Содержание статьи

Бинарный поиск – это алгоритм, который позволяет находить нужный элемент в отсортированном массиве за логарифмическое время. Вместо последовательного перебора всех значений он делит диапазон поиска пополам, исключая ненужные элементы на каждом шаге. Такой подход делает его одним из базовых инструментов при работе с большими объемами данных.
Принцип бинарного поиска основан на сравнении искомого значения с средним элементом массива. Если значение меньше, поиск продолжается в левой части, если больше – в правой. Этот процесс повторяется, пока не будет найден нужный элемент или диапазон не сузится до нуля.
Бинарный поиск используется в задачах, связанных с поиском в отсортированных списках, индексах баз данных, словарях и числовых диапазонах. Алгоритм легко реализуется на любом языке программирования и может быть представлен как в итеративной, так и в рекурсивной форме. Его знание важно при решении задач на оптимизацию поиска и анализ временной сложности алгоритмов.
Бинарный поиск в программировании: простое объяснение
Бинарный поиск применяется для нахождения элемента в уже отсортированном массиве. Алгоритм начинает с определения среднего индекса и сравнения его значения с искомым. В зависимости от результата сравнения исключается либо левая, либо правая половина массива. Повторение процедуры на оставшейся части данных продолжается до нахождения элемента или завершения поиска.
Главное условие корректной работы – массив должен быть упорядочен по возрастанию или убыванию. При несортированных данных результат будет некорректным. Поэтому перед применением бинарного поиска рекомендуется использовать стандартные методы сортировки, такие как быстрая сортировка или сортировка слиянием.
Преимущество бинарного поиска заключается в снижении количества сравнений: при каждом шаге объем рассматриваемых данных уменьшается вдвое. Для массива из тысячи элементов потребуется не более десяти итераций. Это делает алгоритм удобным для поиска в больших наборах данных, например при обработке логов, работе с индексами или анализе числовых диапазонов.
Реализация алгоритма может быть итеративной или рекурсивной. Итеративный вариант проще для понимания и экономнее по памяти, так как не создает дополнительных стековых вызовов. Рекурсивный подход более нагляден, но требует аккуратного контроля условий выхода, чтобы избежать лишних вычислений.
Как работает бинарный поиск на упорядоченном массиве
Бинарный поиск использует упорядоченность массива для последовательного сокращения диапазона поиска. Алгоритм начинает с определения индекса среднего элемента и сравнения его значения с целевым. Если совпадение отсутствует, анализируется направление поиска: если искомое значение меньше среднего, рассматривается левая часть массива, если больше – правая.
На каждом шаге диапазон поиска сокращается вдвое. Это позволяет находить элемент в массиве длиной n примерно за log₂(n) сравнений. Например, при длине массива 1024 элементов потребуется не более 10 проверок. Такая зависимость делает алгоритм удобным при обработке больших объемов данных, где линейный поиск становится слишком затратным.
Для корректной работы алгоритма массив должен быть строго отсортирован. В противном случае направление поиска будет определяться неверно, что приведет к пропуску нужного элемента. Проверку упорядоченности данных можно выполнить заранее или гарантировать её при формировании массива.
Бинарный поиск подходит не только для чисел, но и для строк, если используется сравнение по лексикографическому порядку. При этом важно учитывать чувствительность к регистру и одинаковый способ сортировки при поиске и при подготовке данных.
