Содержание статьи

Извлечение данных из Excel начинается с понимания структуры таблицы: диапазоны, типы данных, наличие заголовков и объединённых ячеек напрямую влияют на результат. Например, формулы поиска работают корректно только при строгом соответствии ключей, а автоматические инструменты обработки требуют преобразования диапазона в «умную таблицу». Ошибка на этом этапе приводит к искажённым значениям или пропущенным строкам.
Выбор способа зависит от задачи. Для получения отдельных значений подойдут формулы вроде XLOOKUP или INDEX, при массовой выборке – фильтры и Power Query, а при интеграции с другими системами – экспорт в CSV или чтение файла через Python. Важно учитывать объём данных: при десятках тысяч строк ручные методы становятся непрактичными, а автоматизация снижает риск человеческих ошибок.
Отдельного внимания требуют случаи, когда данные распределены по нескольким листам или книгам. Здесь применяются ссылки между листами, консолидация или загрузка файлов из папки через Power Query. Для повторяющихся операций имеет смысл использовать VBA-макросы или внешние скрипты, чтобы получать обновлённые данные без ручных действий.
В статье разобраны прикладные способы извлечения данных из Excel с учётом реальных сценариев: отчёты, анализ, перенос в базы данных и обработка в коде. Каждый подход сопровождается рекомендациями по подготовке таблиц и ограничениям, которые важно учитывать до начала работы.
Получение значений ячеек с помощью формул Excel (ВПР, XLOOKUP, INDEX)
Формулы поиска применяются, когда требуется вернуть значение по ключу из табличного диапазона. ВПР работает только при расположении ключевого столбца слева и возвращаемых данных справа. Диапазон должен быть зафиксирован абсолютными ссылками, а параметр точного совпадения установлен в ЛОЖЬ, иначе возможны неверные результаты при несортированных данных.
XLOOKUP снимает ограничения ВПР: поиск возможен в любом направлении, диапазоны задаются отдельно, а при отсутствии совпадения можно указать возвращаемое значение. Это удобно при обработке прайс-листов и справочников, где структура часто меняется. Для стабильной работы рекомендуется ссылаться на столбцы «умной таблицы», а не на статические адреса ячеек.
Связка INDEX и MATCH применяется, когда требуется гибкий контроль над логикой поиска. MATCH определяет позицию строки по ключу, INDEX возвращает значение из нужного столбца по найденному номеру. Такой подход подходит для многокритериальных выборок, если MATCH используется с массивами условий или вложенными вычислениями.
Перед использованием формул данные следует привести к единому формату: удалить лишние пробелы, проверить типы значений и исключить дубликаты ключей. Несоответствие текстовых и числовых форматов – частая причина ошибок #Н/Д. Для диагностики полезно временно вывести результат MATCH, чтобы убедиться в корректности позиции.
При работе с большими таблицами предпочтительно ограничивать диапазоны только используемыми строками и столбцами. Это снижает нагрузку на пересчёт книги и упрощает сопровождение формул при добавлении новых данных.
Отбор строк и столбцов через автофильтр и расширенный фильтр
Автофильтр применяется для быстрого отбора строк по значениям столбцов. Он корректно работает, если таблица имеет одну строку заголовков без пустых ячеек и разрывов. Через меню фильтра можно выбирать конкретные значения, диапазоны чисел, условия по датам, а также текстовые критерии, включая «начинается с» и «содержит». Отфильтрованные данные остаются в исходной таблице и могут быть скопированы в отдельный диапазон.
Для извлечения столбцов автофильтр используется совместно с ручным скрытием ненужных полей или копированием видимых данных. При этом важно учитывать, что скрытые строки не попадают в стандартное копирование, но учитываются в формулах, если не применены специальные функции вроде SUBTOTAL.
Расширенный фильтр предназначен для более сложных условий и массового извлечения данных. Он требует отдельного диапазона критериев, где логика отбора задаётся явно: условия в одной строке работают как И, в разных строках – как ИЛИ. Результат может быть сразу выведен в новый диапазон, что удобно для подготовки отчётов и выгрузок.
