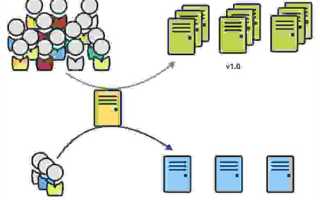
Служба публикации и сбора данных представляет собой систему, которая одновременно выполняет две ключевые задачи: аккумулирует информацию из разных источников и обеспечивает ее целевую доставку пользователям или другим системам. Основное назначение таких служб – снизить ручной труд при обмене данными, ускорить обновление информации и обеспечить единообразие форматов при интеграции с внешними платформами.
Современные службы применяют API, веб-скрейпинг и прямое подключение к базам данных для сбора данных. Для публикации информации используются форматы JSON, XML и CSV, что позволяет подключать аналитические системы, CRM и BI-платформы без необходимости ручной конверсии. Настройка расписания публикаций позволяет обеспечить регулярное обновление данных с точностью до минуты, что важно для мониторинга цен, статистики и логистики.
При организации работы службы важно учитывать управление правами доступа. Разделение пользователей на группы и назначение уровней разрешений предотвращает случайное изменение исходных данных и позволяет отслеживать историю публикаций. Одновременно контроль качества входящей информации – проверка на дубликаты, валидация форматов и автоматическое уведомление о некорректных записях – снижает ошибки на стадии интеграции.
Интеграция с внешними системами и аналитикой дает возможность не только передавать данные, но и оптимизировать процессы на основе фактической информации. Настройка логирования, мониторинга и аналитических отчетов позволяет выявлять узкие места в потоках данных и корректировать их без остановки работы службы.
Как службы публикации собирают данные с разных источников
Сбор данных начинается с идентификации источников: это могут быть базы данных SQL и NoSQL, облачные хранилища, веб-сервисы и открытые API. Для подключения к базам данных применяются драйверы JDBC/ODBC с настройкой прав доступа, позволяющей считывать только необходимые таблицы и поля. Для облачных платформ используются встроенные SDK и протоколы OAuth 2.0 для безопасной авторизации и ограниченного доступа.
Для извлечения информации с веб-ресурсов службы используют методы веб-скрейпинга с определением селекторов HTML и XPath, а также автоматизированные запросы к REST и GraphQL API. Важным этапом является фильтрация данных на этапе извлечения: исключаются дубликаты, нерелевантные строки и записи с некорректной структурой, чтобы уменьшить нагрузку на последующую обработку.
Сбор потоковой информации из сенсорных сетей, логов и телеметрии осуществляется через протоколы MQTT и WebSocket, что обеспечивает получение данных в реальном времени. Для обработки больших объемов используется пакетная загрузка и буферизация, позволяющая агрегировать данные перед записью в центральное хранилище.
Для интеграции разных форматов применяется конвертация и нормализация: JSON, XML и CSV приводятся к единому формату, а значения полей проверяются по схемам и бизнес-правилам. Рекомендуется создавать отдельные рабочие очереди для каждого типа источника, что позволяет локализовать ошибки и поддерживать стабильность службы при расширении числа источников.
Методы автоматизации публикации информации
Автоматизация публикации реализуется через планировщики задач, триггерные скрипты и интеграцию с API целевых систем. Планировщики, такие как Cron и Windows Task Scheduler, позволяют запускать публикацию по фиксированному расписанию с указанием конкретных файлов и форматов данных. Триггерные скрипты активируются при обновлении данных в источнике, обеспечивая мгновенную передачу информации без задержек.
Использование API и вебхуков позволяет автоматически передавать данные в CRM, BI-системы или внешние порталы. Для каждой интеграции создаются отдельные обработчики с проверкой статусов отправки и логированием ошибок, что предотвращает потерю информации и дублирование.
Для структурированных данных применяются шаблоны и конвертеры, которые преобразуют исходные форматы (JSON, XML, CSV) в требуемые для системы получателя. Встроенные фильтры исключают нерелевантные записи и приводят данные к единым схемам, минимизируя необходимость ручной корректировки после публикации.
Рекомендуется создавать систему уведомлений о статусе публикации: успешная отправка, частичные ошибки или отказ системы получателя. Это позволяет оперативно реагировать на сбои и снижает риск накопления неконсистентных данных в центральных хранилищах.
Форматы и стандарты обмена данными
Службы публикации и сбора данных используют стандартизированные форматы для передачи информации между системами. Наиболее распространены JSON, XML и CSV, которые обеспечивают структурированное хранение и позволяют автоматически считывать поля и значения без ручной обработки. JSON применяют для API и веб-приложений, XML используют при интеграции с корпоративными системами, а CSV подходит для пакетной передачи больших таблиц данных.
При выборе формата важно учитывать требования к схемам и валидации. JSON Schema и XSD позволяют описывать структуру данных и автоматически проверять соответствие входящей информации установленным правилам. Для CSV рекомендуется заранее определять разделители и кодировку, чтобы избежать ошибок при импорте в системы получателя.
