Содержание статьи

Задача подсчета одинаковых элементов в списке возникает при анализе логов, обработке пользовательского ввода, агрегации данных и подготовке статистики. В Python для этого доступны как встроенные методы списков, так и инструменты стандартной библиотеки, позволяющие получать точные частоты значений без ручной сортировки данных.
Выбор подхода напрямую зависит от объема списка и формата элементов. Для единичного значения достаточно метода list.count(), однако при необходимости получить распределение всех элементов предпочтение отдается collections.Counter или работе со словарями. Эти способы позволяют за один проход по списку сформировать структуру вида «элемент → количество повторений».
Отдельного внимания требует учет типов данных и регистра строк. В одном списке могут одновременно присутствовать числа, строки и булевы значения, а строковые элементы могут отличаться только регистром символов. Без предварительной нормализации такие различия приводят к искаженным результатам подсчета.
Практика показывает, что для списков до нескольких тысяч элементов допустимы любые базовые способы, тогда как при работе с десятками и сотнями тысяч значений критично выбирать алгоритмы с линейной сложностью и минимальным количеством проходов по данным. Именно поэтому понимание доступных инструментов Python позволяет избежать лишних вычислений и ошибок при анализе данных.
Подсчет количества конкретного элемента методом list.count()
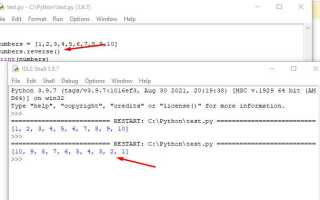
Метод list.count() применяется, когда требуется узнать, сколько раз конкретное значение встречается в списке. Он принимает один аргумент – искомый элемент – и возвращает целое число, соответствующее количеству совпадений. Метод выполняет полный проход по списку и сравнивает каждый элемент по правилу равенства.
Результат зависит от типа данных и способа сравнения. Числа сравниваются по значению, строки – с учетом регистра, а логические значения учитываются как отдельный тип, несмотря на числовую природу. Например, значение True не будет подсчитано как 1, если в списке явно присутствуют целые числа.
Метод подходит для разовых проверок, таких как подсчет количества ошибок с конкретным кодом или поиск повторений одного маркера. При многократных вызовах для разных элементов на одном и том же списке нагрузка возрастает, так как каждый вызов запускает новый проход по данным.
Перед использованием рекомендуется убедиться, что список не содержит вложенных структур или изменяемых объектов, для которых сравнение может дать неожиданный результат. Для строковых данных полезно заранее привести значения к одному регистру, если требуется учитывать визуально одинаковые элементы как равные.
Метод возвращает 0, если элемент отсутствует, что упрощает логику проверки без дополнительных условий. Это позволяет напрямую использовать результат в расчетах и условиях, не опасаясь исключений.
Использование collections.Counter для подсчета всех повторяющихся значений

Класс Counter из модуля collections предназначен для подсчета частот всех элементов списка за один проход. На вход передается итерируемый объект, а на выходе формируется словарь, где ключами становятся элементы списка, а значениями – количество их появлений.
Counter корректно работает с любыми хешируемыми типами данных:
- целыми и вещественными числами;
- строками и кортежами;
- булевыми значениями;
- результатами пользовательских вычислений.
Полученную структуру удобно использовать для анализа данных. Например, можно быстро определить элементы с несколькими повторениями или отфильтровать уникальные значения:
- получение самых частых элементов через метод most_common();
- удаление элементов с нулевым счетчиком без дополнительной проверки;
- прямой доступ к количеству конкретного элемента по ключу.
При отсутствии ключа Counter возвращает 0, что упрощает логику проверки и исключает необходимость использования try/except. Это особенно удобно при обработке пользовательского ввода или логов, где набор значений заранее неизвестен.
Для строковых данных рекомендуется предварительная нормализация, так как Counter не объединяет значения с разным регистром или форматированием. При необходимости допускается обновление счетчиков с помощью метода update(), что позволяет накапливать статистику из нескольких списков без пересчета предыдущих результатов.
Подсчет элементов через словарь и цикл for

Подсчет повторяющихся элементов с помощью словаря и цикла for позволяет полностью контролировать логику обработки списка. В качестве ключей используются элементы списка, а значения словаря хранят количество их появлений. Такой подход подходит для ситуаций, где требуется дополнительная проверка, преобразование или фильтрация данных во время подсчета.
Базовая схема работы включает последовательный перебор списка и обновление счетчика для каждого элемента. При первом появлении элемента создается новая запись в словаре, при повторном – значение увеличивается. Для упрощения кода часто используется метод dict.get() с указанием начального значения.
Словарь позволяет встроить в процесс подсчета дополнительные условия, например пропуск пустых значений, объединение строк с разным регистром или преобразование чисел перед учетом. Это делает способ универсальным для предварительно неструктурированных данных.
| Особенность | Описание |
|---|---|
| Гибкость логики | Возможность изменять или фильтровать элементы прямо в цикле |
| Типы данных | Поддержка любых хешируемых объектов |
| Контроль условий | Легкое добавление проверок и преобразований |
| Читаемость | Явная логика подсчета без скрытых механизмов |
Такой подход оправдан при работе со сложными структурами данных или при необходимости интеграции подсчета в более широкий алгоритм обработки. Для простых сценариев он может быть избыточным, однако в задачах анализа данных словарь и цикл for остаются базовым и надежным инструментом.
Получение частот с помощью set и генераторов списков

