Содержание статьи

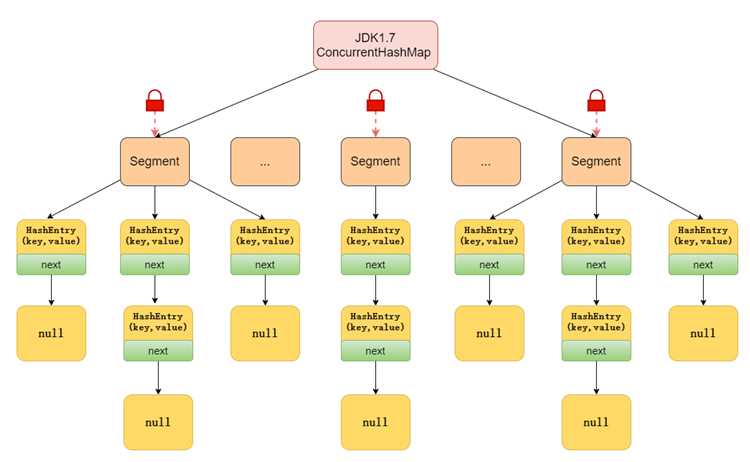
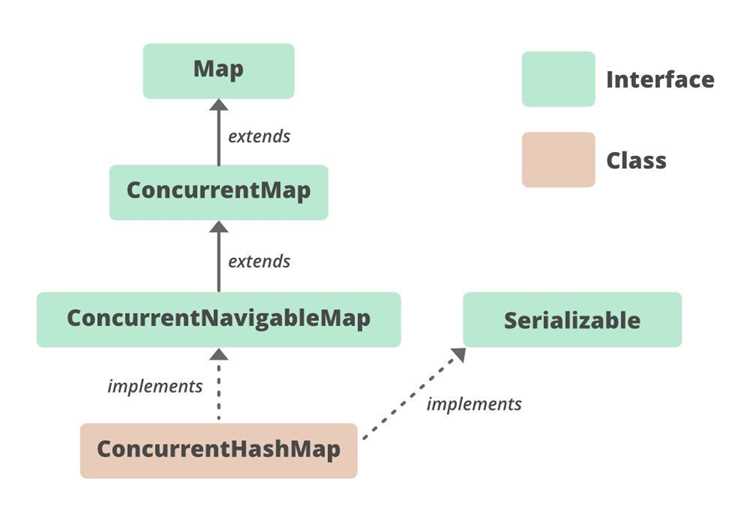
ConcurrentHashMap представляет собой реализацию интерфейса ConcurrentMap, которая позволяет безопасно работать с хеш-таблицей в многопоточной среде без полной блокировки. Основной принцип работы основан на разделении таблицы на сегменты и применении атомарных операций для минимизации конфликтов между потоками.
Каждый сегмент хранит определённую часть элементов и управляет блокировкой независимо от других сегментов. Это позволяет одновременно выполнять чтение и запись в разные сегменты без взаимного блокирования. Для операций обновления значений применяются CAS (Compare-And-Swap), что снижает количество блокировок и повышает скорость работы при высокой конкуренции потоков.
Структура таблицы предусматривает динамическое перераспределение элементов при коллизиях и увеличении объёма данных. ConcurrentHashMap использует цепочки или деревья в качестве внутреннего механизма разрешения коллизий, что позволяет сохранять быстрый доступ к элементам даже при высокой плотности ключей.
Методы put, get и remove в ConcurrentHashMap обеспечивают атомарность на уровне отдельных ключей. Это гарантирует корректность работы с данными без необходимости внешней синхронизации, что делает коллекцию подходящей для многопоточных приложений с интенсивной записью и чтением.
ConcurrentHashMap в Java: как устроена работа структуры
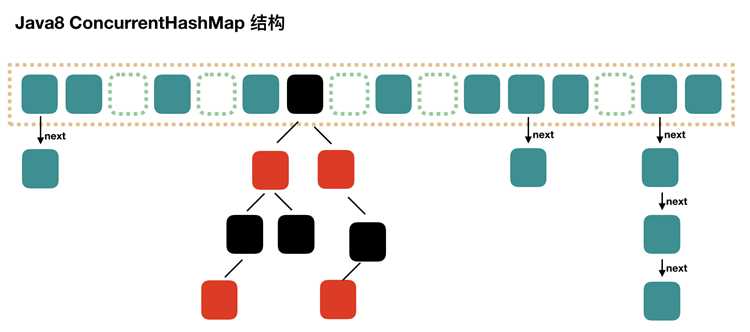
ConcurrentHashMap строится на основе сегментированной хеш-таблицы, где каждый сегмент представляет собой массив бакетов с отдельными блокировками. Сегменты позволяют одновременно выполнять операции чтения и записи в разных частях таблицы, что снижает конкуренцию потоков.