Существует несколько стандартов обмена данными, которые обеспечивают совместимость между платформами. SOAP и REST определяют правила работы веб-сервисов, включая формат сообщений, методы запросов и коды ошибок. Для обмена финансовыми и логистическими данными применяются отраслевые стандарты, такие как EDI и ISO 20022, которые гарантируют правильную интерпретацию полей и предотвращают потерю информации.
Рекомендуется внедрять таблицу соответствия форматов и схем для всех источников данных, что позволяет быстро адаптировать публикацию при подключении новых систем или обновлении существующих. Пример структуры сопоставления может выглядеть так:
| Источник | Формат | Схема | Назначение |
|---|---|---|---|
| CRM | JSON | CRM_Schema_v2 | Передача клиентов в BI |
| ERP | XML | ERP_Order_v1 | Обновление заказов в складской системе |
| Лог-файлы | CSV | Log_Format_v3 | Аналитика и отчетность |
Настройка расписания публикации и обновления данных

Расписание публикации определяется частотой обновления данных и требованиями к актуальности информации. Для источников с высокой динамикой, например, цен или логистических статусов, рекомендуется устанавливать интервал обновления от 1 до 5 минут. Для аналитических отчетов и сводных данных достаточно ежедневного или еженедельного обновления.
Используются планировщики задач, такие как Cron для Linux и Task Scheduler для Windows, позволяющие запускать скрипты публикации по заданному времени. Важно настраивать отдельные задания для разных типов данных, чтобы сбой в одной очереди не останавливал обновление других потоков.
При настройке расписания необходимо предусмотреть контроль выполнения: проверка логов, уведомления о неудачных запусках и повторные попытки публикации. Рекомендуется устанавливать лимиты времени выполнения задач и включать timeout для API-запросов, чтобы система не зависала на проблемных источниках.
Для потоковой информации применяются триггеры и вебхуки, которые активируют публикацию сразу после появления новых данных. Такой подход уменьшает задержку между сбором и публикацией и обеспечивает более точную актуальность информации без постоянного опроса источников.
Управление доступом и правами пользователей

В службах публикации и сбора данных критически важно разграничение прав пользователей для предотвращения случайного или несанкционированного изменения информации. Настройка прав выполняется на нескольких уровнях:
- Определение ролей: администратор, редактор, читатель. Администратор управляет источниками и расписанием публикаций, редактор может изменять и проверять данные, читатель только просматривает результаты.
- Контроль доступа к источникам: для каждой базы данных, API или хранилища задаются права чтения и записи, что исключает доступ к чувствительным или нерелевантным данным.
- Логирование действий: фиксируются все изменения данных и операций публикации, включая дату, время и пользователя, что позволяет отслеживать ошибки и проводить аудит.
- Многофакторная аутентификация: обязательное использование пароля и дополнительного токена снижает риск несанкционированного доступа.
Для оптимизации работы рекомендуется:
- Регулярно пересматривать и актуализировать роли пользователей при изменении состава команды.
- Использовать принцип минимальных прав, предоставляя каждому пользователю только необходимый набор возможностей.
- Настраивать уведомления о попытках доступа к запрещённым ресурсам, чтобы быстро реагировать на потенциальные угрозы.
Интеграция с внешними системами и платформами
Интеграция позволяет службе публикации и сбора данных автоматически передавать информацию в сторонние системы и получать данные из них без ручного вмешательства. Наиболее распространенные методы включают использование REST и SOAP API, вебхуков и очередей сообщений (RabbitMQ, Kafka) для обмена данными в реальном времени.
При подключении внешних платформ важно согласовать форматы данных и схемы. JSON и XML остаются основными форматами для API, а CSV или Parquet применяются для пакетной передачи больших объемов данных. Рекомендуется внедрять валидацию на этапе интеграции, проверяя структуру и значения полей по заранее заданным схемам, чтобы предотвратить некорректные записи в целевой системе.
Для устойчивой работы интеграции используется мониторинг статусов отправки и логирование ошибок. При отказе внешней системы настройка повторных попыток и очередь сообщений позволяет гарантировать доставку данных без потерь. Важно также использовать аутентификацию и шифрование (OAuth 2.0, TLS), чтобы обеспечить безопасность передачи и соответствие требованиям корпоративной политики.
Рекомендуется создавать отдельные коннекторы для каждого типа платформ, что упрощает масштабирование и поддержку интеграций. Такой подход позволяет быстро подключать новые источники и минимизировать влияние сбоев одной системы на остальные потоки данных.
Мониторинг и контроль качества поступающих данных
Для поддержания точности и целостности информации службы публикации и сбора данных внедряют постоянный мониторинг источников. Контроль начинается с валидации форматов: проверяются соответствие JSON или XML схемам, наличие обязательных полей и корректность типов данных. Для табличных данных CSV проводится проверка разделителей, кодировки и уникальности ключевых значений.
