Содержание статьи

Повторяющиеся данные в Google Таблицах появляются при импорте файлов, совместной работе, ручном вводе и синхронизации с внешними источниками. Дубли могут искажать расчёты, приводить к неверным итогам в сводных таблицах и усложнять анализ. Особенно часто проблема возникает в списках клиентов, заказов, email-адресов, SKU и других идентификаторов, где важна уникальность значений.
Google Таблицы не имеют отдельной кнопки «Найти дубликаты», поэтому поиск выполняется через встроенные инструменты: формулы, условное форматирование и функции обработки массивов. Каждый способ подходит для своей задачи – от быстрой визуальной проверки одного столбца до сложного сравнения строк по нескольким критериям без изменения исходных данных.
В статье рассматриваются практические методы выявления дублей: использование COUNTIF и COUNTIFS для подсчёта повторов, применение UNIQUE для сравнения исходного списка с очищенной версией, а также настройка автоматической подсветки повторяющихся значений. Все примеры ориентированы на реальные сценарии работы с таблицами и не требуют установки дополнений.
Материал подойдёт тем, кто работает с таблицами ежедневно и хочет быстро находить повторы в данных, не нарушая структуру файла и не удаляя записи вручную.
Поиск повторяющихся значений в одном столбце с помощью условного форматирования
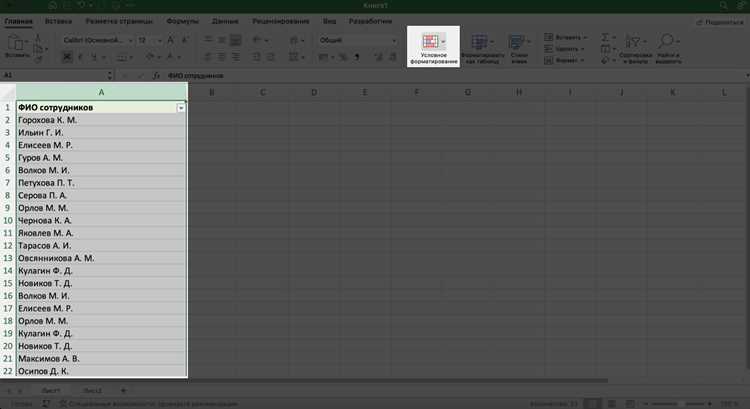
Условное форматирование позволяет визуально обнаружить дубли без изменения данных. Метод подходит для проверки столбцов с идентификаторами: email, номерами заказов, кодами товаров, ИНН или артикулами. Подсветка срабатывает автоматически при появлении новых повторов и не требует ручного пересчёта.
Для начала выделяют диапазон ячеек, например A2:A1000, исключая заголовок. В меню выбирают «Формат» → «Условное форматирование», затем в параметре «Форматировать, если» указывают «Пользовательская формула». В поле формулы вводят выражение =COUNTIF($A$2:$A$1000;A2)>1, где первый аргумент фиксирует проверяемый диапазон, а второй ссылается на текущую строку.
Формула подсчитывает количество совпадений каждого значения в столбце и применяет форматирование ко всем ячейкам, встречающимся более одного раза. Для пустых строк рекомендуется дополнить условие проверкой A2<>»», чтобы избежать подсветки незаполненных ячеек.
Цвет заливки или текста выбирают контрастный, чтобы дубли были заметны при прокрутке больших списков. При изменении диапазона или добавлении строк формулу корректируют один раз – правило продолжает работать без дополнительной настройки.
Способ не выявляет, какое значение является первичным, а какое повторным, но подходит для быстрой диагностики и предварительной очистки данных перед фильтрацией или удалением строк.
Выявление дублей по нескольким столбцам через формулу COUNTIFS
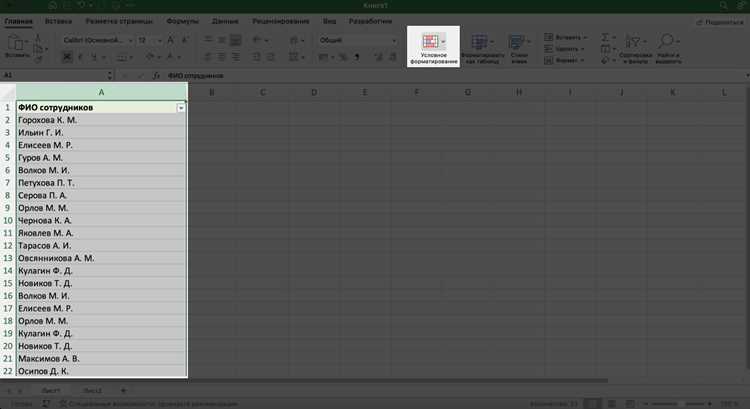
Когда уникальность строки определяется сочетанием нескольких полей, проверка одного столбца не даёт точного результата. Типичные примеры – заказы с одинаковым номером и датой, клиенты с совпадающими именем и телефоном, товары с одинаковым артикулом и поставщиком. В таких случаях используют функцию COUNTIFS, которая учитывает сразу несколько условий.