Пример структуры диапазона критериев для расширенного фильтра:
| Регион | Продажи | Дата |
|---|---|---|
| Москва | >100000 | >=01.01.2025 |
| Санкт-Петербург | >100000 | >=01.01.2025 |
В данном примере будут извлечены строки по двум регионам с продажами выше заданного порога и датой не ранее указанной. Заголовки критериев должны полностью совпадать с заголовками исходной таблицы, иначе фильтр не сработает.
Для стабильного результата рекомендуется предварительно удалить пустые строки, привести форматы дат и чисел к единому виду и проверять диапазон копирования. Расширенный фильтр не обновляется автоматически при изменении данных, поэтому при регулярной работе его следует запускать повторно или заменять автоматизированными инструментами.
Извлечение данных из нескольких листов одной книги
Работа с несколькими листами требуется, когда данные разделены по периодам, подразделениям или источникам. Самый простой способ – прямые ссылки вида Лист2!A1, которые подходят для точечного получения значений. При этом названия листов должны быть зафиксированы: переименование или удаление листа приведёт к ошибке формулы.
Для суммирования и агрегирования одинаковых диапазонов используется трёхмерная ссылка, например СУММ(Лист1:Лист12!B2). Такой подход работает только при идентичной структуре листов и одинаковом расположении данных. Добавление нового листа внутрь указанного диапазона автоматически включит его в расчёт.
Если требуется извлечь строки по условию с разных листов, применяются массивные формулы на базе ИНДЕКС, ПОИСКПОЗ и ДВССЫЛ. Последняя функция позволяет подставлять имя листа из ячейки, но увеличивает нагрузку на пересчёт и должна использоваться ограниченно, особенно при большом количестве листов.
Для объединения данных в одну таблицу без формул подходит встроенная консолидация. Она позволяет собрать значения по одинаковым заголовкам или позициям, но не сохраняет детализацию строк. Метод уместен для сводных показателей, а не для построчного анализа.
Перед извлечением данных следует проверить единый формат столбцов, отсутствие пустых строк в ключевых диапазонах и совпадение заголовков. Различия в структуре листов приводят к смещению данных и ошибкам при автоматическом объединении.
Загрузка и преобразование данных с помощью Power Query
Power Query применяется для извлечения данных из таблиц Excel с последующей очисткой и преобразованием. Инструмент загружает диапазоны, «умные таблицы» и целые книги, сохраняя связь с источником. При обновлении запроса данные пересобираются автоматически, что удобно при регулярной работе с обновляемыми файлами.
Перед загрузкой рекомендуется привести диапазон к табличному виду, чтобы Power Query корректно распознал заголовки и типы столбцов. В редакторе запросов можно удалить пустые строки, заменить значения, разделить столбцы по разделителю, привести даты и числа к нужному формату. Все действия фиксируются как шаги и выполняются в заданном порядке.
Для объединения данных используются операции Объединить запросы и Добавить запросы. Объединение подходит для подстановки данных из справочников по ключу, а добавление – для склейки однотипных таблиц. При выборе ключевых столбцов важно учитывать регистр, пробелы и типы данных, иначе совпадения не будут найдены.
Power Query позволяет загружать данные сразу из нескольких листов или файлов в папке. В таких сценариях применяется фильтрация по имени листа, расширение вложенных таблиц и удаление служебных столбцов. Это сокращает ручную подготовку данных при работе с ежемесячными или типовыми отчётами.
Результат запроса можно загрузить в лист Excel или только в модель данных. Во втором случае данные используются в сводных таблицах без дублирования на листах. Для стабильной работы рекомендуется минимизировать количество шагов и избегать операций, помеченных как неоптимальные, особенно при больших объёмах строк.