На этапе обработки используются фильтры для удаления дубликатов, исключения пустых или нерелевантных записей и нормализации значений. Рекомендуется внедрять правила бизнес-логики, например, диапазоны допустимых числовых значений или проверку существующих идентификаторов в связанных таблицах.
Мониторинг также включает автоматическую генерацию уведомлений о некорректных данных и отклонениях от ожидаемого объема поступающих записей. Для потоковой информации полезно использовать системы метрик и дашборды, отображающие скорость поступления данных, частоту ошибок и задержки между получением и публикацией.
Для комплексного контроля качества рекомендуется внедрять регулярные отчеты о проверках данных и логи изменений, что позволяет быстро выявлять источники проблем и корректировать процессы без остановки службы.
Использование аналитики для оптимизации потоков данных

Аналитика позволяет выявлять узкие места и повышать производительность служб публикации и сбора данных. Сбор метрик включает объемы поступающих данных, скорость обработки, количество ошибок и задержки между источником и публикацией.
- Анализ частоты ошибок и отклонений от ожидаемых объемов помогает выявить нестабильные источники данных.
- Сравнение времени обработки разных типов данных позволяет перераспределять ресурсы и оптимизировать очереди задач.
- Использование агрегированных показателей, таких как среднее время публикации и процент успешных транзакций, позволяет оценивать эффективность текущих процессов.
Рекомендуется внедрять автоматические отчеты и визуализацию потоков данных через дашборды. Это позволяет:
- Отслеживать производительность всех подключенных источников в реальном времени.
- Принимать решения о расширении вычислительных ресурсов или изменении расписания публикаций.
- Определять приоритеты обработки для критичных данных и минимизировать задержки в системах, требующих актуальной информации.
На основе аналитики можно создавать сценарии оптимизации: объединение мелких потоков в пакеты, перераспределение задач между серверами и внедрение предиктивного масштабирования для источников с переменной нагрузкой.
Вопрос-ответ:
Какие источники данных обычно подключаются к службе публикации и сбора данных?
Службы работы с данными интегрируются с разными типами источников: локальные и облачные базы данных (SQL, NoSQL), веб-сервисы и API, лог-файлы, сенсорные сети, а также CSV и другие файлы, поступающие от внешних систем. Подключение происходит через драйверы, SDK или протоколы передачи данных с настройкой прав доступа для каждого источника.
Какие методы автоматизации публикации информации применяются на практике?
Автоматизация выполняется через планировщики задач (Cron, Task Scheduler), скрипты, активируемые изменением данных, и интеграцию с API целевых систем. Используются вебхуки для мгновенной передачи информации, а также шаблоны конвертации данных в нужные форматы. Настройка уведомлений о результатах публикации позволяет отслеживать ошибки и повторно отправлять данные в случае сбоев.
Как проводится контроль качества поступающих данных?
Контроль качества включает проверку форматов (JSON, XML, CSV) по схемам, удаление дубликатов и пустых строк, а также верификацию данных по бизнес-правилам, например, диапазону значений или существованию связанных идентификаторов. Дополнительно ведется логирование ошибок и уведомления о нарушениях структуры данных. Для потоковой информации используют дашборды, отображающие скорость и количество ошибок, что позволяет локализовать проблемы.
Какие форматы и стандарты обмена данных применяются для интеграции с внешними системами?
Наиболее часто применяются JSON и XML для API, CSV и Parquet для пакетной передачи. Стандарты SOAP и REST определяют структуру запросов и сообщений. Для финансовых и логистических данных могут использоваться отраслевые форматы EDI и ISO 20022. Службы публикуют данные с проверкой соответствия схемам и кодировкам, чтобы целевые системы корректно интерпретировали информацию.
Как аналитика помогает улучшить работу службы публикации и сбора данных?
Аналитика собирает показатели потока данных, включая объем, скорость обработки и количество ошибок. Эти метрики помогают выявить узкие места и определить источники с нестабильной отдачей. Используя отчеты и визуализацию потоков, можно перераспределять ресурсы, изменять расписание задач и приоритизировать критичные данные. Дополнительно анализ позволяет оптимизировать очереди и внедрять пакетную обработку для ускорения передачи больших объемов информации.
Как настроить службу публикации и сбора данных для работы с большим количеством источников без потери точности?
При работе с множеством источников важно разделять потоки данных по типам и частоте обновления. Для каждого источника создаются отдельные задачи с указанием форматов и схем данных. Потоковая информация обрабатывается через очереди сообщений или вебхуки, чтобы минимизировать задержки и избежать дублирования. Для пакетной передачи больших массивов используют буферизацию и проверку целостности, а ошибки фиксируются в логах с уведомлениями. Дополнительно рекомендуется внедрять регулярную проверку схем и бизнес-правил, чтобы несоответствия данных выявлялись до публикации и не нарушали работу других интеграций.