Предположим, данные находятся в столбцах A (Email), B (Дата регистрации) и C (Источник). Для поиска повторяющихся комбинаций в ячейке D2 вводят формулу =COUNTIFS($A$2:$A$1000;A2;$B$2:$B$1000;B2;$C$2:$C$1000;C2). Формула подсчитывает количество строк, где значения во всех трёх столбцах совпадают с текущей строкой.
Если результат больше 1, комбинация данных уже встречалась ранее. Для удобства анализа формулу протягивают вниз по столбцу и используют фильтр по значениям больше единицы, чтобы вывести только дублирующиеся строки.
Формулу можно встроить в условное форматирование, применив правило с проверкой >1, чтобы визуально выделить повторяющиеся записи без создания вспомогательного столбца. При работе с большими таблицами рекомендуется ограничивать диапазоны точным числом строк, чтобы избежать лишних вычислений.
Метод подходит для строгой проверки составных ключей и позволяет выявлять скрытые дубли, которые не заметны при сравнении отдельных столбцов.
Нахождение повторяющихся строк с использованием функции UNIQUE
Функция UNIQUE позволяет определить дублирующиеся строки путём сравнения исходного диапазона с набором уникальных значений. Метод подходит для таблиц, где важно учитывать всю строку целиком, а не отдельные столбцы: отчёты, выгрузки из CRM, логи операций, списки транзакций.
Если данные расположены в диапазоне A2:D1000, в свободной области листа вводят формулу =UNIQUE(A2:D1000). В результате формируется массив строк без повторений, полностью соответствующий исходным данным по структуре и порядку столбцов.
Для выявления дублей сравнивают количество строк в исходном диапазоне и в массиве UNIQUE. Более точный способ – добавить вспомогательный столбец с формулой =COUNTIF(ARRAYFORMULA(A2:A1000&B2:B1000&C2:C1000&D2:D1000);A2&B2&C2&D2), которая подсчитывает количество совпадений по всей строке.
Значения больше 1 указывают на повторяющиеся строки. Такой подход позволяет находить полные дубли, даже если отдельные поля по отдельности выглядят уникальными. Для повышения читаемости данные часто объединяют в одной формуле, сохраняя исходную таблицу без изменений.
Функция UNIQUE не удаляет записи автоматически, что делает её удобной для проверки данных перед фильтрацией, сортировкой или экспортом в другие системы.
Проверка диапазона на дубли с помощью функции COUNTIF
Функция COUNTIF применяется для подсчёта повторяющихся значений в пределах одного диапазона. Она подходит для анализа списков с простой структурой, где проверяется один столбец без учёта дополнительных условий. Чаще всего метод используют для контроля уникальности кодов, номеров заявок, телефонов и email-адресов.
Базовая формула для проверки значений в столбце A выглядит так: =COUNTIF($A$2:$A$1000;A2). Формулу вводят в соседний столбец и копируют вниз. Каждый результат показывает, сколько раз текущее значение встречается в заданном диапазоне.
- значение 1 означает, что запись уникальна;
- значение больше 1 указывает на наличие дублей;
- одинаковые числа в нескольких строках относятся к одному повторяющемуся значению.
Чтобы исключить пустые ячейки из расчёта, формулу дополняют условием: =IF(A2=»»;»»;COUNTIF($A$2:$A$1000;A2)). Это упрощает анализ больших таблиц и предотвращает появление лишних чисел.
Для работы с диапазонами переменной длины рекомендуется ограничивать проверку фактически заполненными строками, а не целым столбцом. Это снижает нагрузку на таблицу и делает результаты более наглядными.
Метод с COUNTIF удобен как промежуточный этап: после выявления дублей данные легко отфильтровать, выделить цветом или использовать в дальнейших формулах.
Поиск и пометка дублей без удаления исходных данных
В рабочих таблицах часто требуется сохранить все записи, пометив повторяющиеся значения для проверки или согласования. Для этого используют вспомогательные столбцы и формулы, которые не затрагивают исходные данные и позволяют управлять отображением дублей.
