В реальных проектах данные часто поступают с лишними пробелами, управляющими символами или спецсимволами, которые мешают корректной обработке. Например, строки из CSV-файлов могут содержать пробелы в начале и конце, табуляции или символы переноса строки, влияющие на точность поиска и сравнения.
Python предоставляет встроенные методы strip(), lstrip() и rstrip(), позволяющие удалять лишние символы в начале и конце строк. Использование strip(chars) помогает убрать конкретные символы, такие как кавычки, точки с запятой или спецсимволы, без необходимости писать сложные функции.
Для очистки текста внутри строки можно использовать replace() или регулярные выражения через модуль re. Они позволяют удалять все вхождения нежелательных символов, включая цифры, знаки препинания или символы Unicode, что важно при подготовке данных для анализа или машинного обучения.
Особое внимание стоит уделить нормализации строк с помощью unicodedata, которая устраняет различия между визуально одинаковыми символами, представленными разными кодами. Это особенно полезно при обработке текстов на нескольких языках или с нестандартными символами.
Практика показывает, что последовательное применение этих методов позволяет уменьшить количество ошибок при парсинге, сортировке и поиске по строкам, сокращая время на отладку и повышая точность результатов. Очистка строк становится критическим этапом подготовки данных, влияющим на последующую обработку и анализ.
Удаление пробелов в начале и конце строки с помощью strip()

Метод strip() удаляет все пробельные символы в начале и конце строки, включая пробел, табуляцию (\t) и символы переноса строки (\n). Например, строка ‘ Пример текста \n’ после применения strip() превратится в ‘Пример текста’, что упрощает последующую обработку.
Использование strip() особенно важно при чтении данных из внешних источников, таких как CSV или JSON, где лишние пробелы могут нарушить сравнение строк или привести к неверному разбору полей.
Метод работает напрямую на строке и возвращает новый объект, оставляя исходную строку без изменений. Для применения в циклах или списках можно использовать генераторы или списковые включения: [s.strip() for s in data], что позволяет очистить все элементы без дополнительных функций.
При необходимости удалять только с одной стороны строки применяют lstrip() для начала или rstrip() для конца, что дает точный контроль над обработкой текста.
Удаление конкретных символов с помощью метода strip(chars)

Метод strip(chars) позволяет удалить из начала и конца строки любые указанные символы, а не только пробелы. Параметр chars принимает строку с набором символов, которые нужно убрать. Например, ‘*Пример*’.strip(‘*’) вернёт ‘Пример’.
Метод полезен для очистки данных, содержащих лишние знаки препинания или кавычки, которые могут мешать дальнейшему анализу или парсингу. Он удаляет все комбинации символов из параметра, пока не встретит символ, не включённый в chars.
Пример практического использования:
| Исходная строка | Метод | Результат |
|---|---|---|
| ‘»Название продукта» | strip(‘»‘) | ‘Название продукта’ |
| ‘—данные—‘ | strip(‘-‘) | ‘данные’ |
| ‘###Отчет###’ | strip(‘#’) | ‘Отчет’ |
Важно помнить, что strip(chars) не удаляет символы внутри строки, только на её границах. Для внутренней очистки применяют replace() или регулярные выражения. Использование strip(chars) повышает точность обработки данных и сокращает ошибки при сравнении или сохранении текстов.
Удаление символов только слева или справа с lstrip() и rstrip()
Методы lstrip() и rstrip() удаляют пробелы или указанные символы только с одной стороны строки. lstrip() очищает начало строки, а rstrip() – конец. Это полезно, когда необходимо сохранить часть данных и не изменять противоположный край.
Примеры использования:
- ‘ текст’.lstrip() → ‘текст’ – убирает пробелы только слева.
- ‘текст ‘.rstrip() → ‘текст’ – убирает пробелы только справа.
- ‘—данные—‘.lstrip(‘-‘) → ‘данные—‘ – удаляет символы «-» только слева.
- ‘—данные—‘.rstrip(‘-‘) → ‘—данные’ – удаляет символы «-» только справа.
Рекомендации по применению:
- Использовать lstrip() при очистке префиксов или управляющих символов в начале строки.
- Использовать rstrip() для удаления суффиксов, переносов строки или лишних символов в конце.
- При массовой обработке данных применять списковые включения: [s.lstrip() for s in data] или [s.rstrip(‘-‘) for s in data].
