Содержание статьи

В языке Си строки представляют собой массивы символов, оканчивающиеся нулевым символом ‘\0’. Для извлечения отдельного слова из такой строки важно правильно определить границы слова, обычно ограниченные пробелами, табуляцией или знаками препинания. Неправильная обработка этих границ может привести к ошибкам в работе программы или к чтению лишних символов.
Существует несколько методов считывания слова: использование функции scanf с форматом %s, обход строки с помощью getchar и формирование собственного массива символов, или применение sscanf для парсинга строки. Каждый метод имеет свои ограничения: scanf остановится на пробеле, getchar требует ручного контроля границ, а sscanf подходит для разбора заранее известной структуры строки.
Для точного считывания слова важно учитывать пробельные символы до и после слова, а также корректно обрабатывать конец строки. Указатели позволяют передвигаться по строке без лишних копирований данных и упрощают проверку каждого символа. Правильное сочетание функций стандартной библиотеки Си и логики обхода массива обеспечивает надежное извлечение слов для дальнейшей обработки, например, подсчета, сравнения или передачи в другие функции.
В этой статье подробно рассматриваются практические подходы к считыванию слова из строки на языке Си, включая примеры кода и рекомендации по обработке различных сценариев ввода. Это позволяет разработчику быстро внедрять проверенные решения в свои программы без ошибок, связанных с границами слов и форматом данных.
Использование функции scanf для считывания отдельного слова

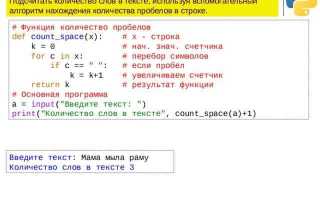
Функция scanf позволяет считывать данные из стандартного ввода, используя форматные спецификаторы. Для извлечения одного слова применяется спецификатор %s, который считывает последовательность непробельных символов до первого пробела, табуляции или символа новой строки. Например, вызов scanf(«%s», word); поместит первое слово из ввода в массив word, который должен быть предварительно выделен достаточного размера.
При использовании scanf важно контролировать размер массива, чтобы избежать переполнения буфера. Например, scanf(«%19s», word); ограничит ввод 19 символами плюс нулевой терминатор, что снижает риск выхода за пределы массива. Этот метод не считывает пробельные символы, поэтому последовательные слова нужно обрабатывать отдельными вызовами scanf или использовать обход строки для более сложной логики.
Функция возвращает количество успешно считанных элементов, что позволяет проверять корректность ввода. Если значение меньше ожидаемого, это сигнализирует о проблемах с форматом или окончании строки. Для безопасного использования в циклах рекомендуется проверять результат scanf перед дальнейшей обработкой данных.
Применение scanf удобно для быстрого извлечения слов из пользовательского ввода или простых строк, когда известна структура данных и не требуется обработка специальных символов внутри слова. Для более сложных случаев лучше использовать функции обхода массива символов или sscanf для разбора заранее подготовленных строк.
Чтение слова через getchar и формирование массива символов