Связка set и генераторов списков применяется для подсчета повторений без использования дополнительных структур данных. Множество формируется на основе списка и содержит только уникальные элементы, после чего для каждого значения выполняется отдельный подсчет.
Типовая схема работы строится следующим образом:
- создание множества из исходного списка для удаления дубликатов;
- перебор уникальных элементов;
- подсчет количества совпадений через генератор с условием равенства.
Такой способ удобен для быстрого получения частот в компактной форме, например в виде словаря или списка кортежей. Генераторы позволяют избежать создания промежуточных списков и сразу возвращают числовой результат.
Метод корректно работает с хешируемыми типами данных и сохраняет различия между значениями по регистру и типу. Для строковых данных рекомендуется предварительно привести элементы к единому формату, иначе визуально одинаковые значения будут учитываться раздельно.
Подход имеет ограничение по масштабируемости, так как для каждого уникального элемента выполняется отдельный проход по списку. Его целесообразно использовать при небольшом количестве уникальных значений или в задачах, где читаемость кода важнее минимизации числа операций.
- подходит для кратких одноразовых вычислений;
- не требует импорта модулей;
- удобен для встроенных выражений и inline-расчетов.
Подсчет элементов с учетом регистра и типов данных

При подсчете повторяющихся элементов важно учитывать, что Python различает значения не только по содержимому, но и по типу данных. Строки «Python» и «python» считаются разными элементами, так же как число 1 и логическое значение True, несмотря на их числовое сходство.
Для корректного подсчета строковых данных рекомендуется предварительная нормализация. Чаще всего используется приведение к нижнему или верхнему регистру, а также удаление лишних пробелов. Такие преобразования выполняются до запуска механизма подсчета, иначе статистика будет раздроблена на формально разные значения.
Смешанные типы данных требуют явного решения: учитывать ли их раздельно или приводить к общему формату. Например, при анализе пользовательского ввода числа могут приходить как строки, что приведет к раздельному учету значений «10» и 10. Приведение типов на этапе подготовки данных устраняет эту проблему.
Особое внимание стоит уделять булевым значениям. В словарях и счетчиках True и 1 могут конфликтовать из-за одинакового хеш-значения, если данные не были заранее проверены. Явная фильтрация или преобразование булевых элементов позволяет избежать искажения результатов.
Четкое определение правил сравнения до начала подсчета снижает количество логических ошибок и делает итоговую статистику предсказуемой, особенно при обработке данных из внешних источников.
Сравнение подходов по скорости работы и потреблению памяти
Метод list.count() выполняет полный проход по списку при каждом вызове, поэтому при подсчете нескольких элементов суммарное время растет пропорционально количеству запросов. По памяти он почти не создает накладных расходов, так как не формирует дополнительных структур данных.
Использование collections.Counter требует одного прохода по списку и хранения отдельного словаря частот. Время выполнения линейно зависит от длины списка, а потребление памяти увеличивается на размер словаря, равный количеству уникальных элементов. Для повторного доступа к частотам дополнительных вычислений не требуется.
Подсчет через словарь и цикл for имеет схожие характеристики с Counter: один проход по данным и хранение всех уникальных значений. Разница проявляется в ручной логике обработки, которая может добавить дополнительные операции, если в цикле выполняются проверки или преобразования.
Комбинация set и генераторов списков выполняет отдельный проход по списку для каждого уникального элемента. При большом количестве уникальных значений общее время заметно увеличивается. По памяти подход экономичен, так как хранится только множество и временные счетчики.
Для единичного подсчета одного значения допустим list.count(). При анализе всего распределения элементов предпочтительнее Counter или словарь. Способы с set оправданы при небольших наборах данных или разовых вычислениях, где не требуется хранить результаты для повторного использования.
Вопрос-ответ:
Почему list.count() возвращает разные результаты для 1 и True в одном списке?
В Python значения 1 и True логически связаны, но относятся к разным типам данных. Метод list.count() сравнивает элементы по равенству, а не по типу, поэтому True может быть засчитан как 1 при определенных наборах данных. Если требуется строгий учет, необходимо заранее отфильтровать булевы значения или привести элементы к нужному типу.
Какой способ подсчета лучше использовать, если нужно многократно получать количество разных элементов?
Для таких задач удобнее заранее построить словарь частот или использовать collections.Counter. Это позволяет один раз пройти по списку и затем получать количество любого элемента по ключу без повторных вычислений.
Можно ли подсчитывать элементы списка, содержащего строки и числа одновременно?
Да, все стандартные способы подсчета работают с любыми хешируемыми типами. Проблемы возникают, если числа представлены в виде строк. В этом случае значения «5» и 5 будут учитываться отдельно, поэтому перед подсчетом желательно привести данные к единому формату.
Почему подсчет через set и генераторы работает медленнее на больших списках?
Множество содержит только уникальные элементы, но для каждого из них выполняется отдельный проход по исходному списку. При большом количестве уникальных значений это приводит к многократному перебору одних и тех же данных и увеличению времени выполнения.
Как избежать ошибок при подсчете строк с разным регистром?
Перед подсчетом строки следует привести к одному регистру, например с помощью lower() или upper(). Это гарантирует, что значения вроде «Python», «PYTHON» и «python» будут учтены как один элемент, а не как разные записи.
Почему Counter может объединять значения 1 и True при подсчете?
В Python логический тип является подклассом целых чисел, поэтому True и 1 имеют одинаковое хеш-значение и считаются равными ключами. При использовании Counter это приводит к объединению счетчиков. Чтобы избежать такого поведения, булевы значения следует исключить или привести все элементы к строковому виду до подсчета.
Как подсчитать частоты элементов, если список формируется постепенно в цикле?
Для накапливающегося списка удобнее сразу увеличивать счетчики по мере добавления элементов. Это можно реализовать через обычный словарь с увеличением значения по ключу или с помощью Counter и его метода update(), передавая туда новые элементы без пересчета уже обработанных данных.