Экспорт данных из Excel в формат CSV для дальнейшей обработки
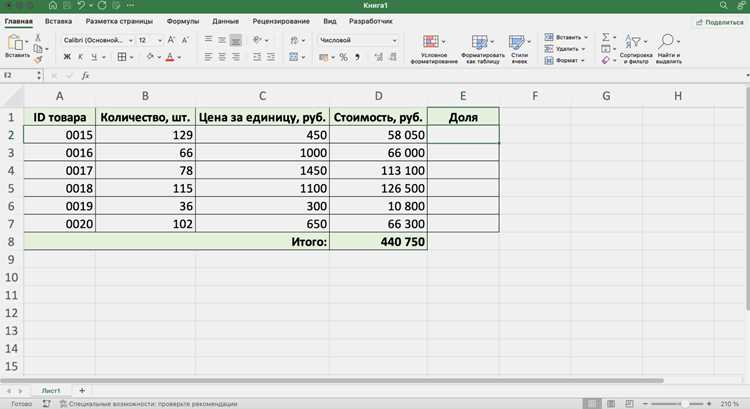
Формат CSV используется для передачи данных между системами без сохранения формул и форматирования. Перед экспортом таблицу следует привести к финальному виду: заменить формулы на значения, удалить скрытые столбцы и проверить разделители в текстовых полях. В CSV сохраняется только активный лист, поэтому нужный диапазон должен быть расположен именно на нём.
При сохранении через пункт Сохранить как важно учитывать региональные настройки. В русскоязычных версиях Excel в качестве разделителя часто используется точка с запятой, а не запятая. Если файл предназначен для обработки в сторонних системах, разделитель и кодировку следует проверить заранее.
Кодировка имеет критическое значение при работе с кириллицей. Стандартный CSV из Excel может открываться с искажёнными символами. Для корректной передачи текста рекомендуется использовать CSV UTF-8 или выполнять повторное сохранение файла через текстовый редактор с явным указанием кодировки.
Даты и числа при экспорте преобразуются в текст согласно локальным форматам. Чтобы избежать ошибок при импорте, даты лучше заранее привести к формату ISO, а числовые значения – проверить на использование десятичного разделителя. Это особенно важно при загрузке данных в базы данных и аналитические платформы.
Для регулярного экспорта целесообразно использовать Power Query или VBA, чтобы формировать CSV-файл автоматически из заданного диапазона. Такой подход снижает риск изменения структуры данных и обеспечивает повторяемость результата при каждом обновлении.
Чтение данных из Excel с использованием Python и библиотеки pandas
Библиотека pandas применяется для извлечения данных из Excel при автоматизации анализа и интеграции с внешними системами. Функция чтения файла позволяет загружать отдельный лист, диапазон столбцов или все листы сразу в виде набора таблиц. Это удобно при обработке отчётов, где структура повторяется, а объём данных превышает возможности ручной работы.
Перед загрузкой файла важно проверить его структуру: наличие строки заголовков, объединённых ячеек и пустых строк в начале листа. Эти элементы напрямую влияют на корректность чтения. Для точного контроля используются параметры указания строки заголовка, списка столбцов и типа данных, чтобы избежать преобразования чисел и дат в текст.
При работе с несколькими листами pandas позволяет обращаться к ним по имени или индексу, а также загружать все листы одновременно для последующего объединения. Такой подход применяется при анализе данных, распределённых по периодам или подразделениям, с последующей склейкой в одну таблицу.
Особое внимание следует уделять кодировке и локальным форматам. Хотя Excel-файлы читаются напрямую, ошибки возникают при наличии нестандартных символов, формул с локальными функциями и смешанных типов данных в одном столбце. Предварительная очистка файла в Excel снижает количество ошибок на этапе загрузки.
После чтения данные сразу доступны для фильтрации, агрегации и экспорта в другие форматы. Это делает pandas удобным инструментом для сценариев, где Excel используется как источник, а основная обработка выполняется вне табличного редактора.
Извлечение данных из Excel через VBA-макросы
VBA-макросы применяются, когда извлечение данных должно выполняться по заданному сценарию без участия пользователя. Макросы получают доступ к ячейкам, диапазонам, листам и книгам, что позволяет забирать данные выборочно, копировать их в другие файлы или подготавливать к экспорту.
