Содержание статьи

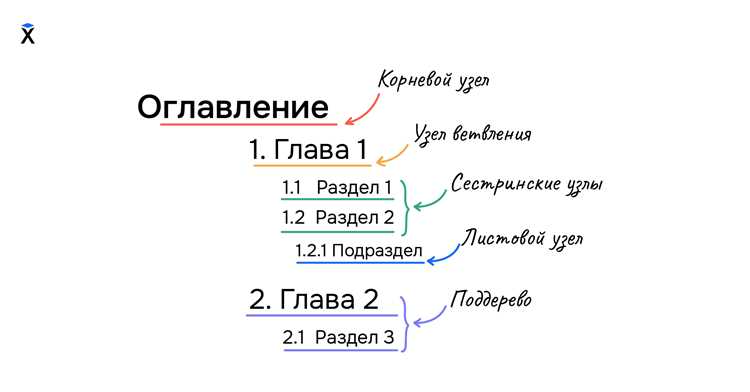
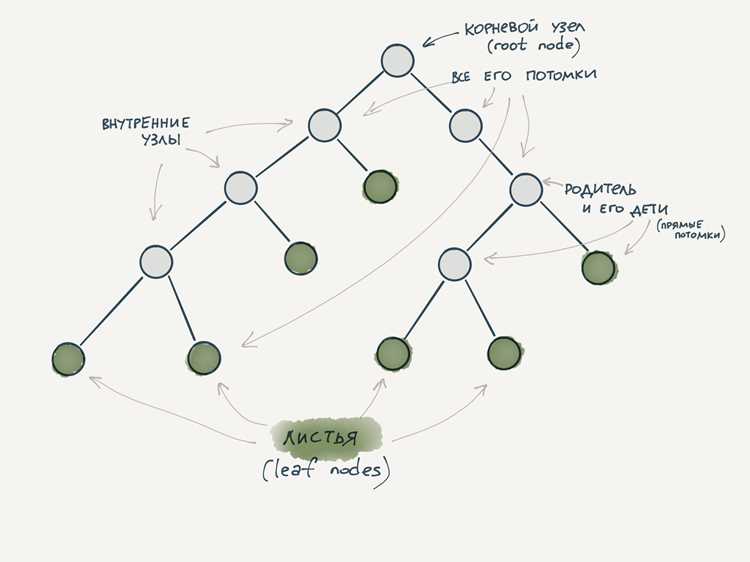
Структура данных «дерево» используется для представления иерархических связей между элементами. В отличие от массива или списка, где элементы располагаются линейно, дерево позволяет хранить данные с подчинёнными зависимостями. Каждый элемент, называемый узлом, может иметь потомков, а вершина без родителя является корнем.
Деревья применяются в парсинге выражений, организации файловых систем, индексировании баз данных и поисковых алгоритмах. Например, бинарное дерево поиска ускоряет доступ к элементам за счёт упорядочивания значений, а дерево решений используется при обучении моделей машинного обучения.
Понимание внутренней структуры дерева помогает оптимально выбирать тип реализации для конкретной задачи. От того, как организованы связи между узлами и как выполняется обход, зависит скорость вставки, удаления и поиска данных. Разработка дерева требует точного определения связей между элементами и выбора подходящего способа хранения – указатели, массивы или объекты классов.
Что представляет собой структура данных «дерево»
Главное свойство дерева – отсутствие циклов: путь от любого узла к другому единственный. Это делает структуру удобной для представления зависимостей, например, каталогов в файловой системе или элементов интерфейса. Каждый узел хранит значение и ссылки на своих потомков, что упрощает реализацию на языках с поддержкой указателей и объектов, таких как C++, Java или Python.
На практике деревья бывают разных типов: бинарные, где у узла не более двух потомков; сбалансированные, поддерживающие равномерную высоту ветвей; N-арные, где число потомков заранее не ограничено. Выбор конкретного вида зависит от задач – ускорения поиска, оптимизации памяти или организации структуры данных для алгоритмов сортировки и анализа.
