Содержание статьи

Вещественные числа применяются в программировании для хранения и обработки дробных значений, однако их поведение далеко от интуитивного представления о математических числах. В большинстве языков программирования они реализуются на основе стандарта IEEE 754, который описывает хранение числа в виде знака, мантиссы и порядка. Такая модель позволяет представлять очень широкий диапазон значений, но вводит ограничения на точность, из-за которых часть десятичных дробей не может быть сохранена без искажения.
Практическая проблема проявляется уже на базовых операциях: сложение, вычитание и сравнение могут давать неожиданные результаты. Например, выражения с финансовыми расчётами, координатами или измерениями часто накапливают погрешность, которая становится заметной после серии операций. Игнорирование этих особенностей приводит к логическим ошибкам, которые сложно отследить тестированием, особенно при работе с большими объёмами данных или длительными вычислениями.
Разработчику важно понимать, как выбор типа float, double или их аналогов влияет на точность и диапазон значений. Для задач, где критично точное представление десятичных дробей, рекомендуется рассматривать альтернативы – например, фиксированную точку или специализированные типы для десятичной арифметики. Осознанное использование вещественных чисел снижает риск скрытых ошибок и упрощает сопровождение кода в долгосрочной перспективе.
Как представляются вещественные числа в памяти компьютера (IEEE 754)
Вещественные числа в большинстве языков программирования хранятся по стандарту IEEE 754, который строго определяет двоичную структуру значения. Число кодируется не как последовательность десятичных разрядов, а как комбинация битов, интерпретируемых по фиксированным правилам. Это позволяет унифицировать поведение вычислений на разных архитектурах, но накладывает ограничения на точность представления.
Каждое вещественное число состоит из трёх логических компонентов:
- знак – один бит, определяющий положительное или отрицательное значение;
- порядок (экспонента) – группа битов, задающая степень двойки;
- мантисса – дробная часть числа, хранящая значимые биты.
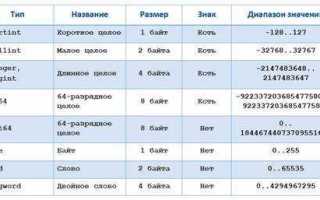
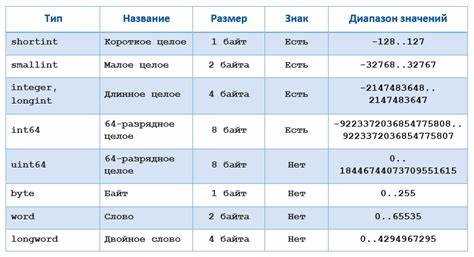
На практике чаще всего используются два формата:
- одинарная точность (32 бита) – 1 бит знака, 8 бит порядка, 23 бита мантиссы;
- двойная точность (64 бита) – 1 бит знака, 11 бит порядка, 52 бита мантиссы.
Мантисса хранится в нормализованном виде: ведущая единица не записывается явно, а считается присутствующей по умолчанию. Это увеличивает количество значимых разрядов без расширения размера типа. Порядок хранится со смещением (bias), что позволяет кодировать как положительные, так и отрицательные степени двойки.
Стандарт предусматривает специальные значения, которые не соответствуют обычным числам:
- +Infinity и -Infinity – результат переполнения;
- NaN – значение, полученное при недопустимых операциях;
- денормализованные числа – используются для представления значений, близких к нулю.
Из-за двоичной природы формата многие десятичные дроби (например, 0.1) не имеют точного представления в памяти. Они сохраняются в виде ближайшего доступного двоичного значения, что закладывает погрешность уже на этапе инициализации. При проектировании алгоритмов рекомендуется учитывать это поведение и избегать предположений о точности хранения десятичных дробей.
Почему возникают ошибки округления при вычислениях с вещественными числами
Каждая арифметическая операция с вещественными числами выполняется с ограниченным числом значимых битов. Результат операции снова округляется до формата типа данных, что приводит к накоплению погрешности. Особенно заметно это при:
- многократном сложении или вычитании малых значений;
- чередовании операций с числами сильно различающегося порядка;
- выполнении итеративных алгоритмов и численных методов.
Процессор применяет определённое правило округления, чаще всего «к ближайшему с учётом чётности». Такое поведение снижает систематическое смещение, но не устраняет расхождения с математическим результатом. Разница может проявляться в сравнении значений, ветвлении логики или проверках граничных условий.
Дополнительным источником ошибок становится порядок вычислений. Из-за того, что сложение и умножение вещественных чисел не обладают строгой ассоциативностью, выражения с одинаковыми операндами могут давать разные результаты при изменении последовательности операций. Это важно учитывать при оптимизации кода и параллельных вычислениях.
