Проблемы с кодировкой проявляются в виде «кракозябр», потери символов или некорректного отображения кириллицы при открытии файлов, загрузке данных в базу или публикации контента в интернете. В большинстве случаев причина сводится к несовпадению исходной кодировки текста и той, которую ожидает программа, браузер или операционная система. UTF-8 стал стандартом де-факто благодаря поддержке всех языков Unicode и совместимости с ASCII, поэтому перевод данных в этот формат позволяет избежать большинства конфликтов.
На практике перевод кодировки – это не абстрактная задача, а набор конкретных действий: определить исходную кодировку файла, выбрать подходящий инструмент для конвертации и проверить результат. Например, текст, сохранённый в Windows-1251, при открытии в среде, настроенной на UTF-8 без конвертации, будет отображаться с искажениями. Аналогичные ошибки возникают при импорте CSV в базы данных, работе с логами или переносе проектов между серверами.
Особое внимание требуется при работе с программным кодом, HTML-страницами и базами данных. Неверно заданная кодировка может привести не только к визуальным ошибкам, но и к сбоям в обработке строк, некорректной сортировке и невозможности поиска данных. Поэтому перевод текста в UTF-8 должен сопровождаться проверкой метатегов, параметров подключения к БД и настроек окружения, в котором эти данные используются.
Определение текущей кодировки текста и файлов
Перед переводом текста в UTF-8 необходимо точно определить исходную кодировку, иначе результатом станет повреждённый контент. Для текстовых файлов в операционных системах Linux и macOS используется команда file с параметром -i, которая анализирует байтовую структуру и возвращает предполагаемую кодировку, например charset=windows-1251 или charset=utf-8. Проверку следует выполнять именно на исходном файле, а не на его копии, уже открытой в редакторе.
В графических редакторах кода и IDE кодировка отображается в строке состояния. Важно учитывать, что редактор может автоматически интерпретировать файл как UTF-8, даже если фактическая кодировка отличается. Для проверки следует отключить автодетект и принудительно открыть файл в предполагаемой кодировке, сравнивая читаемость текста. Если кириллица корректна только при выборе Windows-1251 или KOI8-R, это указывает на реальный формат хранения данных.
Для веб-документов требуется анализировать не только файл, но и сопутствующие метаданные. В HTML необходимо проверить наличие тега <meta charset=»…»>, а также заголовок Content-Type, который может передаваться сервером. Несоответствие между заявленной и фактической кодировкой приводит к искажению текста даже при корректных данных в файле.
При работе с базами данных кодировка определяется на уровне таблиц, столбцов и подключения. В MySQL используются запросы SHOW VARIABLES LIKE ‘character_set%’ и SHOW FULL COLUMNS, которые показывают, в каком формате хранятся строки. Если данные отображаются корректно только при изменении кодировки соединения, это сигнал о различии между форматом хранения и параметрами клиента.
Для бинарных и смешанных файлов автоматическое определение может быть неточным. В таких случаях рекомендуется открыть файл в шестнадцатеричном редакторе и проверить наличие BOM-маркера UTF-8 (EF BB BF) или характерных байтовых последовательностей кириллицы. Этот метод позволяет подтвердить кодировку, когда программные средства дают противоречивые результаты.
Перевод кодировки через текстовые редакторы и IDE
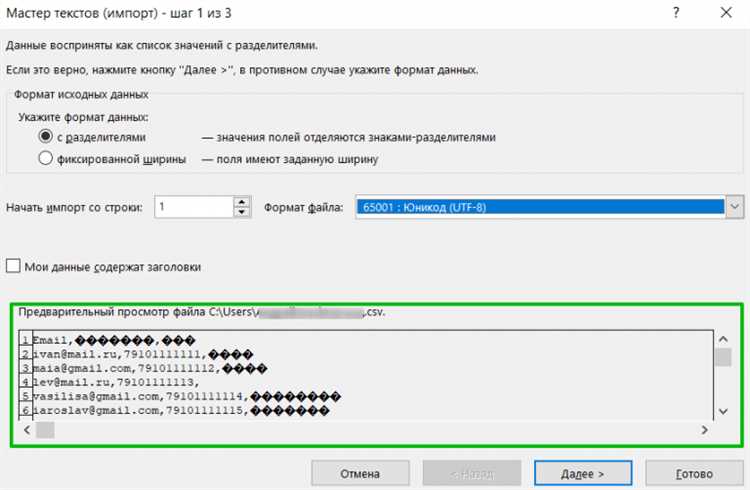
Текстовые редакторы и среды разработки позволяют перевести файл в UTF-8 без использования командной строки, но требуют строгого соблюдения последовательности действий. Ключевое правило – сначала открыть файл в правильной исходной кодировке, а уже затем сохранить его в новом формате. Пропуск этого шага приводит к необратимой порче символов.