Чаще всего VBA используется для автоматического сбора данных по условиям. Типовые задачи включают:
- перебор строк таблицы с проверкой значений в ключевых столбцах;
- копирование подходящих строк в отдельный лист или книгу;
- извлечение данных из закрытых файлов без их открытия на экране;
- объединение данных с нескольких листов в один диапазон.
Для устойчивой работы макроса структура таблицы должна быть предсказуемой. Рекомендуется:
- избегать объединённых ячеек в рабочих диапазонах;
- использовать фиксированную строку заголовков;
- определять последнюю строку и столбец динамически, а не жёсткими адресами;
- работать с массивами в памяти при больших объёмах данных.
При извлечении данных из нескольких листов макрос обычно проходит их в цикле, проверяя имя листа или наличие нужных столбцов. Это удобно для книг, где листы создаются автоматически по шаблону, например, для ежемесячных отчётов.
Для снижения ошибок и ускорения выполнения рекомендуется соблюдать порядок действий:
- отключать обновление экрана и автоматический пересчёт;
- проверять наличие нужных листов и диапазонов перед чтением данных;
- обрабатывать пустые и некорректные значения явно;
- возвращать настройки Excel в исходное состояние после завершения макроса.
VBA целесообразно использовать в случаях, когда стандартные инструменты Excel не позволяют реализовать нужную логику извлечения или требуется полная автоматизация процесса внутри одной книги.
Вопрос-ответ:
Почему формула ВПР возвращает неверные значения или ошибку #Н/Д?
Чаще всего проблема связана с несоответствием ключей. В одной таблице значение может быть числом, а в другой — текстом, визуально они выглядят одинаково, но не совпадают. Также ошибка возникает, если в аргументах формулы указан режим приблизительного поиска или диапазон не зафиксирован. Проверка форматов ячеек и явное указание точного совпадения решают проблему в большинстве случаев.
Как извлечь строки по нескольким условиям без использования формул?
Для этой задачи подходит расширенный фильтр. В отдельном диапазоне задаются условия отбора, где одна строка означает логическое И, а разные строки — ИЛИ. После применения фильтра результат можно сразу вывести в новый диапазон, получив чистую таблицу без лишних данных.
Почему при экспорте в CSV портятся русские буквы?
Причина обычно в кодировке файла. Стандартное сохранение CSV в Excel не всегда использует UTF-8, из-за чего кириллица отображается некорректно. Решение — сохранять файл в формате CSV UTF-8 или повторно открывать его в текстовом редакторе с явным указанием нужной кодировки.
Можно ли собрать данные со всех листов книги в одну таблицу автоматически?
Да, это можно сделать через Power Query или VBA. Power Query подходит, если листы имеют одинаковую структуру и требуется регулярное обновление. VBA используют, когда нужна более сложная логика отбора строк или обработка листов с разными названиями и составом столбцов.
Когда имеет смысл читать Excel через Python, а не средствами самого Excel?
Python удобен, если данные из Excel используются как источник для расчётов, аналитики или загрузки в базы данных. Он позволяет сразу применять фильтрацию, группировку и преобразования без ручных действий. Такой подход особенно полезен при работе с большими файлами и повторяющимися задачами.
Как извлечь данные из Excel, если в таблице есть объединённые ячейки?
Объединённые ячейки мешают формульному поиску, фильтрации и загрузке данных через Power Query или скрипты. Перед извлечением данные лучше привести к плоскому виду: разъединить ячейки и заполнить значения вниз по столбцу. Это можно сделать вручную, через «Найти и заменить» или с помощью Power Query, где доступна команда заполнения пустых строк значениями сверху.
Что выбрать для регулярного извлечения данных: формулы, Power Query или макросы?
Формулы подходят для получения отдельных значений внутри книги и хорошо читаются пользователем. Power Query удобен, если требуется регулярно забирать и преобразовывать таблицы без вмешательства в формулы листа. Макросы применяют, когда нужна жёсткая логика отбора, работа с закрытыми файлами или сохранение результатов в отдельные книги и форматы.