Пошаговый разбор алгоритма бинарного поиска

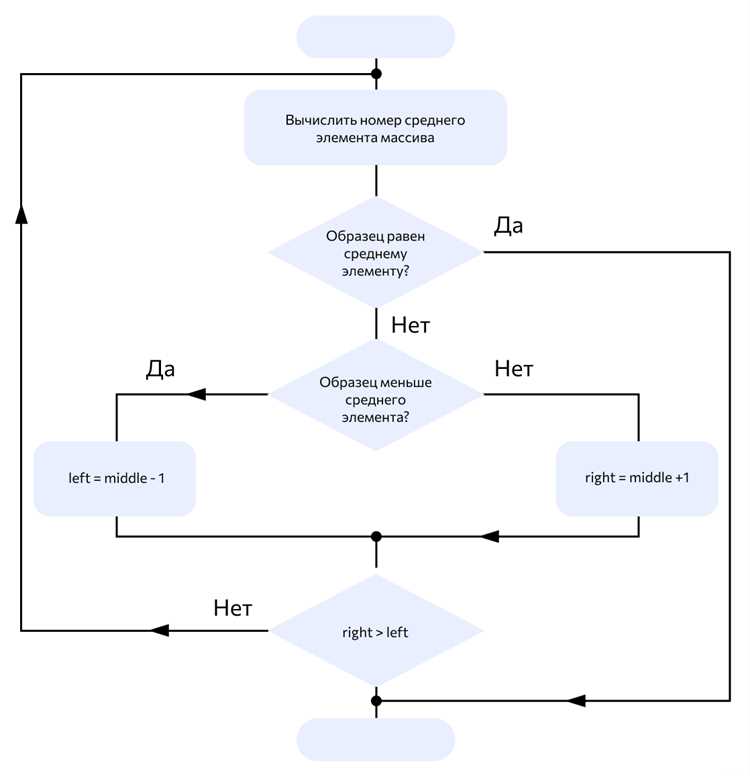
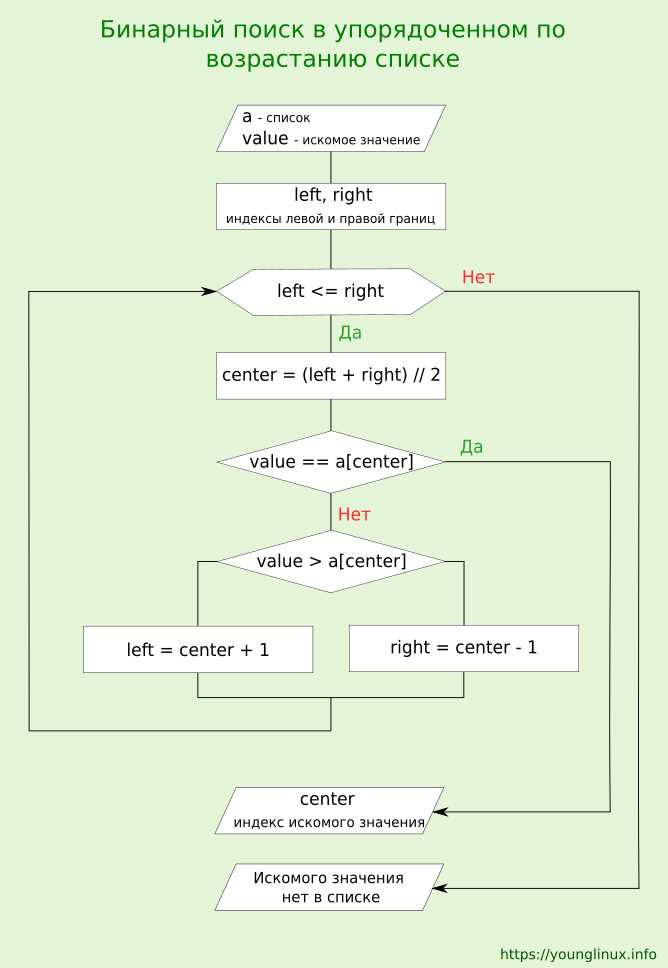
Алгоритм бинарного поиска начинается с определения двух индексов – левого и правого границ массива. Левый индекс указывает на начало, правый – на конец диапазона. Пока левый индекс не превышает правый, выполняются повторные проверки среднего элемента.
На каждом шаге вычисляется средний индекс: mid = (left + right) // 2. Значение элемента с этим индексом сравнивается с искомым. Если совпадение найдено, возвращается индекс. Если значение в середине больше целевого, граница right сдвигается влево: right = mid — 1. Если меньше – сдвигается left: left = mid + 1.
Процесс повторяется, пока границы не пересекутся. Если элемент отсутствует, алгоритм завершает выполнение, возвращая индикатор, например -1 или сообщение об отсутствии значения. Такая структура цикла гарантирует, что каждый элемент проверяется не более одного раза.