Один из практичных вариантов – добавить столбец со статусом. Например, при проверке значений в столбце A в ячейке B2 указывают формулу =IF(COUNTIF($A$2:$A$1000;A2)>1;»Дубль»;»Уникально») и копируют её вниз. В результате каждая строка получает текстовую метку без изменения основного диапазона.
| Значение | Статус |
|---|---|
| client1@mail.ru | Уникально |
| client2@mail.ru | Дубль |
| client2@mail.ru | Дубль |
Для более точной пометки по нескольким полям формулу COUNTIF заменяют на COUNTIFS, указывая все проверяемые столбцы. Такой подход позволяет фиксировать повторы только при полном совпадении ключевых данных.
Помеченные строки удобно фильтровать, сортировать или передавать на проверку другим участникам, сохраняя целостность таблицы и историю изменений.
Автоматическое обнаружение дублей при добавлении новых строк
Для таблиц, которые регулярно пополняются, важно, чтобы проверка на дубли выполнялась без ручного вмешательства. Это достигается за счёт формул с динамическими диапазонами и заранее настроенных правил условного форматирования, которые применяются ко всему столбцу или заранее выделенному диапазону строк.
В столбцах с постоянным вводом данных, например A2:A, используют формулу =COUNTIF($A$2:$A;A2) в вспомогательном столбце. При добавлении новой строки формула автоматически учитывает все предыдущие значения и сразу показывает наличие повторов, если результат больше единицы.
Для визуального контроля правило условного форматирования настраивают на диапазон A2:A с пользовательской формулой =COUNTIF($A$2:$A;A2)>1. Новые дубли подсвечиваются сразу после ввода данных, без обновления правил.
При проверке составных данных применяют COUNTIFS с полными диапазонами столбцов, например $A$2:$A и $B$2:$B, что позволяет выявлять повторы по нескольким полям одновременно даже в расширяющихся таблицах.
Такой подход подходит для совместной работы: каждый участник видит дубли сразу после добавления строки, а исходные данные остаются неизменными и доступными для дальнейшего анализа.
Вопрос-ответ:
Почему Google Таблицы показывают дубли, хотя значения визуально отличаются?
Чаще всего причина связана с пробелами, невидимыми символами или разным форматом данных. Например, значение может содержать пробел в конце строки или неразрывный пробел, скопированный из другого источника. Также дубликаты возникают при сравнении чисел и текста, которые выглядят одинаково, но имеют разный тип. Для проверки используют функции TRIM, CLEAN и форматирование столбца в единый тип.
Как найти дубли, если данные постоянно добавляются новыми строками?
Для таких таблиц применяют формулы с открытым диапазоном, например A2:A, и условное форматирование с пользовательской формулой COUNTIF или COUNTIFS. Правило настраивается один раз и автоматически распространяется на новые строки. При совместной работе дубли отображаются сразу после ввода значения.
Можно ли найти дубли по нескольким столбцам без объединения данных?
Да, для этого используют функцию COUNTIFS, где каждый столбец указывается отдельным условием. Формула подсчитывает строки с полным совпадением значений во всех выбранных колонках. Такой способ подходит для проверки составных ключей, например «email + дата» или «артикул + склад».
Как отметить дубли, не удаляя строки из таблицы?
Добавляют вспомогательный столбец со статусом или числом повторов. Формула COUNTIF возвращает количество совпадений, а функция IF позволяет выводить метку «Дубль» или «Уникально». Исходные данные остаются без изменений, при этом записи легко отфильтровать или отсортировать.
Чем отличается поиск дублей через UNIQUE от COUNTIF?
UNIQUE формирует отдельный список без повторяющихся строк и подходит для сравнения массивов данных. COUNTIF и COUNTIFS работают построчно и показывают, сколько раз значение встречается в исходном диапазоне. UNIQUE удобна для проверки целых строк, а COUNTIF — для анализа конкретных столбцов и пометки дублей прямо в таблице.
Почему формула COUNTIF показывает дубли там, где значения выглядят одинаковыми, но должны считаться разными?
COUNTIF сравнивает значения так, как они хранятся в ячейках, а не как они отображаются на экране. Разница может быть в лишних пробелах, скрытых символах, разных кодировках или типах данных. Например, число, введённое как текст, и число с числовым форматом визуально совпадают, но функция воспринимает их по-разному. Для устранения проблемы применяют TRIM для удаления пробелов, CLEAN для очистки непечатаемых символов и приводят столбец к одному формату через меню «Формат».