Функция getchar считывает один символ за раз из стандартного ввода, что позволяет полностью контролировать процесс формирования слова. Для этого создается массив символов фиксированной длины, например char word[50], и с помощью цикла каждый символ добавляется в массив до встречи пробела, табуляции или символа новой строки.
Необходимо заранее определить максимальный размер массива, чтобы избежать переполнения буфера. В цикле нужно проверять количество считанных символов и при достижении предела завершать запись, добавляя нулевой символ ‘\0’ для корректного завершения строки. Пример логики: while ((c = getchar()) != ‘ ‘ && c != ‘\n’ && i < MAX-1) { word[i++] = c; } с последующей установкой word[i] = ‘\0’;.
Перед началом считывания рекомендуется пропускать начальные пробельные символы с помощью дополнительного цикла, чтобы массив начинался сразу с первого символа слова. Этот метод позволяет считывать слова в строке без ограничений на формат ввода и дает возможность обрабатывать сложные случаи, например, последовательные пробелы или знаки препинания.
Использование getchar особенно полезно, когда необходимо считывать данные посимвольно и контролировать каждый элемент слова, обеспечивая точную обработку пользовательского ввода или анализа строки без потери информации о структуре текста.
Считывание слова из строки с помощью функции sscanf
Функция sscanf позволяет извлечь слово из строки, не обращаясь к стандартному вводу. Она работает по принципу форматного парсинга, аналогично scanf, но данные берутся из массива символов. Основной формат для считывания одного слова – %s, который захватывает последовательность непробельных символов до пробела или конца строки.
Пример использования:
char str[] = «пример слова»;
char word[20];
sscanf(str, «%19s», word);
В данном случае в массив word попадет «пример», а число 19 ограничивает длину считываемого слова для предотвращения переполнения массива.
Для извлечения нескольких слов можно использовать таблицу с указанием позиции начала слова и длины:
| Строка | Формат sscanf | Результат |
|---|---|---|
| «слово1 слово2» | %19s %19s | word1 = «слово1», word2 = «слово2» |
| «тест,пример» | %19[^,], %19s | word1 = «тест», word2 = «пример» |
Использование sscanf удобно для разбора заранее известной структуры строки, где нужно извлечь слова по шаблону или разделителям. Ограничение длины через число перед s обеспечивает безопасность и предотвращает запись за пределы массива. Функция возвращает количество успешно считанных элементов, что позволяет проверять корректность обработки строки и избегать ошибок при неполных данных.
Использование указателей для прохода по строке и выделения слова
Указатели позволяют обходить строку без копирования символов, что экономит память и ускоряет обработку. Для считывания слова создается указатель на начало строки, например char *ptr = str;, и с его помощью проходит цикл по каждому символу до пробела, табуляции или нулевого символа ‘\0’.
Для выделения слова можно определить два указателя: start указывает на первый символ слова, end – на символ сразу после последнего. Размер слова вычисляется как end — start, после чего можно скопировать слово в массив с добавлением нулевого терминатора ‘\0’ или использовать указатель напрямую для обработки без копирования.
При использовании указателей важно пропускать начальные пробелы перед словом, например циклом while (*ptr == ‘ ‘ || *ptr == ‘\t’) ptr++;. После обработки слова указатель продвигается к следующему слову в строке для последующего анализа. Такой подход позволяет считывать последовательные слова, контролировать длину и легко обрабатывать строки с нестандартными разделителями.
Метод с указателями особенно полезен при работе с большими строками или при необходимости многократного извлечения слов без создания дополнительных массивов, что упрощает функции парсинга и повышает точность обработки текста.
Определение границ слова по пробелам и знакам препинания
Для точного считывания слова из строки важно определить его границы. Обычно словом считается последовательность непробельных символов, ограниченная пробелами, табуляцией или знаками препинания. В Си это реализуется через проверку каждого символа и формирование условия остановки.
Рекомендованные шаги:
- Пропустить начальные пробельные символы с помощью цикла while (*ptr == ‘ ‘ || *ptr == ‘\t’) ptr++;.
- Зафиксировать начало слова: char *start = ptr;.
- Продвигать указатель до первого символа, который является пробелом или знаком препинания. Примеры знаков: .,;:!?()-.
- Фиксировать конец слова: char *end = ptr;.
- Скопировать символы между start и end в массив с добавлением ‘\0’ или использовать указатели напрямую.
Дополнительно можно использовать функцию ispunct() из ctype.h для автоматической проверки знаков препинания:
- Если ispunct(*ptr) возвращает ненулевое значение, это граница слова.
- Можно исключать определенные символы, например апострофы внутри слов, чтобы корректно считывать сокращения и имена.
Такой подход обеспечивает корректное выделение слов в строках с различной пунктуацией и позволяет точно обрабатывать ввод без потери символов.
Пропуск пробельных символов перед и после слова
Перед считыванием слова из строки необходимо пропустить все пробельные символы, включая пробел, табуляцию и символ новой строки. Это гарантирует, что считывание начнется с первого значимого символа. Для этого используют цикл с проверкой *ptr на пробельные символы, например: while (*ptr == ‘ ‘ || *ptr == ‘\t’ || *ptr == ‘\n’) ptr++;.
После окончания считывания слова указатель или индекс массива продвигают за последний символ слова и повторно пропускают пробельные символы перед следующим словом. Это позволяет обрабатывать последовательные слова без включения лишних пробелов и предотвращает ошибки при циклическом чтении.
Использование функции isspace() из ctype.h упрощает проверку всех типов пробелов и делает код более универсальным: while (isspace((unsigned char)*ptr)) ptr++;. Такой подход позволяет корректно считывать слова из строк с произвольными комбинациями пробельных символов.
Обработка конца строки при считывании слова