- Комбинировать lstrip() и rstrip() для точечного удаления, если метод strip() очищает слишком много.
Использование этих методов позволяет точно контролировать форматирование строк, предотвращает случайное удаление значимых символов и улучшает совместимость данных с последующей обработкой.
Удаление всех вхождений символа внутри строки через replace()

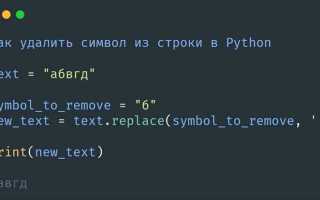
Метод replace() позволяет удалять или заменять все вхождения указанного символа или подстроки в строке. В отличие от strip(), он обрабатывает символы по всей длине строки, включая середину. Например, ‘тексто, текcт’.replace(‘,’, ») вернёт ‘тексто текcт’, удалив запятую.
Метод принимает два аргумента: old – символ или подстроку, которую нужно удалить, и new – строку, на которую будет заменено вхождение. Для полного удаления символа указывают new=». Он возвращает новую строку, оставляя исходную без изменений.
Примеры практического использования:
- Удаление всех пробелов внутри строки: ‘т е к с т’.replace(‘ ‘, ») → ‘текст’.
- Удаление символов переноса строки и табуляции: text.replace(‘\n’, »).replace(‘\t’, »).
- Удаление лишних знаков препинания: ‘привет!!!’.replace(‘!’, ») → ‘привет’.
Рекомендации по применению:
- Использовать replace() для очистки текста от символов, которые могут встречаться внутри строки и нарушать анализ.
- При необходимости удаления нескольких разных символов использовать цепочку вызовов replace() или регулярные выражения для повышения читаемости кода.
- Метод эффективен при подготовке данных для анализа, поиска и нормализации текста перед сохранением или обработкой.
Удаление небуквенных и ненумерических символов с помощью регулярных выражений

Основной шаблон для удаления небуквенно-цифровых символов: [^a-zA-Z0-9]. Он находит все символы, кроме латинских букв и цифр. Для работы с русским текстом используют диапазон Unicode: [^а-яА-Яa-zA-Z0-9].
Примеры практического применения:
- Удаление всех спецсимволов: re.sub(r'[^a-zA-Z0-9]’, », text).
- Очистка строки от знаков препинания: re.sub(r'[^\w]’, », text) – \w включает буквы, цифры и подчёркивания.
- Удаление всех символов, кроме русских и цифр: re.sub(r'[^а-яА-Я0-9]’, », text).
Рекомендации:
- Использовать re.sub() для очистки больших массивов текста и данных с нестандартными символами.
- Для многоязычного текста включать соответствующие диапазоны Unicode.
- При необходимости сохранить пробелы между словами добавлять их в шаблон исключения: [^а-яА-Яa-zA-Z0-9 ].
- Регулярные выражения позволяют комбинировать очистку от нескольких типов символов в одной операции, сокращая код и повышая производительность.
Очистка строк от символов переноса и табуляции
Символы переноса строки (\n, \r) и табуляции (\t) часто попадают в текст при чтении файлов или пользовательского ввода. Их наличие может нарушить сравнение строк, форматирование или разбор данных.
Самый простой способ удалить их – использовать replace():
- text.replace(‘\n’, »).replace(‘\r’, »).replace(‘\t’, ») – удаляет все переносы и табуляции из строки.
- Для очистки начала и конца строки вместе с пробелами можно сочетать с strip(): text.strip().replace(‘\t’, »).
Для массовой обработки данных применяют списковые включения: [s.replace(‘\n’, »).replace(‘\t’, ») for s in data], что ускоряет очистку больших массивов текста.
Регулярные выражения через re.sub() позволяют комбинировать удаление разных управляющих символов за одну операцию: re.sub(r'[\n\r\t]+’, », text). Это сокращает код и снижает вероятность пропуска символов.
Удаление этих символов критично при подготовке текстов для CSV, JSON или баз данных, а также при нормализации строк перед анализом, поиском или машинным обучением.
Приведение строки к нормализованной форме с unicodedata
В Unicode один и тот же символ может иметь несколько кодовых представлений. Например, буква «é» может быть одной кодовой точкой или комбинацией «e» и акцента. Это вызывает ошибки при сравнении строк или поиске.
