Содержание статьи

При построении трендов, регрессионных моделей и прогнозов в Excel важно понимать, насколько полученная функция отклоняется от исходных данных. Для этой задачи используется средняя ошибка аппроксимации – показатель, позволяющий количественно оценить расхождение между фактическими и расчетными значениями. Она особенно востребована при анализе временных рядов, экономических показателей, продаж и производственных данных.
Средняя ошибка аппроксимации рассчитывается на основе относительных отклонений, выраженных в процентах, что делает ее наглядной при сравнении разных моделей. В Excel отсутствует готовая функция для ее автоматического определения, поэтому расчет выполняется через комбинацию стандартных формул. Это требует точного понимания структуры данных, логики вычислений и корректного оформления формул в ячейках.
В практической работе важно не только получить числовое значение, но и правильно его интерпретировать. Например, значение менее 10% обычно указывает на приемлемое соответствие модели данным, тогда как превышение 20–30% сигнализирует о слабой аппроксимации. В статье подробно разбирается, какую формулу использовать в Excel, как пошагово выполнить расчет и на что обратить внимание при анализе результата, чтобы избежать искажений и ошибок.
Средняя ошибка аппроксимации в Excel: формула и расчет
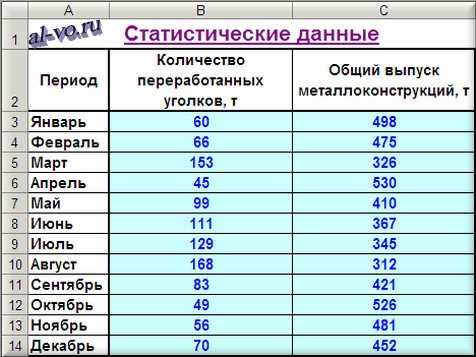
Средняя ошибка аппроксимации показывает, на сколько процентов в среднем расчетные значения модели отклоняются от фактических данных. Показатель основан на относительных ошибках и рассчитывается по формуле: A = (1 / n) × Σ |(yi − ŷi) / yi| × 100%, где yi – фактическое значение, ŷi – значение, полученное по аппроксимирующей функции, n – количество наблюдений.
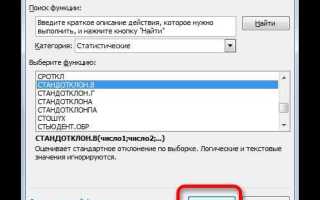
В Excel расчет выполняется поэтапно. В отдельном столбце вычисляется модуль относительного отклонения для каждой строки данных. Для этого используется формула вида =ABS((B2-C2)/B2), где ячейка B2 содержит фактическое значение, а C2 – расчетное. Формула копируется на весь диапазон наблюдений без округления промежуточных результатов.
После этого определяется среднее значение относительных ошибок с помощью функции СРЗНАЧ. Итоговая формула принимает вид =СРЗНАЧ(D2:Dn)*100, где диапазон D2:Dn содержит рассчитанные относительные отклонения. Умножение на 100 переводит показатель в проценты, что упрощает анализ и сравнение моделей.
При наличии нулевых или близких к нулю фактических значений строки с такими данными исключаются из расчета, так как деление приводит к искажению результата. Для автоматизации можно применять условные формулы с ЕСЛИ, чтобы пропускать некорректные наблюдения и сохранять точность итогового показателя.
Что означает средняя ошибка аппроксимации и когда она применяется
Средняя ошибка аппроксимации отражает усреднённое относительное отклонение значений модели от фактических данных, выраженное в процентах. В отличие от абсолютных показателей, она учитывает масштаб исходных величин, поэтому одинаково применима к рядам с разными единицами измерения и диапазонами значений. Это позволяет оценивать качество аппроксимирующей функции без привязки к размерности данных.
Показатель применяется при анализе регрессионных моделей, трендовых линий и прогнозов, построенных в Excel. Он используется для сравнения нескольких вариантов аппроксимации одного и того же набора данных, например линейной, степенной или экспоненциальной зависимости. Модель с меньшим значением средней ошибки аппроксимации обычно лучше описывает наблюдаемые значения.
На практике ориентируются на количественные границы интерпретации. Значение до 10% указывает на близкое соответствие расчетов исходным данным, диапазон 10–20% допускается при наличии шумов и нерегулярных колебаний, превышение 20% свидетельствует о слабой пригодности модели для анализа и прогноза. Эти пороги применяются при работе с экономическими, статистическими и производственными рядами.
Средняя ошибка аппроксимации не используется для оценки моделей, содержащих нулевые или отрицательные фактические значения без предварительной фильтрации, так как относительное отклонение теряет смысл. В таких случаях применяются альтернативные показатели или выполняется очистка данных перед расчетом.