В Notepad++ процесс выполняется через меню Кодировки. Для корректного результата необходимо:
- выбрать пункт Кодировать в ANSI или другую предполагаемую исходную кодировку;
- убедиться, что текст отображается без искажений;
- использовать команду Преобразовать в UTF-8 без BOM;
- сохранить файл, не меняя его расширение.
В Visual Studio Code кодировка указывается через строку состояния или команду Reopen with Encoding. Практика работы выглядит следующим образом:
- перезапустить открытие файла с явным указанием исходной кодировки;
- проверить корректность символов, особенно кириллицы и спецзнаков;
- выполнить Save with Encoding → UTF-8;
- проверить результат повторным открытием файла.
В IDE семейства JetBrains (IntelliJ IDEA, PhpStorm, PyCharm) кодировка задаётся на уровне проекта и конкретного файла. Перед сохранением требуется установить нужный формат в параметрах File Encoding и отключить автоматическое преобразование при загрузке. Это предотвращает ситуацию, когда IDE пытается интерпретировать файл как UTF-8, игнорируя реальную кодировку.
Для пакетной обработки нескольких файлов рекомендуется использовать встроенные функции массового сохранения или плагины, поддерживающие перекодировку. При этом обязательна предварительная проверка выборки файлов, так как смешение разных кодировок в одном наборе часто приводит к частичной потере данных.
Конвертация файлов в UTF-8 с помощью командной строки (iconv)

Утилита iconv доступна по умолчанию в большинстве дистрибутивов Linux и macOS и предназначена для точного преобразования кодировок на уровне байтов. Она работает напрямую с файлами, минуя интерпретацию редактора, что снижает риск искажения данных при массовой обработке.
Базовый принцип использования заключается в явном указании исходной и целевой кодировки. Если исходный формат определён неверно, результат будет содержать повреждённые символы, поэтому перед запуском рекомендуется проверить кодировку через file -i или аналогичные средства.
| Задача | Пример команды iconv |
|---|---|
| Перевод файла из Windows-1251 в UTF-8 | iconv -f WINDOWS-1251 -t UTF-8 input.txt -o output.txt |
| Конвертация KOI8-R в UTF-8 | iconv -f KOI8-R -t UTF-8 source.txt > result.txt |
| Удаление некорректных символов | iconv -f CP1251 -t UTF-8//IGNORE data.txt -o clean.txt |
Параметр //IGNORE позволяет пропускать байты, не соответствующие заявленной кодировке, а //TRANSLIT заменяет неподдерживаемые символы ближайшими аналогами. Эти опции полезны при обработке логов и файлов, полученных из сторонних систем, где возможны смешанные форматы.
Для конвертации группы файлов применяется цикл оболочки. Например, при работе с каталогом текстов в одной кодировке целесообразно создавать копии с новым расширением, чтобы сохранить исходные данные для проверки. После завершения конвертации рекомендуется выборочно открыть несколько файлов и убедиться, что кириллица и спецсимволы отображаются корректно.
В среде Windows iconv используется через подсистему WSL или в составе пакетов GNU. Важно учитывать, что стандартная консоль Windows может отображать UTF-8 некорректно без смены кодовой страницы, поэтому проверку результата лучше выполнять в редакторе с поддержкой Unicode.