Основные элементы дерева: узлы, корень и листья
Каждый узел хранит данные и ссылки на связанные элементы. В бинарном дереве таких ссылок две – на левый и правый дочерние узлы. В более сложных структурах число связей может быть произвольным. При реализации дерева в памяти связи обычно оформляются через указатели или ссылки на объекты. Это позволяет гибко изменять структуру: добавлять новые узлы, перемещать ветви и удалять элементы без перестройки всей системы.
Корень задаёт контекст всей структуры, поэтому при его удалении необходимо переопределять иерархию. Для обеспечения стабильности стоит предусмотреть методы повторного выбора корня или восстановления поддеревьев. При работе с листьями важно учитывать их роль в обходе дерева – они часто используются как точки завершения рекурсивных операций и критерии остановки поиска.
Различия между бинарными, сбалансированными и поисковыми деревьями
Бинарное дерево – структура, где каждый узел имеет не более двух потомков: левый и правый. Такое ограничение упрощает реализацию и обработку данных. Бинарные деревья часто служат основой для более специализированных вариантов, например, для построения деревьев поиска или балансированных структур.
Сбалансированное дерево поддерживает равномерную высоту ветвей, что предотвращает смещение структуры в одну сторону и сохраняет производительность операций на уровне O(log n). Примеры таких реализаций – AVL-дерево и красно-чёрное дерево. Они автоматически перестраивают связи при добавлении или удалении узлов, удерживая равновесие между поддеревьями.
Дерево поиска организует данные по принципу: значения в левом поддереве меньше значения родителя, а в правом – больше. Это правило обеспечивает быстрый поиск и сортировку. Однако без балансировки дерево поиска может деградировать в линейную структуру при последовательном добавлении упорядоченных данных. Чтобы избежать этого, применяют самобалансирующиеся деревья, где порядок элементов сохраняется без потери симметрии.
Как происходит обход дерева: прямой, симметричный и обратный
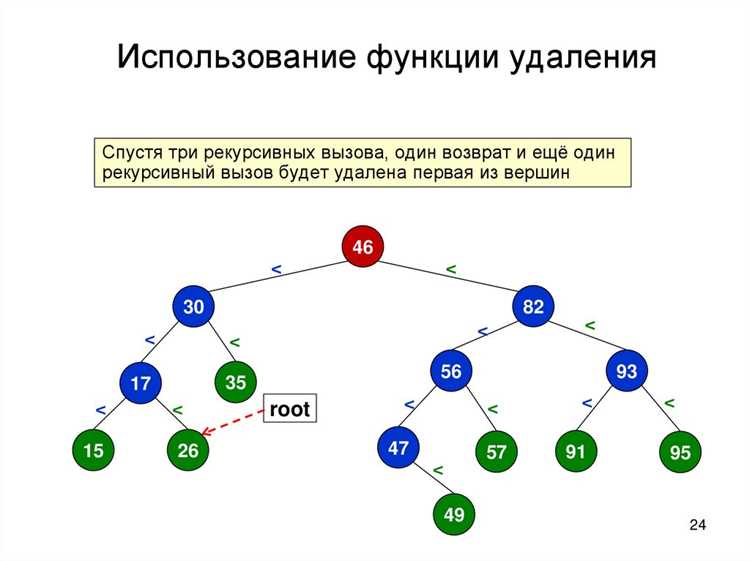
- Прямой обход выполняется в порядке: текущий узел → левое поддерево → правое поддерево. Этот вариант подходит для копирования структуры и последовательного сохранения элементов. Пример вызова рекурсивной функции: сначала обработка узла, затем рекурсивный вызов для потомков.
- Симметричный обход проходит через левое поддерево → текущий узел → правое поддерево. Он используется, когда требуется получить значения в отсортированном порядке. Для бинарного дерева поиска результатом будет последовательный список элементов по возрастанию.
