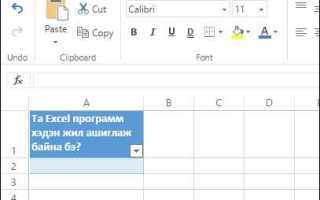
Работа с текстовыми данными в Excel часто требует точного управления содержимым ячеек. На практике это может быть удаление лишних символов, выделение нужной части строки, очистка данных, выгруженных из CRM, бухгалтерских систем или веб-форм. Без встроенных формул такие задачи быстро превращаются в ручную правку, что повышает риск ошибок и замедляет обработку таблиц.
Excel предоставляет набор текстовых функций, которые позволяют обрезать текст по длине, позиции или заданному символу. Эти формулы работают с любыми строками: ФИО, артикулами, номерами договоров, адресами электронной почты и служебными комментариями. Понимание логики функций дает возможность комбинировать их между собой и получать предсказуемый результат даже при нестандартной структуре данных.
В статье рассматриваются прикладные сценарии обрезки текста: удаление символов слева и справа, извлечение фрагмента из середины строки, очистка пробелов и скрытых знаков, а также работа с разделителями. Каждый пример ориентирован на реальные задачи, с которыми сталкиваются пользователи Excel при подготовке отчетов, импорте данных и автоматизации расчетов.
Обрезка текста в ячейке Excel: формулы и примеры

Обрезка текста в Excel решается с помощью стандартных текстовых функций, которые работают напрямую со строками и не изменяют исходные данные. Формулы применяются к содержимому ячейки и возвращают новый результат, что удобно для отчетов, выгрузок и подготовки данных к анализу.
Наиболее востребованные сценарии связаны с удалением фиксированного количества символов или выделением нужного фрагмента строки. Для этого используются следующие функции:
- ЛЕВСИМВ – возвращает заданное число символов с начала строки, подходит для обрезки хвоста текста.
- ПРАВСИМВ – извлекает символы с конца строки, применяется при удалении префиксов.
- ПСТР – позволяет получить часть текста из середины по номеру начального символа и длине.
При работе с данными из внешних источников часто встречаются лишние пробелы и скрытые знаки. Для их устранения используются отдельные формулы, которые можно комбинировать с функциями обрезки:
- СЖПРОБЕЛЫ – удаляет начальные, конечные и повторяющиеся пробелы внутри строки.
- ПЕЧСИМВ – очищает текст от непечатаемых символов, возникающих при копировании.
Если требуется обрезать текст до определенного символа, например до пробела, тире или знака «@», применяются функции поиска позиции:
- Определяется номер символа с помощью НАЙТИ или ПОИСК.
- Результат передается в ЛЕВСИМВ или ПСТР для извлечения нужной части строки.
Комбинирование этих формул позволяет обрабатывать строки любой структуры: разделять ФИО, сокращать наименования, удалять служебные коды и приводить текст к единому виду без ручного редактирования.
Обрезка символов слева с помощью функции ЛЕВСИМВ
Функция ЛЕВСИМВ применяется для получения заданного количества символов с начала текстовой строки. Она подходит для ситуаций, когда в ячейке содержатся коды, даты, номера документов или сокращенные обозначения, размещенные строго слева.
Синтаксис функции включает два аргумента: ссылку на ячейку с текстом и количество символов, которые необходимо оставить. Если указано число, превышающее длину строки, Excel возвращает весь текст без ошибок, что удобно при работе с данными переменной длины.
При очистке выгруженных данных ЛЕВСИМВ часто используют для удаления служебных приписок в конце строки. Например, если наименование товара всегда начинается с артикула фиксированной длины, функция позволяет выделить его без дополнительных проверок.
Для более точной обрезки ЛЕВСИМВ комбинируют с другими функциями. Совместно с ДЛСТР можно автоматически определить длину текста и обрезать строку до нужного количества знаков, а с НАЙТИ – извлечь текст до первого пробела, скобки или разделителя.
При работе с текстом, содержащим лишние пробелы в начале строки, рекомендуется предварительно применять СЖПРОБЕЛЫ. Это предотвращает смещение результата и позволяет получить ожидаемое количество символов без искажений.
Удаление символов справа через функцию ПРАВСИМВ
Функция ПРАВСИМВ используется для извлечения заданного количества символов с конца текстовой строки. Она применяется в случаях, когда значимая часть данных находится справа, а левую часть необходимо отбросить без изменения исходной ячейки.