Для добавления или обновления элементов используется комбинация CAS (Compare-And-Swap) и локальных блокировок на уровне сегмента. При коллизиях ключей элементы хранятся в виде связанных списков или преобразуются в сбалансированные деревья, если количество коллизий превышает порог, установленный в 8 элементов.
Метод get не блокирует сегменты и считывает значения напрямую, используя атомарные операции для предотвращения чтения некорректных данных во время обновления. Метод put сначала вычисляет хеш ключа, затем определяет сегмент и применяет CAS или блокировку сегмента для вставки или замены значения.
При увеличении количества элементов таблица расширяется лениво, сегмент за сегментом, чтобы избежать глобальной блокировки. Расширение выполняется с сохранением ссылок на старые бакеты, что обеспечивает непрерывный доступ к данным во время перераспределения.
ConcurrentHashMap отличается от Hashtable и synchronizedMap тем, что не блокирует всю коллекцию, а ограничивает синхронизацию узкими участками данных. Это делает её подходящей для приложений с высокой частотой параллельных операций и минимальными задержками на чтение и запись.
Разделение на сегменты и роль сегментной блокировки
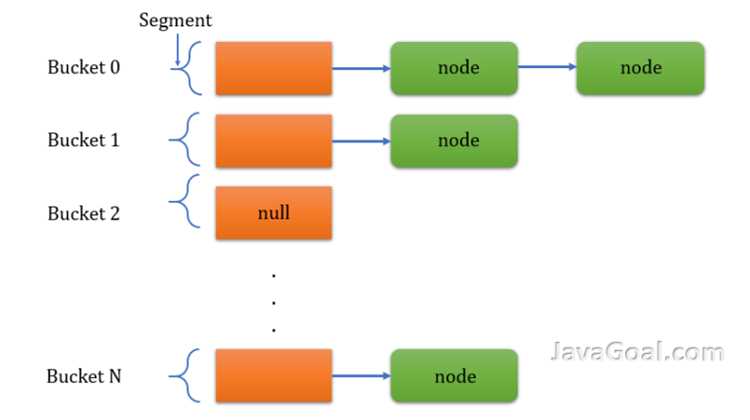
ConcurrentHashMap делит хеш-таблицу на сегменты, каждый из которых управляет своей частью элементов. Сегмент содержит массив бакетов и отдельную блокировку, которая применяется только при изменении данных внутри этого сегмента. Такое разделение уменьшает конкуренцию между потоками при параллельной записи.
Каждый ключ распределяется по сегментам с помощью вычисления хеша и маски сегмента. Операции чтения get выполняются без блокировок, так как значения внутри бакетов обновляются атомарно. Для записи и удаления элементов используются локальные блокировки сегмента или CAS, что позволяет одновременно модифицировать разные сегменты.
Сегментная блокировка предотвращает необходимость синхронизации всей карты и снижает вероятность блокировок при высокой нагрузке. Рекомендуется учитывать количество сегментов при создании ConcurrentHashMap: слишком мало сегментов увеличивает конкуренцию потоков, слишком много – повышает накладные расходы на управление структурой.
Механизм атомарных операций при обновлении значений
ConcurrentHashMap использует атомарные операции для обновления значений без полной блокировки таблицы. Основной механизм основан на CAS (Compare-And-Swap), который проверяет текущее значение и заменяет его новым, если оно не изменилось с момента чтения. Это обеспечивает корректность данных при параллельной записи.
Для сложных операций, таких как обновление существующего значения или вставка нового ключа, ConcurrentHashMap применяет комбинацию локальных блокировок сегмента и CAS. При этом чтение остаётся неблокирующим, а модификации затрагивают только соответствующий сегмент.
Пример типичного обновления значения можно представить в виде таблицы:
| Операция | Механизм | Результат |
|---|---|---|
| get(key) | Прямой доступ без блокировки | Возвращает текущее значение или null |
| put(key, value) | CAS для вставки нового элемента, блокировка сегмента при коллизии | Значение добавляется или обновляется атомарно |
| replace(key, oldValue, newValue) | CAS проверяет oldValue и заменяет его на newValue | Обновление выполняется только если старое значение совпадает |
| remove(key) | Блокировка сегмента или CAS для безопасного удаления | Элемент удаляется без влияния на другие сегменты |
Использование атомарных операций снижает вероятность блокировок и повышает пропускную способность коллекции при высокой параллельной нагрузке.