Перевод кодировки данных в базах данных MySQL и PostgreSQL
Перевод данных в UTF-8 в СУБД требует работы сразу на нескольких уровнях: кодировка хранилища, параметры таблиц и настройки клиентского подключения. Если изменить только один из них, данные могут продолжать отображаться некорректно или сохраняться с искажениями.
В MySQL сначала проверяется текущая конфигурация через системные переменные character_set_server, character_set_database и collation_server. Для перевода существующей базы используется команда ALTER DATABASE с указанием CHARACTER SET utf8mb4, так как именно этот вариант UTF-8 поддерживает полный набор Unicode, включая эмодзи и редкие символы.
После изменения кодировки базы необходимо последовательно обновить все таблицы. Команда ALTER TABLE имя_таблицы CONVERT TO CHARACTER SET utf8mb4 перекодирует данные на уровне столбцов. Пропуск этого шага приводит к ситуации, когда база объявлена как UTF-8, а данные внутри остаются в старом формате, например Windows-1251.
Особое внимание уделяется соединению клиента с сервером MySQL. Перед импортом или обновлением данных требуется явно задать SET NAMES utf8mb4 или настроить кодировку подключения в конфигурации драйвера. Без этого данные могут быть повторно искажены при записи, даже если структура базы уже переведена.
В PostgreSQL кодировка задаётся на этапе создания базы данных и не может быть изменена напрямую. Для перевода существующих данных применяется схема с дампом: база выгружается в текстовый формат с корректной интерпретацией исходной кодировки, после чего создаётся новая база с ENCODING ‘UTF8’ и выполняется восстановление данных.
При работе с PostgreSQL важно проверить параметр client_encoding. Он должен соответствовать фактической кодировке данных на стороне клиента. Несовпадение приводит к ошибкам при вставке строк или к повреждению символов при выборке. Корректная настройка кодировки соединения обеспечивает сохранность данных на всех этапах миграции.
После завершения перевода рекомендуется выполнить выборочную проверку строк с кириллицей, спецсимволами и длинными текстами. Это позволяет выявить ошибки, возникшие на этапе дампа, импорта или при неправильном определении исходной кодировки.
Настройка UTF-8 для HTML, CSS и PHP файлов
Для корректной работы с UTF-8 в веб-проектах недостаточно перекодировать сами файлы – требуется согласованная настройка на уровне разметки, стилей и серверной логики. Несоответствие хотя бы одного элемента приводит к искажению текста в браузере или при обработке данных.
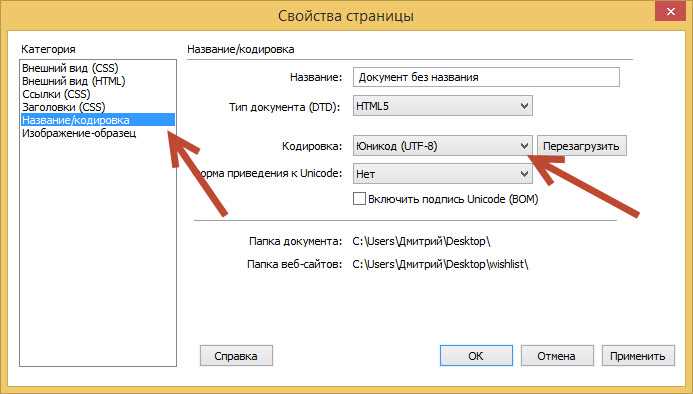
В HTML-файлах кодировка должна задаваться явно и как можно раньше. Используется тег <meta charset=»UTF-8″>, который размещается в начале секции <head>. Отсутствие этого тега или его конфликт с HTTP-заголовками сервера может привести к тому, что браузер попытается угадать кодировку, что часто заканчивается ошибками при отображении кириллицы.
CSS-файлы также должны быть сохранены в UTF-8, особенно если в них используются комментарии, псевдоэлементы с текстом или шрифты с локальными названиями. При необходимости в начале файла указывается директива @charset «UTF-8»;. Она должна быть первой строкой, без пробелов и комментариев перед ней, иначе браузер её проигнорирует.