Подготовка исходных данных для расчета ошибки аппроксимации в Excel
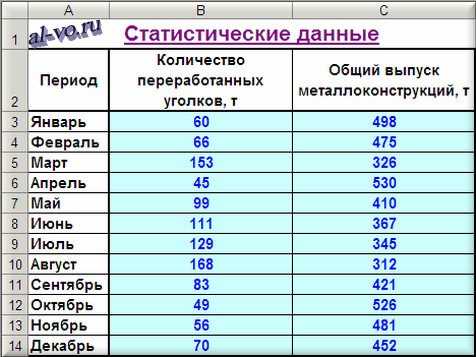
Корректность расчета средней ошибки аппроксимации напрямую зависит от структуры исходных данных. В Excel необходимо заранее разделить фактические и расчетные значения по отдельным столбцам, сохраняя одинаковое количество наблюдений и единый порядок строк. Каждая строка должна соответствовать одному объекту или периоду измерения.
- в одном столбце размещаются фактические значения показателя без округления;
- в соседнем столбце фиксируются значения, полученные по аппроксимирующей функции;
- заголовки столбцов не включаются в диапазоны вычислений;
- формат ячеек устанавливается числовой с одинаковым количеством знаков после запятой.
Перед расчетом выполняется проверка данных на логические и технические ошибки. Наличие пустых ячеек, текстовых значений или формул с ошибками искажает итоговый результат и должно быть устранено до начала вычислений.
- удалить строки с нулевыми фактическими значениями, чтобы избежать деления на ноль;
- проверить соответствие каждой расчетной величины своему фактическому значению;
- убедиться, что формулы аппроксимации не содержат ручных корректировок;
- отсортировать данные по исходному порядку измерений, если он имеет значение.
После подготовки рекомендуется сохранить копию диапазона данных. Это позволяет повторно пересчитать среднюю ошибку аппроксимации при изменении модели без риска потери исходных значений и упрощает сравнение нескольких вариантов аппроксимации.
Формула средней ошибки аппроксимации и ее запись в ячейках Excel
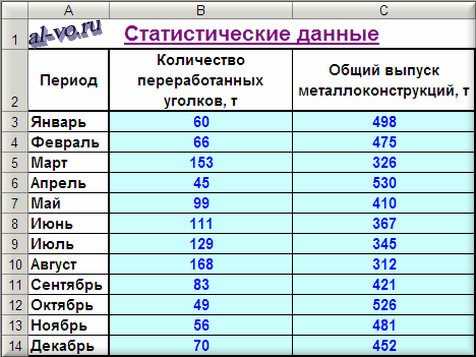
Средняя ошибка аппроксимации рассчитывается как среднее значение модулей относительных отклонений расчетных данных от фактических. Математически показатель задается выражением A = (1 / n) × Σ |(y − ŷ) / y| × 100%, где y – наблюдаемое значение, ŷ – результат аппроксимации, n – число наблюдений. Формула ориентирована на процентное представление ошибки, что упрощает интерпретацию результата.
В Excel расчет реализуется через стандартные функции без использования надстроек. Для каждой строки данных сначала вычисляется относительное отклонение. Если фактические значения расположены в столбце B, а расчетные – в столбце C, в ячейке D2 вводится формула =ABS((B2-C2)/B2). Использование ABS исключает влияние знака отклонения.
После копирования формулы на весь диапазон определяется среднее значение относительных ошибок. Для этого применяется функция СРЗНАЧ, например =СРЗНАЧ(D2:Dn)*100. Умножение на 100 выполняется на завершающем этапе, чтобы сохранить точность промежуточных расчетов и получить итоговый показатель в процентах.
При необходимости исключения некорректных строк формула дополняется логической проверкой. Запись =ЕСЛИ(B2=0;»»;ABS((B2-C2)/B2)) позволяет пропустить значения с нулевыми фактическими данными и сохранить корректность вычислений при расчете средней ошибки аппроксимации.
Пошаговый расчет средней ошибки аппроксимации на конкретном примере
Рассмотрим набор из пяти наблюдений, где фактические значения объема продаж размещены в столбце B: 120, 135, 150, 160, 170. Расчетные значения, полученные по линейной модели, находятся в столбце C: 125, 140, 145, 158, 172. Каждая строка соответствует одному периоду.
На первом шаге вычисляется относительное отклонение для каждого наблюдения. В ячейке D2 вводится формула =ABS((B2-C2)/B2), после чего она копируется до строки D6. В результате получаются значения: 0,0417; 0,0370; 0,0333; 0,0125; 0,0118.
Далее определяется среднее значение полученных отклонений. В любой свободной ячейке вводится формула =СРЗНАЧ(D2:D6), результат составляет 0,0273. На этом этапе показатель выражен в долях единицы и не округляется.
Заключительный шаг – перевод результата в проценты. Для этого используется умножение на 100: =СРЗНАЧ(D2:D6)*100. Итоговое значение средней ошибки аппроксимации равно 2,73%, что указывает на близкое соответствие модели фактическим данным при анализе данного набора наблюдений.