Аргументы функции включают ссылку на ячейку и количество символов для возврата. Это позволяет точно контролировать результат при работе с номерами телефонов, кодами операций, расширениями файлов и идентификаторами, где важны последние знаки.
Для удаления фиксированного количества символов в начале строки ПРАВСИМВ часто сочетают с функцией ДЛСТР. Длина текста уменьшается на заданное число, после чего функция возвращает оставшуюся правую часть строки.
При обработке данных из внешних источников полезно учитывать наличие пробелов и служебных символов в конце строки. Перед применением ПРАВСИМВ рекомендуется очистить текст с помощью СЖПРОБЕЛЫ или ПЕЧСИМВ, чтобы избежать смещения символов.
Функция корректно работает с текстом переменной длины и не вызывает ошибок, если запрошенное количество символов превышает фактическую длину строки, что упрощает массовую обработку таблиц.
Извлечение фрагмента текста по позиции функцией ПСТР

Функция ПСТР предназначена для получения части строки из середины текста на основе точной позиции начала и количества символов. Она применяется, когда нужный фрагмент не находится строго слева или справа, а расположен внутри значения.
Формула использует три аргумента: исходный текст, номер первого символа и длину извлекаемого фрагмента. Отсчет позиций начинается с единицы, что важно учитывать при работе с кодами, датами и составными идентификаторами.
ПСТР часто используют для разделения сложных строк, содержащих несколько логических блоков. Например, из строки с форматом «Код_Регион_Год» можно извлечь отдельные элементы, зная их фиксированное расположение.
Для обработки данных с переменной структурой функцию комбинируют с НАЙТИ или ПОИСК. Позиция разделителя определяется автоматически, после чего ПСТР извлекает текст между двумя символами без ручной корректировки.
Перед применением функции рекомендуется очистить строку от лишних пробелов и непечатаемых знаков. Это предотвращает смещение позиций и обеспечивает стабильный результат при массовой обработке ячеек.
Обрезка текста по заданной длине с использованием ДЛСТР и ЛЕВСИМВ

Комбинация функций ДЛСТР и ЛЕВСИМВ применяется, когда необходимо обрезать текст до определенного количества символов с учетом фактической длины строки. Такой подход удобен при работе с данными, где допустим максимальный размер значения.
ДЛСТР возвращает точное количество символов в ячейке, включая пробелы и знаки препинания. Это позволяет контролировать обрезку без жесткой привязки к исходной длине текста и избежать потери данных при коротких строках.
На практике формулы используют для сокращения описаний товаров, комментариев или наименований, которые превышают установленный лимит. ЛЕВСИМВ получает нужное число символов слева, а значение из ДЛСТР помогает корректно рассчитать длину обрезки.
При массовой обработке рекомендуется заранее определить допустимую длину и применять формулу ко всему диапазону. Это обеспечивает единый формат данных без ручного редактирования каждой ячейки.
Если в тексте встречаются лишние пробелы, их стоит удалить до расчета длины. Использование СЖПРОБЕЛЫ перед ДЛСТР предотвращает искажение результата и сохраняет заданное количество значимых символов.
Удаление лишних пробелов функцией СЖПРОБЕЛЫ

Функция СЖПРОБЕЛЫ удаляет все лишние пробелы в тексте, оставляя только один пробел между словами. Она применяется для очистки данных после импорта из внешних систем, веб-форм и CSV-файлов, где часто встречаются случайные пробелы в начале, конце или внутри строк.
Формула принимает один аргумент – ссылку на ячейку с текстом. После обработки строка возвращается без лишних пробелов, что упрощает последующую работу с другими функциями обрезки, поиска и сравнения значений.
СЖПРОБЕЛЫ полезна при подготовке текстов для обрезки через ЛЕВСИМВ, ПРАВСИМВ или ПСТР, чтобы избежать смещения символов и некорректного результата. Например, при извлечении первых 10 символов строки с лишними пробелами конечный результат может включать пустые позиции без предварительной очистки.
Функцию можно комбинировать с другими формулами для автоматической стандартизации данных. После СЖПРОБЕЛЫ строки становятся однородными, что облегчает фильтрацию, сортировку и создание отчетов без ручной корректировки текста.