Стратегия управления хеш-таблицей при коллизиях
ConcurrentHashMap использует комбинированный подход для разрешения коллизий ключей. Первоначально элементы с одинаковым хешем объединяются в связанные списки внутри бакета. Если количество элементов в бакете превышает порог 8, структура автоматически преобразуется в сбалансированное дерево типа Red-Black Tree, что снижает время поиска с O(n) до O(log n).
Эта стратегия обеспечивает быстрый доступ к элементам при высокой плотности ключей. При удалении или добавлении элементов структура динамически адаптируется, возвращаясь к списку, если количество элементов в дереве уменьшается ниже порога.
Пример поведения хеш-таблицы при коллизиях представлен в таблице:
| Количество элементов в бакете | Используемая структура | Время поиска |
|---|---|---|
| 1–7 | Связанный список | O(n) для бакета |
| 8 и более | Red-Black Tree | O(log n) для бакета |
| После удаления элементов, если меньше 6 | Возврат к связанному списку | O(n) для бакета |
Рекомендуется учитывать распределение ключей и избегать длинных последовательностей одинаковых хешей, чтобы минимизировать преобразование списка в дерево и поддерживать высокую скорость операций.
Особенности работы итераторов в многопоточной среде
Итераторы в ConcurrentHashMap реализованы как weakly consistent, что позволяет безопасно обходить элементы коллекции при параллельных изменениях. Они не выбрасывают ConcurrentModificationException и отображают большинство элементов на момент создания итератора, хотя новые или удалённые элементы могут не быть видны.
Особенности работы итераторов включают:
- Чтение элементов происходит без блокировки сегментов, что минимизирует влияние на другие потоки.
- Итератор не гарантирует фиксированное состояние карты: элементы могут добавляться или удаляться во время обхода.
- Методы forEach, forEachRemaining и spliterator используют ту же слабую согласованность, обеспечивая параллельную обработку элементов.
- При обходе рекомендуется избегать зависимостей между итератором и внешними изменениями карты, чтобы не получать устаревшие данные.
Рекомендации по использованию:
- Использовать итераторы для операций чтения и вычислений, не требующих полной актуальности данных.
- Для атомарных модификаций внутри обхода применять методы compute или replace вместо прямого изменения элементов через итератор.
- При необходимости последовательного снимка состояния карты лучше создавать копию через new HashMap<>(concurrentMap).
Принцип ленивого расширения таблицы и перераспределения элементов

ConcurrentHashMap применяет ленивое расширение таблицы для минимизации блокировок при увеличении числа элементов. Расширение выполняется сегмент за сегментом, что позволяет другим потокам продолжать работу с неперераспределёнными сегментами.
Основные моменты работы механизма:
- Каждый сегмент хранит свой массив бакетов, который расширяется независимо от других сегментов.
- Расширение инициируется, когда количество элементов в сегменте превышает порог загрузки (load factor), обычно 0.75.
- Перераспределение элементов происходит по новому размеру массива, при этом CAS обеспечивает атомарность вставки элементов в новые бакеты.
- Чтение во время расширения остаётся неблокирующим, элементы из старого массива доступны до завершения перераспределения.
Рекомендации по настройке:
- При создании ConcurrentHashMap указывать начальный размер и количество сегментов с учётом ожидаемой нагрузки, чтобы минимизировать частые расширения.
- Следить за равномерностью распределения хешей ключей, чтобы предотвратить чрезмерное расширение отдельных сегментов.
- Использовать методы compute и putIfAbsent для добавления элементов, чтобы корректно обрабатывать перераспределение в многопоточной среде.
Использование CAS для синхронизации без блокировок
ConcurrentHashMap активно использует CAS (Compare-And-Swap) для обновления значений без необходимости блокировки всей таблицы или сегмента. CAS проверяет текущее значение ключа и заменяет его новым только в случае совпадения с ожидаемым. Если значение изменилось другим потоком, операция повторяется.
Основные особенности применения CAS:
- Обновления выполняются атомарно на уровне отдельного элемента, что снижает конкуренцию между потоками.
- Чтение значений не блокируется и всегда возвращает корректное состояние, даже во время параллельных модификаций.
- Сложные операции, такие как replace или compute, используют CAS в цикле до успешного завершения, обеспечивая согласованность данных.
- CAS минимизирует вероятность взаимных блокировок и повышает пропускную способность коллекции при высокой нагрузке.
Рекомендации по использованию:
- Для операций с высокой конкуренцией потоков отдавать предпочтение методам, реализующим CAS, вместо внешней синхронизации.
- Избегать длительных вычислений внутри CAS-цикла, чтобы снизить количество повторов из-за конфликтов.
- Использовать CAS совместно с локальными блокировками сегментов только при необходимости вставки новых элементов в бакет с коллизиями.