При чтении слова из строки необходимо контролировать символ конца строки ‘\0’, чтобы избежать выхода за границы массива. Все циклы, проходящие по символам, должны проверять, не достигнут ли этот нулевой терминатор, например: while (*ptr != ‘\0’ && *ptr != ‘ ‘).
Если не учитывать конец строки, последующее копирование символов в массив может привести к чтению случайных данных или переполнению буфера. После нахождения конца слова следует установить нулевой символ ‘\0’ в конце массива для корректного завершения строки.
При использовании функций scanf или sscanf конец строки обычно обрабатывается автоматически, но при ручном обходе символов через указатели или getchar проверка *ptr != ‘\0’ обязательна для всех условий цикла.
Дополнительно рекомендуется проверять результат считывания функции, чтобы убедиться, что слово полностью помещено в массив и достигнут конец строки или разделитель, что предотвращает частичное чтение и ошибки при дальнейшем анализе данных.
Примеры программ для чтения слова из пользовательского ввода

Ниже приведены практические подходы к считыванию слова с клавиатуры на языке Си, учитывающие разные методы работы с вводом.
-
Использование scanf:
- Создать массив символов: char word[20];
- Считать слово: scanf(«%19s», word);
- Результат: массив word содержит первое непробельное слово из ввода.
-
Чтение через getchar:
- Создать массив для слова: char word[50];
- Пропустить пробелы перед словом: while ((c = getchar()) == ‘ ‘ || c == ‘\t’);
- Считывать символы в массив до пробела или новой строки: while (c != ‘ ‘ && c != ‘\n’ && i < 49) word[i++] = c;
- Добавить нулевой терминатор: word[i] = ‘\0’;
-
Использование sscanf для строки:
- Определить строку: char str[] = «пример слова»;
- Создать массив для слова: char word[20];
- Считать слово: sscanf(str, «%19s», word);
- Массив word теперь содержит первое слово строки.
-
Комбинация указателей и проверки пробелов:
- Указать на начало строки: char *ptr = str;
- Пропустить пробелы: while (*ptr == ‘ ‘ || *ptr == ‘\t’) ptr++;
- Зафиксировать начало слова: char *start = ptr;
- Продвигать указатель до пробела или конца строки: while (*ptr != ‘ ‘ && *ptr != ‘\0’) ptr++;
- Вычислить длину и скопировать в массив с нулевым символом.
Эти примеры позволяют выбирать подходящий метод в зависимости от структуры ввода и требований к обработке слов, обеспечивая безопасное и точное считывание данных.
Вопрос-ответ:
Какая разница между scanf и getchar при считывании слова?
Функция scanf считывает слово до первого пробела, табуляции или новой строки, помещая его в массив символов, но не позволяет контролировать каждый символ. getchar читает по одному символу, что дает возможность пропускать пробелы, проверять знаки препинания и управлять границами слова вручную.
Как избежать переполнения массива при считывании слова?
Перед считыванием необходимо определить размер массива для слова и использовать ограничение длины при функции scanf, например %19s для массива из 20 символов. При чтении через getchar или указатели следует проверять индекс массива и завершать запись нулевым символом ‘\0’, если достигнут предел.
Можно ли считывать несколько слов из одной строки с помощью sscanf?
Да, с помощью sscanf можно извлечь несколько слов, указав несколько спецификаторов %s, например sscanf(str, «%19s %19s», word1, word2);. Для сложных разделителей используют набор символов, например %19[^,], чтобы выделить слово до запятой.
Как пропускать пробельные символы перед и после слова?
Перед началом считывания следует пройти все пробелы и табуляции циклом: while (*ptr == ‘ ‘ || *ptr == ‘\t’) ptr++;. После окончания слова указатель или индекс продвигается за пробелы перед следующим словом. Для универсальной проверки удобно использовать isspace() из ctype.h.
Что делать при достижении конца строки во время считывания слова?
Необходимо проверять нулевой символ ‘\0’ в условиях циклов чтения, чтобы избежать выхода за границы массива. После достижения конца строки копирование или обработка слова завершается, и в массив добавляется ‘\0’. Этот метод предотвращает ошибки при работе с массивами и указателями.
Как правильно считывать слово из строки с пробелами и знаками препинания?
Для считывания слова необходимо определить его границы: пропустить начальные пробельные символы, зафиксировать начало слова, продвигать указатель или индекс до пробела, табуляции или знака препинания, после чего завершить запись нулевым символом ‘\0’. Функции scanf, getchar или комбинация указателей с проверкой символов позволяют реализовать этот процесс.
Как избежать ошибок при считывании слова через массив символов?
Важно заранее выделить массив достаточного размера и контролировать длину вводимых символов. При использовании scanf указывают максимальное количество символов, например %19s для массива из 20 символов. При ручном считывании через getchar или указатели проверяют индекс массива и устанавливают ‘\0’ в конце, чтобы предотвратить выход за границы и корректно завершить строку.