Модуль unicodedata предоставляет функцию normalize(), которая преобразует строку в одну из стандартных форм: NFC, NFD, NFKC или NFKD. Например, unicodedata.normalize(‘NFC’, text) объединяет символы и диакритические знаки в единую кодовую точку.
Рекомендации по применению:
- Использовать normalize(‘NFC’) для объединения символов перед сравнением или сохранением в базе данных.
- NFD подходит для анализа и разложения символов на составные части, полезно при фильтрации или поиске по диакритике.
- Комбинировать с методами strip() и replace() для комплексной очистки текста, включая лишние пробелы и спецсимволы.
- Применять нормализацию при работе с многоязычными текстами, чтобы избежать рассинхронизации символов между разными источниками данных.
Удаление повторяющихся или лишних символов подряд
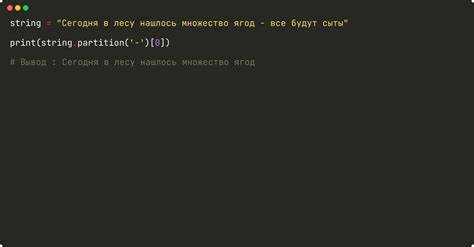
Строки часто содержат повторяющиеся символы, например несколько пробелов, дефисов или знаков препинания подряд, которые мешают анализу и нормализации текста. Python позволяет удалять такие дубли с помощью регулярных выражений или циклов.
Пример с регулярными выражениями: re.sub(r'(.)\1+’, r’\1′, text) заменяет любые повторяющиеся символы на один экземпляр. Например, ‘ааабббвв’. после применения станет ‘абв’.
Для конкретных символов можно использовать уточнённый шаблон: re.sub(r’\s+’, ‘ ‘, text) – заменяет несколько пробелов одним пробелом, а re.sub(r’-+’, ‘-‘, text) – сокращает повторяющиеся дефисы.
Рекомендации:
- Использовать регулярные выражения для очистки больших текстовых массивов с повторяющимися символами.
- Для отдельных символов, таких как пробел или дефис, применять конкретные шаблоны для сохранения читаемости текста.
- После удаления повторов комбинировать с strip() или normalize() для окончательной очистки и нормализации строки.
- Метод позволяет предотвращать ошибки при парсинге, сравнении и хранении текста, сохраняя структуру данных и повышая точность обработки.
Вопрос-ответ:
Почему после чтения CSV-файла в Python строки содержат лишние пробелы и символы переноса?
Файлы CSV часто создаются в текстовых редакторах или экспортируются из других программ, где поля могут быть окружены пробелами, табуляцией или символами переноса строки. Эти символы не видны визуально, но при обработке данных вызывают ошибки сравнения строк, некорректное разбиение на столбцы или проблемы при сохранении в базу данных. Для очистки используют методы strip(), lstrip(), rstrip(), а также регулярные выражения, если необходимо удалить символы внутри строки.
Как убрать из строки повторяющиеся дефисы или пробелы между словами?
Для удаления повторяющихся символов удобно применять регулярные выражения. Например, re.sub(r’\s+’, ‘ ‘, text) заменяет несколько пробелов одним, а re.sub(r’-+’, ‘-‘, text) сокращает повторяющиеся дефисы до одного. Такой подход сохраняет структуру текста, предотвращает ошибки при разбиении на слова и улучшает читаемость данных перед сохранением или анализом.
В чем разница между strip() и replace() при очистке строк?
strip() удаляет символы только с начала и конца строки, оставляя внутренние вхождения без изменений. Это удобно для удаления пробелов, кавычек или дефисов вокруг текста. replace() заменяет символы или подстроки по всей длине строки, включая середину, и подходит для удаления всех повторяющихся символов или знаков препинания внутри текста. Выбор метода зависит от того, где находятся нежелательные символы и требуется ли их удаление внутри строки.
Как нормализовать строки с различными кодировками символов, например буквы с диакритикой?
В Unicode один и тот же символ может иметь несколько представлений. Например, «é» может быть одной кодовой точкой или комбинацией «e» и акцента. Для приведения таких символов к единой форме используют unicodedata.normalize(). Режим NFC объединяет символы и диакритические знаки в одну кодовую точку, а NFD разлагает на составные части. Нормализация предотвращает ошибки при сравнении строк, поиске и сохранении текста в базе данных.