При работе со строками в PHP необходимо убедиться, что функции обработки текста поддерживают Unicode. Для этого используется расширение mbstring, а внутренняя кодировка задаётся через mb_internal_encoding(«UTF-8»). Без этого операции с длиной строк, подстроками и регистром могут работать некорректно.
Завершающий шаг – проверка согласованности: файл сохранён в UTF-8, HTML объявляет UTF-8, сервер отправляет правильные заголовки, а PHP-скрипты не выполняют скрытую перекодировку. Только при совпадении всех этих условий текст отображается и обрабатывается без искажений.
Исправление проблем с UTF-8 в Windows и Linux
Отдельного внимания заслуживает параметр системы «Использовать Юникод (UTF-8) для поддержки языка во всём мире». Его включение меняет поведение приложений, ориентированных на ANSI-кодировки. Перед активацией необходимо проверить совместимость используемого ПО, так как некоторые программы продолжают сохранять данные в Windows-1251, но интерпретируются системой как UTF-8.
В текстовых файлах под Windows часто встречается BOM-маркер. Он может вызывать ошибки в скриптах, конфигурациях и при обработке данных сторонними утилитами. При появлении неожиданных символов в начале файла следует пересохранить его в UTF-8 без BOM и повторно проверить результат.
В Linux проблемы с UTF-8 чаще всего возникают из-за некорректно настроенных локалей. Проверка выполняется через переменные окружения LANG и LC_ALL. Если они указывают на устаревшую или несовместимую кодировку, приложения будут неправильно интерпретировать строки, даже если файлы сохранены в UTF-8.
Если проблема проявляется только в отдельных программах, следует проверить их конфигурацию. Некоторые утилиты игнорируют системные локали и используют собственные настройки кодировки. Исправление сводится к явному указанию UTF-8 в конфигурационных файлах или параметрах запуска, после чего отображение текста стабилизируется.
Вопрос-ответ:
Почему после перекодировки файла в UTF-8 текст всё равно отображается с искажениями?
Чаще всего файл был открыт в неверной исходной кодировке перед сохранением. Редактор интерпретировал байты неправильно и сохранил уже повреждённые символы в UTF-8. Исправление возможно только при наличии оригинального файла. Его нужно открыть с явным указанием правильной кодировки, проверить читаемость текста и только после этого сохранить в UTF-8 без BOM.
Чем отличается UTF-8 с BOM от UTF-8 без BOM и какой вариант использовать?
BOM — это служебная сигнатура в начале файла, которая указывает на кодировку. Для обычных текстовых документов она не мешает, но в PHP-скриптах, конфигурациях и некоторых форматах может вызывать ошибки или лишние символы. Для веб-разработки и серверных файлов рекомендуется UTF-8 без BOM, так как он корректно читается всеми современными системами.
Как понять, что проблема связана с кодировкой базы данных, а не с кодом приложения?
Если данные выглядят корректно при прямом просмотре в базе, но искажаются при выводе в приложении, причина обычно в кодировке соединения. Если же «кракозябры» видны уже в самой таблице, значит данные были записаны в неверном формате. Проверка параметров character set на стороне СУБД и клиента позволяет быстро определить источник ошибки.
Можно ли безопасно перекодировать сразу много файлов в UTF-8 через командную строку?
Да, но только при уверенности, что все файлы имеют одну и ту же исходную кодировку. Перед массовой обработкой следует проверить несколько файлов выборочно. Рекомендуется сохранять результат в новые файлы или отдельный каталог, чтобы при ошибке была возможность вернуться к исходным данным.
Почему в Linux файлы в UTF-8 выглядят нормально, а при открытии в Windows появляются ошибки?
Причина часто связана не с кодировкой файла, а с настройками Windows и используемого редактора. Некоторые программы по умолчанию открывают файлы как Windows-1251 или добавляют BOM при сохранении. Решение — использовать редактор с явным выбором кодировки и проверить, что файл сохранён в UTF-8 без дополнительных маркеров.