Для оптимизации вычислений важно избегать переполнения при вычислении среднего индекса. Безопаснее использовать выражение mid = left + (right — left) // 2. Это особенно актуально при работе с большими массивами, где сумма left + right может превышать допустимое значение целого типа.
Пример реализации бинарного поиска на языке Python
Бинарный поиск в Python можно реализовать с помощью цикла while. Пример ниже показывает итеративный вариант с возвращением индекса найденного элемента или значения -1, если элемент отсутствует.
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = left + (right - left) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid - 1
return -1
Порядок выполнения:
- Задать начальные границы диапазона left и right.
- Вычислить индекс середины с помощью mid = left + (right - left) // 2.
- Сравнить элемент по индексу mid с целевым значением.
- При совпадении вернуть индекс, при несовпадении сузить диапазон поиска.
- При пересечении границ вернуть -1, что означает отсутствие элемента.
Для проверки корректности работы функции можно использовать простой пример:
data = [1, 3, 5, 7, 9, 11]
result = binary_search(data, 7)
Перед использованием алгоритма необходимо убедиться, что массив отсортирован. Если порядок не гарантирован, следует применить встроенную функцию sorted() перед вызовом поиска. Такой подход предотвращает логические ошибки и обеспечивает корректный результат.
Типичные ошибки при реализации бинарного поиска
Бинарный поиск кажется простым, но при реализации часто возникают ошибки, влияющие на результат или производительность. Наиболее распространенная проблема – неверное вычисление среднего индекса. Использование выражения (left + right) // 2 может привести к переполнению при работе с большими индексами. Безопаснее использовать left + (right - left) // 2.
Вторая ошибка – неправильное обновление границ диапазона. Если после сравнения значение меньше среднего, необходимо сдвинуть правую границу: right = mid - 1. При обратном условии – левую: left = mid + 1. Пропуск этих шагов или некорректное изменение границ вызывает зацикливание.
Часто встречается путаница с условием выхода из цикла. Проверка должна выполняться до тех пор, пока left ≤ right. Использование < вместо ≤ может привести к пропуску элементов и неверному результату.
Ошибки возникают и при работе с неотсортированными массивами. Алгоритм предполагает строгую упорядоченность, поэтому перед поиском нужно убедиться в корректном порядке данных. Если сортировка не выполнена, бинарный поиск возвращает случайные значения.
При реализации рекурсивного варианта важно контролировать базовые условия выхода. Отсутствие проверки на пересечение границ приводит к бесконечной рекурсии и переполнению стека. Для предотвращения этого следует завершать вызовы при условии left > right.
Рекурсивная и итеративная формы бинарного поиска
Бинарный поиск можно реализовать двумя способами: итеративно и рекурсивно. Итеративный вариант использует цикл while для последовательного сужения диапазона поиска. Он не создает дополнительных вызовов функции, что экономит память и снижает нагрузку на стек.
Рекурсивная форма вызывает функцию внутри самой себя, передавая обновленные границы left и right. Каждый рекурсивный вызов обрабатывает меньший диапазон, пока не будет найден элемент или диапазон не пересечется. Базовое условие выхода обязательно: left > right, иначе возникает переполнение стека.
Итеративный вариант предпочтителен при работе с большими массивами, так как исключает риск переполнения стека. Рекурсивный удобен для наглядного понимания процесса и часто используется в учебных примерах. Для рекурсивной реализации рекомендуется использовать безопасное вычисление среднего индекса: mid = left + (right - left) // 2.
В обоих подходах важно поддерживать строгую упорядоченность массива. Любое нарушение порядка элементов приводит к неправильным результатам независимо от выбранного метода реализации.
Анализ времени выполнения и количества сравнений
Бинарный поиск сокращает диапазон поиска вдвое на каждом шаге, что напрямую влияет на время выполнения. Для массива из n элементов алгоритм выполняет не более log₂(n) сравнений.
Пример зависимости количества сравнений:
- Массив из 16 элементов: максимум 4 сравнения.
- Массив из 1 024 элементов: максимум 10 сравнений.
- Массив из 1 048 576 элементов: максимум 20 сравнений.