Практические рекомендации для снижения влияния ошибок округления:
- избегать прямого сравнения вещественных чисел на равенство;
- нормализовать данные перед сериями вычислений;
- группировать операции так, чтобы сначала обрабатывались значения близкого масштаба;
- для критичных расчётов применять альтернативные числовые представления.
Понимание природы округления позволяет заранее проектировать алгоритмы с учётом допустимой погрешности и предотвращать ошибки, проявляющиеся только на реальных данных.
Чем опасно прямое сравнение вещественных чисел на равенство
Прямое сравнение вещественных чисел на равенство опирается на побитовое совпадение их представления в памяти. Даже если два значения получены из одинаковых формул, промежуточные округления могут привести к различию в последних битах мантиссы. В результате логическое выражение возвращает ложь, несмотря на математическую эквивалентность чисел.
Опасность особенно заметна в условиях, где результат вычислений влияет на управление программой. Проверки завершения циклов, условия выхода из итераций или валидация пользовательского ввода могут срабатывать некорректно. Такие ошибки редко воспроизводятся на простых тестах, так как зависят от порядка операций и конкретных значений данных.
Дополнительный риск связан с тем, что одинаковые выражения, вычисленные в разных частях программы или на разных платформах, могут дать слегка отличающиеся результаты. Оптимизации компилятора, использование регистров повышенной точности и параллельные вычисления усиливают вероятность расхождений при сравнении.
Вместо проверки на точное равенство рекомендуется сравнивать разницу между числами с заранее заданным допуском. Такой подход учитывает допустимую погрешность представления и позволяет формулировать условия, устойчивые к округлению. Значение допуска должно выбираться с учётом масштаба данных и характера вычислений, а не быть фиксированной константой.
Прямое сравнение вещественных чисел допустимо только в редких случаях, когда значения получены из одного источника без арифметических преобразований. Во всех остальных ситуациях отказ от строгого равенства снижает риск скрытых логических ошибок и делает поведение программы предсказуемым.
Как диапазон значений влияет на переполнение и потерю точности
Диапазон вещественного типа определяет, какие минимальные и максимальные значения могут быть сохранены в памяти. Он напрямую зависит от количества бит, выделенных под порядок. При выходе результата за допустимые границы происходит переполнение, и значение заменяется на Infinity с соответствующим знаком. Такое состояние не вызывает немедленного сбоя программы, но может незаметно исказить дальнейшие вычисления.
Проблемы возникают не только при экстремально больших числах. Потеря точности проявляется, когда в одном выражении участвуют значения с сильно различающимся порядком. Малое число может быть полностью отброшено при сложении с большим, так как мантисса не вмещает все значимые биты. Формально операция выполняется корректно, но результат не отражает ожидаемое влияние меньшего слагаемого.
Особое внимание требуется при работе с величинами, близкими к нулю. Для них стандарт использует денормализованные числа, где снижается точность мантиссы ради сохранения диапазона. Это позволяет избежать резкого обнуления, но увеличивает относительную погрешность и может повлиять на устойчивость алгоритмов.
Переполнение и потеря точности часто проявляются в накопительных расчётах, статистике и моделировании. При проектировании таких систем рекомендуется:
выбирать тип данных с запасом по диапазону, особенно для промежуточных результатов;
масштабировать данные, приводя значения к сопоставимым порядкам перед операциями;
контролировать появление бесконечностей и аномальных значений в ключевых точках алгоритма.
Понимание влияния диапазона позволяет заранее оценивать риски и принимать архитектурные решения, которые предотвращают скрытую деградацию точности при росте объёма данных или изменении входных параметров.
Как задаются и интерпретируются вещественные литералы в языках программирования
Синтаксис литералов зависит от языка, но ключевые элементы совпадают: десятичная точка, необязательная дробная часть и экспоненциальная форма записи. Экспонента задаёт степень десяти или двойки и позволяет компактно описывать очень большие и очень малые значения. Ошибки часто возникают из-за неверного понимания того, как эта запись влияет на итоговый тип и точность.
| Форма записи | Интерпретация |
|---|---|
| 3.14 | Вещественное число стандартной точности по умолчанию |
| 2.0e3 | Число в экспоненциальной форме (2000) |
| 1. | Вещественный литерал без дробной части |
| .5 | Дробное значение без целой части |
Во многих языках тип вещественного литерала определяется контекстом или суффиксами. Без явного указания он может интерпретироваться как число двойной точности, даже если переменной требуется меньший формат. Неявное приведение типа при этом может привести к дополнительному округлению или изменению поведения выражений.
Отдельного внимания требует использование целочисленных литералов в выражениях с вещественными типами. Если все операнды заданы как целые, промежуточный результат может быть вычислен в целочисленной арифметике, а преобразование к вещественному типу произойдёт только в конце. Это часто становится источником логических ошибок.