Очистка непечатаемых знаков в тексте функцией ПЕЧСИМВ
Формула принимает один аргумент – ссылку на ячейку с текстом. После применения ПЕЧСИМВ строка возвращается в «чистом» виде, без невидимых символов вроде перевода строки, табуляции или специальных кодов ASCII с номерами от 0 до 31.
Применение функции особенно важно перед:
- Использованием ЛЕВСИМВ, ПРАВСИМВ и ПСТР для обрезки текста, чтобы позиция символов не смещалась;
- Сравнением строк для поиска дубликатов или проверки соответствия;
- Экспортом данных в другие системы, где непечатаемые знаки могут нарушить формат.
Для комплексной очистки данных рекомендуется сочетать ПЕЧСИМВ с СЖПРОБЕЛЫ. Сначала удаляются все непечатаемые символы, затем лишние пробелы, что обеспечивает стабильный результат при массовой обработке таблиц и автоматизации отчетов.
Обрезка текста до или после символа с помощью НАЙТИ и ПОИСК
Функции НАЙТИ и ПОИСК позволяют определить позицию определенного символа или подстроки в тексте. Их используют для обрезки текста до или после конкретного разделителя, например, пробела, тире, точки или знака «@».
Разница между функциями в том, что НАЙТИ учитывает регистр символов, а ПОИСК – нет. Выбор зависит от необходимости точного соответствия регистра в строках.
Принцип работы обрезки:
| Задача | Формула | Описание |
|---|---|---|
| Извлечь текст до первого пробела | =ЛЕВСИМВ(A1;НАЙТИ(» «;A1)-1) | НАХОДИТ позицию первого пробела и возвращает текст слева от него. |
| Извлечь текст после символа «@» | =ПСТР(A1;НАЙТИ(«@»;A1)+1;ДЛСТР(A1)) | НАХОДИТ «@» и возвращает все символы справа от него. |
| Удалить текст после тире | =ЛЕВСИМВ(A1;ПОИСК(«-«;A1)-1) | ПОИСК определяет позицию тире без учета регистра, ЛЕВСИМВ возвращает левую часть. |
Использование этих функций вместе с ЛЕВСИМВ, ПРАВСИМВ и ПСТР позволяет создавать универсальные формулы для динамической обрезки текста, независимо от длины строки или позиции разделителя.
Вопрос-ответ:
Как обрезать текст в Excel, чтобы оставлять только первые 10 символов ячейки?
Для этого используется функция ЛЕВСИМВ. В формуле укажите ссылку на ячейку и количество символов: =ЛЕВСИМВ(A1;10). Она вернет первые 10 знаков текста из указанной ячейки, игнорируя пробелы и специальные символы, если они есть.
Можно ли удалить пробелы внутри текста и при этом оставить только один между словами?
Да, для этого применяется функция СЖПРОБЕЛЫ. Она убирает лишние пробелы в начале, конце и внутри строки, оставляя только один пробел между словами. Например, =СЖПРОБЕЛЫ(A1) очистит текст от случайных пробелов, которые могут мешать дальнейшей обработке или сравнению строк.
Как извлечь часть текста, если нужно взять символы с 5 по 12 из строки?
Для извлечения фрагмента текста используется функция ПСТР. Формула выглядит так: =ПСТР(A1;5;8). Здесь 5 — номер первого символа для извлечения, а 8 — количество символов. Excel вернет текст с 5-го по 12-й символ включительно. Такой способ удобен для работы с номерами документов, артикулами и кодами.
Как обрезать текст в ячейке до символа «@» в адресе электронной почты?
Для этого комбинируют функции НАЙТИ и ЛЕВСИМВ. Сначала НАЙТИ определяет позицию символа «@»: =НАЙТИ(«@»;A1). Затем ЛЕВСИМВ извлекает текст слева от него: =ЛЕВСИМВ(A1;НАЙТИ(«@»;A1)-1). Результат — часть строки до знака «@», например, имя пользователя в адресе email.
Как удалить непечатаемые символы из текста, чтобы формулы обрабатывали строку корректно?
Для очистки строки от скрытых символов используется функция ПЕЧСИМВ. Она удаляет знаки с кодами ASCII от 0 до 31, которые могут появляться при копировании текста из веб-страниц или PDF. Формула: =ПЕЧСИМВ(A1). После применения текста можно безопасно обрезать, искать или сравнивать без ошибок.