Поведение методов put, get и remove в конкурентной среде
Метод get в ConcurrentHashMap выполняется без блокировок. Он использует атомарное чтение ссылок на элементы и возвращает актуальное значение на момент вызова, даже если другие потоки одновременно изменяют карту.
Метод put сочетает CAS и локальные блокировки сегмента. Если ключ отсутствует, вставка выполняется через CAS. При коллизиях или необходимости вставки в бакет с существующими элементами сегмент блокируется локально, чтобы сохранить согласованность данных.
Метод remove также использует сегментные блокировки или CAS для удаления элемента. Удаление происходит атомарно для конкретного ключа и не блокирует другие сегменты, что позволяет продолжать параллельные операции в разных частях карты.
Рекомендации при использовании методов:
- Для чтения больших объёмов данных использовать get, чтобы избежать лишних блокировок.
- При одновременной вставке большого числа элементов распределять ключи равномерно, чтобы уменьшить конкуренцию сегментов.
- Для условного обновления значений применять методы replace или compute, обеспечивая атомарность без глобальных блокировок.
Отличия ConcurrentHashMap от Hashtable и synchronizedMap
ConcurrentHashMap отличается от Hashtable и synchronizedMap структурой синхронизации. В Hashtable каждая операция блокирует всю карту, что ограничивает параллельную работу потоков. SynchronizedMap использует внешнюю синхронизацию через методы Collections.synchronizedMap, блокируя доступ ко всей карте при любой модификации.
ConcurrentHashMap применяет сегментную блокировку и CAS для обновления отдельных элементов, что позволяет параллельно читать и изменять разные сегменты. Чтение выполняется без блокировок, а запись затрагивает только соответствующий сегмент.
Сравнительная таблица ключевых отличий:
| Особенность | ConcurrentHashMap | Hashtable | SynchronizedMap |
|---|---|---|---|
| Синхронизация | Сегментная + CAS | Глобальная блокировка | Глобальная блокировка через synchronized |
| Чтение | Неблокирующее | Блокирующее | Блокирующее |
| Производительность при высокой конкуренции | Высокая | Низкая | Низкая |
| Итераторы | Weakly consistent | Fail-fast | Fail-fast |
Рекомендации:
- Использовать ConcurrentHashMap при высокой частоте параллельных операций записи и чтения.
- Для простых однопоточных случаев или редкой синхронизации достаточно Hashtable или SynchronizedMap.
- При проектировании многопоточных приложений учитывать распределение ключей для равномерной нагрузки сегментов в ConcurrentHashMap.
Вопрос-ответ:
Чем ConcurrentHashMap отличается от обычного HashMap в многопоточной среде?
ConcurrentHashMap использует сегментную блокировку и атомарные операции CAS для вставки и обновления элементов, что позволяет нескольким потокам одновременно выполнять чтение и запись без глобальной блокировки. HashMap в многопоточной среде не гарантирует корректность данных и может привести к некорректной работе или бесконечным циклам при параллельных изменениях.
Как ConcurrentHashMap обрабатывает коллизии ключей?
При коллизиях ключей элементы в бакете сначала хранятся в виде связанных списков. Если количество элементов превышает порог 8, список преобразуется в сбалансированное дерево Red-Black Tree, что уменьшает время поиска с O(n) до O(log n). При уменьшении числа элементов дерево возвращается в список. Это позволяет поддерживать быстрый доступ к данным даже при высокой плотности ключей.
Можно ли безопасно использовать итератор ConcurrentHashMap при одновременной модификации карты другими потоками?
Итераторы ConcurrentHashMap являются weakly consistent, они не блокируют карту и не выбрасывают ConcurrentModificationException. Итератор видит большинство элементов на момент создания, но новые добавленные или удалённые элементы могут быть не видны. Для атомарных обновлений во время обхода рекомендуется использовать методы compute или replace.
Как работает метод put в ConcurrentHashMap при параллельной записи нескольких потоков?
Метод put сначала вычисляет хеш ключа и определяет сегмент. Если ключ отсутствует, вставка выполняется через CAS. При коллизиях или необходимости вставки в бакет с существующими элементами сегмент блокируется локально. Это обеспечивает атомарность операции на уровне сегмента без блокировки всей карты.
Что следует учитывать при выборе размера сегментов при создании ConcurrentHashMap?
Количество сегментов влияет на конкуренцию потоков. Слишком мало сегментов увеличивает вероятность блокировок при параллельной записи, слишком много повышает накладные расходы на управление структурой. Рекомендуется выбирать число сегментов с учётом предполагаемой нагрузки и равномерного распределения ключей, чтобы минимизировать блокировки и поддерживать стабильную производительность.