Рекомендации при работе с вещественными литералами:
явно задавать формат и тип, если от него зависит точность вычислений;
использовать экспоненциальную форму для чисел с большим диапазоном значений;
избегать предположений о точности десятичных дробей, записанных в коде.
Осознанная работа с литералами снижает количество неочевидных ошибок, которые закладываются в программу ещё до выполнения первой арифметической операции.
Что происходит при преобразовании вещественных чисел в целые типы
Если вещественное число выходит за пределы диапазона целевого типа, возникает переполнение. В языках с строгой типизацией это может приводить к выбросу исключения, в языках с низкоуровневым управлением памятью результат чаще всего искажается, что выражается в непредсказуемых значениях.
Особую осторожность следует проявлять при комбинировании вещественных и целых типов в выражениях. Например, присваивание вещественного литерала переменной целого типа выполняет скрытое преобразование, которое может обнулить малые значения или отбросить значимые дробные разряды, влияя на точность вычислений.
Рекомендации при преобразовании вещественных чисел в целые:
- явно использовать функции округления или преобразования (floor, ceil, round) вместо неявного приведения типов;
- контролировать диапазон значений, чтобы избежать переполнения;
- особое внимание уделять отрицательным числам, где усечение и округление могут вести к разным результатам;
- проверять поведение преобразования в критичных вычислительных алгоритмах, особенно при накопительных операциях.
Осознанное управление преобразованием позволяет сохранять корректность данных и предотвращает скрытые ошибки, которые проявляются только при работе с реальными числами и большим объёмом операций.
Какие проблемы возникают при сохранении и передаче вещественных чисел
Разные форматы хранения используют различное количество бит для мантиссы и порядка. Перевод между ними может привести к дополнительной потере значимых разрядов. Например, сохранение числа двойной точности в формате одинарной точности уменьшает точность с 52 бит до 23 бит мантиссы, что заметно искажает дробные значения.
При передаче по сети или через текстовые протоколы возникает необходимость сериализации. Преобразование в строковый формат и обратно может вносить дополнительные ошибки, если используется ограниченное количество знаков после запятой. В финансовых и научных вычислениях такие расхождения критичны.
Рекомендации для уменьшения проблем при хранении и передаче:
использовать форматы с достаточной мантиссой для всех критичных вычислений;
для текстовой передачи применять экспоненциальную форму с явным указанием количества знаков;
при взаимодействии между системами с разной архитектурой тестировать корректность восстановления числа;
для финансовых или измерительных данных рассматривать альтернативные типы, например, фиксированную точку или специализированные десятичные типы.
Понимание ограничений форматов хранения и правил сериализации позволяет прогнозировать погрешности и предотвращать накопление ошибок при длительных вычислениях или массовой передаче данных.
Вопрос-ответ:
Почему при сложении 0.1 и 0.2 в большинстве языков результат не равен 0.3?
Это связано с тем, что числа 0.1 и 0.2 не имеют точного двоичного представления в формате IEEE 754. В памяти они сохраняются как ближайшие возможные приближения, и при сложении этих приближений получается значение, чуть отличающееся от 0.3. Такое поведение характерно для большинства дробных чисел, которые не выражаются конечной двоичной дробью. Для сравнения чисел лучше использовать проверку разницы с небольшим допуском, а не прямое равенство.
Что происходит, если вещественное число выходит за диапазон целого типа при преобразовании?
Если вещественное число больше максимального или меньше минимального значения целого типа, результат зависит от языка и настроек компилятора. В некоторых случаях возникает исключение или ошибка выполнения, в других — происходит переполнение, и значение искажается. Например, при преобразовании очень большого положительного числа в 32-битный целый результат может стать отрицательным из-за переполнения. Чтобы избежать проблем, нужно проверять диапазон перед преобразованием и использовать функции, явно управляющие округлением или усечением.
Почему результаты арифметических операций с вещественными числами могут различаться на разных системах?
Разные процессоры и компиляторы могут использовать различное количество регистров и внутреннюю точность вычислений. Некоторые операции выполняются с расширенной точностью, а при сохранении результата в переменной стандартного типа происходит округление. Кроме того, порядок выполнения операций и оптимизации компилятора могут менять конечный результат. Поэтому одно и то же выражение на разных платформах или даже в разных версиях компилятора может давать немного разные значения.
Как правильно хранить вещественные числа в базах данных, чтобы не терялась точность?
Для сохранения вещественных чисел нужно учитывать формат столбца в базе данных. Если используется тип с фиксированной точкой или десятичный тип, дробная часть сохраняется без двоичных приближений, что важно для финансовых расчетов. При использовании стандартного типа с плавающей точкой возможны ошибки из-за округления и ограниченной мантиссы. Кроме того, при передаче через текстовые форматы лучше явно указывать количество знаков после запятой или использовать экспоненциальную запись, чтобы восстановление числа было точным.