Интерпретация полученного значения средней ошибки аппроксимации
Полученное значение средней ошибки аппроксимации показывает, на сколько процентов в среднем расчетные данные отклоняются от фактических. Этот показатель используется для оценки пригодности модели к анализу и прогнозированию. Чем меньше значение, тем ближе аппроксимирующая функция к реальным наблюдениям.
Для практической интерпретации удобно опираться на ориентировочные диапазоны значений, применяемые в статистическом и экономическом анализе.
| Средняя ошибка аппроксимации | Интерпретация результата |
|---|---|
| до 5% | модель очень близко описывает исходные данные |
| 5–10% | допустимое отклонение для аналитических расчетов |
| 10–20% | ограниченная точность, требуется осторожность при прогнозе |
| более 20% | модель слабо отражает фактические данные |
При сравнении нескольких моделей предпочтение отдается варианту с наименьшей средней ошибкой аппроксимации, если данные рассчитывались на одном и том же наборе наблюдений. Сравнение значений, полученных на разных выборках, не допускается без дополнительной нормализации.
Важно учитывать характер данных. Для рядов с резкими колебаниями допустимый уровень ошибки выше, чем для стабильных показателей. Значение средней ошибки аппроксимации всегда анализируется совместно с графиком аппроксимации и экономическим смыслом модели, а не изолированно.
Типовые ошибки при расчете средней ошибки аппроксимации в Excel
Распространенной ошибкой считается преждевременное умножение каждого отклонения на 100. Перевод в проценты должен выполняться только после вычисления среднего значения, иначе итоговый показатель будет завышен. Корректная логика расчета предполагает сначала усреднение относительных ошибок, затем масштабирование результата.
Наличие нулевых фактических значений без фильтрации приводит к делению на ноль или к появлению ошибочных данных в диапазоне расчета. Такие строки необходимо исключать или обрабатывать через логические функции, иначе результат средней ошибки аппроксимации теряет интерпретационную ценность.
Ошибки также возникают при несовпадении диапазонов фактических и расчетных данных. Смещение строк, скрытые пропуски или ручная корректировка отдельных значений нарушают соответствие наблюдений и делают расчет некорректным. Перед вычислением требуется проверка структуры таблицы и целостности формул.
Использование округления на промежуточных этапах снижает точность результата. Округлять рекомендуется только итоговое значение средней ошибки аппроксимации, оставляя все вспомогательные расчеты с максимальным числом знаков после запятой.
Вопрос-ответ:
Чем средняя ошибка аппроксимации отличается от средней абсолютной ошибки в Excel?
Средняя ошибка аппроксимации рассчитывается как относительное отклонение и выражается в процентах, тогда как средняя абсолютная ошибка показывает разницу в исходных единицах измерения. Первая подходит для сравнения моделей на данных разного масштаба, вторая используется для оценки фактического разброса значений без учета их уровня.
Можно ли рассчитывать среднюю ошибку аппроксимации для временных рядов с нулевыми значениями?
Прямой расчет невозможен, так как формула содержит деление на фактическое значение. Строки с нулевыми значениями исключаются из диапазона или обрабатываются условной формулой ЕСЛИ, чтобы такие наблюдения не участвовали в вычислении среднего.
Почему при расчете в Excel нельзя округлять значения относительных ошибок?
Округление на промежуточных этапах искажает итоговое среднее значение. Даже небольшое сокращение числа знаков после запятой в каждом наблюдении приводит к накопленной погрешности, особенно при большом количестве строк данных.
Как понять, что модель аппроксимации в Excel дает приемлемый результат?
Ориентиром служит величина средней ошибки аппроксимации. Значения до 10% обычно указывают на близкое соответствие расчетных данных фактическим. При превышении 20% модель редко подходит для анализа и требует пересмотра типа функции или исходных данных.
Нужно ли пересчитывать среднюю ошибку аппроксимации при изменении одного значения?
Да, любое изменение фактического или расчетного значения влияет на относительное отклонение и, как следствие, на итоговое среднее. После корректировки данных формулы должны быть пересчитаны автоматически, если они корректно протянуты по диапазону.
Почему средняя ошибка аппроксимации в Excel может резко меняться при добавлении одной строки данных?
Показатель рассчитывается как среднее относительных отклонений, поэтому одна строка с большим расхождением между фактическим и расчетным значением заметно влияет на итог. Особенно это проявляется при небольшом числе наблюдений или при наличии выбросов. В таких случаях полезно отдельно проанализировать новые данные и проверить, соответствует ли модель изменившейся структуре ряда.
Нужно ли учитывать знак отклонения при расчете средней ошибки аппроксимации?
Знак отклонения не используется. В расчет включается модуль относительной разницы, чтобы положительные и отрицательные отклонения не взаимно компенсировали друг друга. Если не применять функцию ABS, среднее значение может стремиться к нулю при значительных расхождениях, что создаст ложное впечатление точного совпадения модели с данными.