В отличие от линейного поиска, где количество проверок равно размеру массива в худшем случае, бинарный поиск снижает нагрузку пропорционально логарифму от объема данных. Это особенно заметно при работе с большими наборами чисел или строк.
Для оценки производительности следует учитывать следующие факторы:
- Размер массива – прямой показатель числа необходимых шагов.
- Сложность вычисления среднего индекса – при больших числах использовать mid = left + (right - left) // 2 для предотвращения переполнения.
- Форма реализации – итеративная экономит память, рекурсивная добавляет нагрузку на стек, но визуально проще для анализа.
Практическая рекомендация: бинарный поиск выгодно применять только к отсортированным массивам. Для несортированных данных сначала выполнить сортировку, чтобы сохранить предсказуемое количество сравнений и корректность результата.
Применение бинарного поиска в реальных задачах

Бинарный поиск широко используется при работе с отсортированными массивами, индексами баз данных и словарями. Он позволяет быстро находить конкретные значения без перебора всех элементов. Например, при поиске имени пользователя в списке из нескольких тысяч записей достаточно нескольких сравнений.
В программировании числовых диапазонов бинарный поиск помогает определять границы интервалов. Пример: поиск минимального значения, удовлетворяющего условию в отсортированном массиве, или нахождение точки вставки нового элемента без нарушения порядка.
Алгоритм используется в системах управления версиями и конфигурациями для поиска изменений в упорядоченных списках коммитов. Также он применяется в обработке логов, где события сортируются по времени, и нужно быстро выявить событие с конкретным timestamp.
В задачах оптимизации, например, при подборе пороговых значений или минимизации функций, бинарный поиск позволяет сокращать количество проверок. Рекомендуется применять алгоритм там, где данные можно отсортировать заранее и требуется частый быстрый доступ к элементам.
Сравнение бинарного поиска с линейным методом

Бинарный поиск и линейный поиск отличаются подходом к обработке данных и количеством сравнений. Линейный перебирает элементы последовательно, бинарный делит диапазон пополам на каждом шаге. Для небольших массивов разница в скорости несущественна, но при росте объема данных бинарный поиск значительно выигрывает.
| Характеристика | Линейный поиск | Бинарный поиск |
|---|---|---|
| Необходимость сортировки | Не требуется | Обязательна |
| Количество сравнений | До n | До log₂(n) |
| Сложность реализации | Простая | Требует контроля границ и вычисления среднего индекса |
| Использование памяти | Минимальное | Итеративно – минимальное, рекурсивно – зависит от глубины стека |
| Применение | Малые и неотсортированные массивы | Большие отсортированные массивы, частые поисковые операции |
Для оптимизации производительности рекомендуется использовать бинарный поиск на отсортированных данных. Линейный метод подходит для небольших списков или когда сортировка невозможна или экономически нецелесообразна.
Вопрос-ответ:
Что такое бинарный поиск и где он используется?
Бинарный поиск — это алгоритм поиска элемента в отсортированном массиве путем последовательного деления диапазона пополам. Он используется при работе с базами данных, отсортированными списками, индексами и словарями, где требуется быстро находить значения без перебора всех элементов.
В чем разница между итеративной и рекурсивной реализацией бинарного поиска?
Итеративная реализация использует цикл, постепенно сужая диапазон поиска, и не создает дополнительных вызовов функций, что экономит память. Рекурсивная форма вызывает функцию внутри самой себя с обновленными границами, что делает код более наглядным, но при больших массивах может привести к переполнению стека.
Какие ошибки чаще всего возникают при реализации бинарного поиска?
Частые ошибки: неверное вычисление среднего индекса, что может вызвать переполнение; неправильное обновление границ left и right; отсутствие проверки условия выхода из цикла или рекурсии; использование несортированного массива, что приводит к некорректным результатам.
Какой размер массива делает бинарный поиск предпочтительным по сравнению с линейным поиском?
Для массивов, содержащих несколько сотен и больше элементов, бинарный поиск выполняется значительно быстрее, чем линейный, так как количество сравнений растет логарифмически. При небольших списках разница несущественна, и линейный поиск может быть проще в реализации.