- Обратный обход выполняется в последовательности: левое поддерево → правое поддерево → текущий узел. Такой подход применяется при удалении узлов, чтобы не потерять ссылки на потомков до завершения работы с поддеревом.
На практике обход реализуется рекурсивно или с использованием стека. Рекурсивный вариант проще для чтения и подходит для небольших структур, тогда как итеративный с явным стеком предпочтителен при работе с глубокими деревьями, чтобы избежать переполнения стека вызовов.
Где применяются деревья при разработке программ
Деревья используются во множестве прикладных задач, где требуется организовать данные с иерархией или ускорить поиск. В компиляторах они формируют абстрактное синтаксическое дерево, отражающее структуру исходного кода. Каждый узел такого дерева представляет оператор, выражение или идентификатор, что упрощает анализ и генерацию машинных инструкций.
В базах данных применяются B-деревья и их разновидности. Эти структуры обеспечивают быстрый доступ к индексам на диске и сохраняют баланс при добавлении записей. Благодаря этому операции поиска, вставки и удаления выполняются за логарифмическое время независимо от размера таблицы.
В графических интерфейсах элементы интерфейса часто организованы в дерево виджетов, где каждый компонент связан с родительским контейнером. Такая структура позволяет обрабатывать события, перерисовку и обновление интерфейса без избыточных вычислений. Аналогичный принцип используется в DOM-дереве браузеров, где узлы представляют теги HTML.
В алгоритмах машинного обучения применяются деревья решений, которые классифицируют данные на основе последовательных проверок признаков. В файловых системах деревья обеспечивают хранение путей и быстрый переход между каталогами. Эти примеры демонстрируют, что деревья лежат в основе множества ключевых механизмов программных систем.
Как реализовать дерево на примере кода на Python

Для создания дерева в Python обычно используют классы для узлов и структуры дерева. Каждый узел хранит значение и ссылки на потомков. Простейший вариант – бинарное дерево:
class Node:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
Дерево создаётся добавлением объектов узлов и связыванием их через атрибуты left и right:
root = Node(10)
root.left = Node(5)
root.right = Node(15)
root.left.left = Node(3)
root.left.right = Node(7)
Для обхода дерева применяют рекурсивные функции:
- Прямой обход:
def preorder(node):
if node:
print(node.value)
preorder(node.left)
preorder(node.right)
def inorder(node):
if node:
inorder(node.left)
print(node.value)
inorder(node.right)
def postorder(node):
if node:
postorder(node.left)
postorder(node.right)
print(node.value)
Для расширенных задач, таких как сбалансированные деревья или деревья поиска, добавляют методы вставки, удаления и поиска, учитывающие свойства структуры. Использование классов позволяет инкапсулировать логику работы с узлами и облегчает масштабирование дерева при увеличении объёма данных.
Типичные ошибки при построении и работе с деревьями

При реализации деревьев часто встречаются ошибки, которые приводят к некорректной работе алгоритмов или потере данных. Основные проблемы связаны с нарушением структуры, неправильным управлением ссылками и некорректным обходом узлов.
| Ошибка | Описание | Рекомендации |
|---|---|---|
| Неправильное связывание узлов | Узлы могут быть добавлены в произвольном порядке, что нарушает свойства дерева (например, дерева поиска). | Проверять правила вставки и соблюдать ограничения на число потомков для конкретного типа дерева. |
| Удаление корня без перераспределения | Удаление корня без выбора нового может сделать поддеревья недоступными. | Использовать алгоритмы замены корня на минимальный элемент правого поддерева или максимальный левый элемент. |
| Переполнение стека при рекурсии | Глубокие деревья вызывают ошибки при рекурсивном обходе. | Использовать итеративные обходы с явным стеком или ограничивать глубину дерева. |
| Нарушение баланса | В деревьях поиска или сбалансированных деревьях несоблюдение равновесия увеличивает время операций. | Применять самобалансирующиеся алгоритмы, такие как AVL или красно-чёрные деревья. |
| Дублирование ссылок | Узлы могут случайно ссылаться на один и тот же объект, создавая циклы. | Проверять уникальность узлов и избегать прямых циклических ссылок. |
Соблюдение этих правил помогает предотвратить логические ошибки и гарантировать корректное выполнение операций с деревьями в любых приложениях.
