступ по индексу требует последовательного обхода, увеличивая время операций до O(n). Выбор между ними зависит от того, нужны ли частые вставки и удаления или быстрый доступ к конкретным элементам.
Когда стоит использовать множества для хранения данных?
Множества применяют, когда нужно исключить дублирование элементов и обеспечить быстрый поиск. Они подходят для хранения уникальных идентификаторов, тегов или ключей конфигурации, а также для операций объединения, пересечения и разности коллекций. Важно учитывать размер коллекции и тип элементов: сложные объекты требуют корректного определения методов сравнения и хеширования.
Как словари помогают организовать хранение данных?
Словари позволяют связывать уникальные ключи с значениями, ускоряя поиск, вставку и обновление информации. Они применяются для кэширования, хранения настроек, подсчета частоты элементов и маршрутизации запросов. Ключи должны быть неизменяемыми, а выбор реализации — соответствовать требованиям к скорости операций и объему данных.
В чем особенности работы со стеком и очередью?
Стек работает по принципу LIFO — последний добавленный элемент обрабатывается первым. Он используется для управления вызовами функций, обратной польской записи и реализации операций «отмена». Очередь применяет принцип FIFO — первый поступивший элемент обрабатывается первым, что важно для потоковой обработки задач и алгоритмов поиска в ширину. Реализация зависит от частоты вставки и удаления элементов.
Какие подходы применяют для работы с коллекциями в многопоточных приложениях?
Для безопасного доступа к коллекциям в многопоточных системах используют потокобезопасные реализации, например, ConcurrentHashMap или ConcurrentQueue. Также применяют синхронизированные оболочки или мьютексы для блокировки доступа. Использование неизменяемых коллекций снижает риск состояния гонки, поскольку каждый поток работает с собственной версией данных, что упрощает параллельную обработку.
Как выбрать подходящую коллекцию для задачи с большим количеством данных и частыми изменениями?
Выбор коллекции зависит от характера операций с данными. Если требуется быстрый доступ по индексу и редко выполняются вставки или удаления, лучше использовать массив. При частых добавлениях и удалениях элементов в середине коллекции оптимальны списки с динамическим размером. Для хранения уникальных элементов используют множества, а для сопоставления ключ-значение — словари. В многопоточных приложениях применяют потокобезопасные версии коллекций или неизменяемые структуры, чтобы избежать состояния гонки и ошибок при одновременном доступе. Анализ конкретных операций и объема данных помогает подобрать структуру, которая ускоряет обработку и упрощает поддержку кода.