Как оценить сложность операций в различных типах деревьев
Сложность операций с деревьями зависит от их структуры и высоты. В бинарном дереве поиска среднее время поиска, вставки и удаления пропорционально O(log n), если дерево сбалансировано. При несбалансированной структуре, например, при последовательной вставке упорядоченных данных, сложность может вырасти до O(n).
Для сбалансированных деревьев, таких как AVL или красно-чёрные, алгоритмы перестройки поддерживают высоту на уровне O(log n), что гарантирует стабильное время операций. Вставка и удаление требуют дополнительных проверок баланса, но они не превышают логарифмической сложности.
В N-арных деревьях время поиска зависит от максимального числа потомков у узла. Если каждый узел содержит k детей, глубина дерева уменьшается, но проверка каждого потомка увеличивает количество операций до O(k·h), где h – высота дерева.
При оценке сложности важно учитывать:
- Высоту дерева и распределение узлов
- Количество потомков на каждом уровне
- Тип выполняемых операций – поиск, вставка, удаление, обход
Рекомендуется моделировать дерево на небольших объёмах данных и измерять время операций для выявления узких мест перед применением структуры в производственных системах.
Вопрос-ответ:
Что такое дерево в программировании и чем оно отличается от списка или массива?
Дерево — это структура данных, состоящая из узлов, связанных иерархически. В отличие от списка или массива, где элементы хранятся последовательно, дерево позволяет строить отношения «родитель–потомок». Корень дерева соединяет все элементы, а листья завершают ветви. Такая организация подходит для представления каталогов, парсинга выражений и реализации алгоритмов поиска с учётом структуры данных.
Как устроен узел дерева и какие данные он хранит?
Узел дерева хранит значение и ссылки на своих потомков. В бинарных деревьях каждый узел имеет максимум два потомка — левый и правый. В N-арных деревьях количество потомков не ограничено. Узлы могут содержать дополнительные данные, такие как ключи для поиска, указатели на родителя или балансирующую информацию для поддержания структуры дерева.
В чём разница между бинарным деревом поиска и сбалансированным деревом?
Бинарное дерево поиска упорядочивает значения так, что все элементы в левом поддереве меньше узла, а в правом — больше. Однако при последовательной вставке данных дерево может стать линейным, что замедляет операции. Сбалансированное дерево автоматически перестраивает связи при добавлении и удалении узлов, поддерживая равномерную высоту ветвей и сохраняя время операций поиска, вставки и удаления на уровне логарифма от числа узлов.
Какие методы обхода дерева существуют и для чего они применяются?
Основные методы обхода дерева — прямой (preorder), симметричный (inorder) и обратный (postorder). Прямой обход посещает узел перед потомками и используется для копирования структуры. Симметричный обход возвращает элементы в отсортированном порядке в деревьях поиска. Обратный обход посещает узлы после потомков и применяется при удалении узлов или вычислении выражений в абстрактных синтаксических деревьях.
Какие ошибки чаще всего встречаются при работе с деревьями?
Распространённые ошибки включают неправильное связывание узлов, удаление корня без перераспределения поддеревьев, переполнение стека при рекурсивном обходе, нарушение баланса в деревьях поиска и дублирование ссылок на один и тот же узел. Для предотвращения проблем используют алгоритмы самобалансировки, проверяют корректность вставки узлов и при глубокой рекурсии применяют итеративные обходы с явным стеком.