Содержание статьи

В Python словарь и множество решают разные задачи, но на практике часто возникает необходимость преобразовать один тип данных в другой. Словарь хранит пары ключ–значение, тогда как множество предназначено для работы с уникальными элементами. Понимание того, какие именно данные из словаря нужно перенести в множество – ключи, значения или их комбинации – позволяет избежать логических ошибок и лишних преобразований.
Чаще всего множество используется для удаления дублей, проверки принадлежности элемента или выполнения операций объединения и пересечения. Например, при анализе данных словарь может содержать повторяющиеся значения, которые требуется привести к уникальному набору. В таких случаях преобразование значений словаря через set() становится прямым и наглядным решением.
Важно учитывать, что множество принимает только хешируемые объекты. Это напрямую влияет на работу со словарями, в которых значения представлены списками, другими словарями или структурами с изменяемым состоянием. Непонимание этого ограничения часто приводит к исключениям времени выполнения, поэтому при преобразовании требуется заранее продумать формат данных.
Отдельного внимания заслуживает потеря порядка элементов. В отличие от словаря, который начиная с Python 3.7 сохраняет порядок добавления, множество этим свойством не обладает. При преобразовании это может повлиять на дальнейшую обработку данных, особенно если порядок элементов используется неявно. В статье рассматриваются практические подходы, позволяющие учитывать эти особенности при работе с реальными задачами.
Преобразование ключей словаря в множество с помощью set()

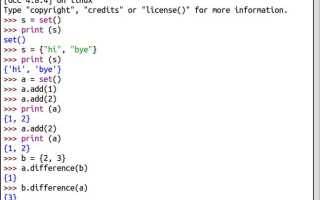
Ключи словаря в Python уже обладают свойством уникальности, поэтому их преобразование в множество чаще всего требуется для выполнения операций, недоступных напрямую для словарей: проверки пересечений, разностей или объединений. Для этого используется встроенная функция set(), принимающая любой итерируемый объект, включая словарь.
При передаче словаря в set() без дополнительных методов Python неявно итерируется по его ключам. Это поведение эквивалентно вызову set(my_dict.keys()), но запись короче и читается проще. Такой подход подходит для случаев, когда требуется получить независимую структуру данных без связи с исходным словарём.
Полученное множество содержит только ключи и не отражает ассоциации со значениями. Это важно учитывать при дальнейшем использовании, поскольку восстановить исходные пары ключ–значение из множества невозможно. Если ключи используются как идентификаторы или категории, такое преобразование упрощает сравнение наборов данных из разных источников.
Типы ключей также имеют значение: все ключи словаря обязаны быть хешируемыми, поэтому они без ограничений подходят для множества. Числа, строки, кортежи и неизменяемые пользовательские объекты переносятся без преобразований. Это делает set() надёжным инструментом при работе со словарями любого размера, включая структуры с тысячами элементов.
Получение множества значений словаря и устранение повторов
Значения словаря не обладают гарантией уникальности, поэтому при анализе данных часто требуется получить их набор без дубликатов. Для этого применяется преобразование результата метода values() в множество: set(my_dict.values()). Такой подход позволяет сразу отбросить повторяющиеся элементы без дополнительной логики.
Преобразование значений в множество особенно полезно при работе со справочниками, конфигурациями и агрегированными данными, где разные ключи могут указывать на одинаковые параметры. Множество упрощает проверку наличия конкретного значения и выполнение операций сравнения с другими наборами данных.
Важно учитывать типы хранимых значений. В множество могут быть добавлены только хешируемые объекты, поэтому списки, словари и другие изменяемые структуры приведут к исключению TypeError. В таких случаях требуется предварительное преобразование значений, например замена списков на кортежи или извлечение отдельных элементов.
Результат вызова set() не сохраняет порядок значений, присутствующий в исходном словаре. Если порядок важен для дальнейшей обработки, следует зафиксировать его отдельно или использовать альтернативные структуры данных. При задачах, связанных исключительно с уникальностью, это ограничение не влияет на корректность результата.
Создание множества пар ключ-значение через items()
Такой подход подходит для задач сравнения словарей, поиска отличий между версиями данных или фиксации снимка состояния структуры. Поскольку кортежи неизменяемы, они без ограничений добавляются в множество, при условии что и ключ, и значение также являются хешируемыми.
Важно помнить, что при наличии не хешируемых значений, например списков или вложенных словарей, прямое преобразование приведёт к ошибке. В подобных ситуациях данные требуется привести к допустимому формату заранее, иначе множество создать не получится.
| Исходный словарь | Элемент множества |
|---|---|
| ключ: «a», значение: 1 | («a», 1) |
| ключ: «b», значение: 2 | («b», 2) |
Полученное множество полностью теряет семантику словаря как структуры сопоставления, но сохраняет уникальность каждой пары. Это делает метод items() полезным инструментом при проверке совпадений данных между разными источниками или при формировании контрольных наборов для тестирования.
Формирование множества значений по заданному условию

Не все значения словаря всегда подходят для дальнейшей обработки, поэтому часто требуется сформировать множество только из элементов, удовлетворяющих конкретному условию. Для этого применяется генератор множества с фильтрацией значений на этапе создания. Такой подход позволяет объединить отбор и устранение дублей в одном выражении.
Условие может опираться на тип данных, диапазон чисел или соответствие шаблону строки. На практике чаще всего проверяются значения, а не ключи, так как именно они содержат полезные данные.
- отбор числовых значений больше заданного порога;
- включение только строк с определённым префиксом;
- исключение пустых или равных None элементов;
- фильтрация по типу с использованием isinstance().
При работе с большими словарями генератор множества снижает объём промежуточных данных, так как элементы добавляются напрямую в итоговую структуру. Это особенно полезно при анализе логов, пользовательских параметров или агрегированных результатов вычислений.
- Получить доступ к значениям через values().
- Определить логическое условие отбора.
- Создать множество с помощью фигурных скобок.
Результирующее множество содержит только элементы, прошедшие проверку, и не зависит от исходного порядка в словаре. Такой способ удобен для последующих операций сравнения и проверки принадлежности значений.
Преобразование вложенного словаря в множество элементов

Вложенные словари требуют предварительного выбора стратегии извлечения данных, так как напрямую добавить их в множество невозможно. Основная задача – определить, какие элементы должны стать частью множества: внутренние ключи, значения или агрегированные пары.
Наиболее распространённый подход – последовательный обход вложенных структур с извлечением хешируемых элементов. Для этого используется итерация по верхнему уровню словаря с дальнейшей обработкой каждого вложенного словаря отдельно.
- извлечение всех внутренних ключей независимо от родительских;
- сбор значений из вложенных словарей в единый набор;
- формирование кортежей вида (внешний_ключ, внутренний_ключ);
- объединение нескольких уровней данных в плоскую структуру.
Если значения вложенного словаря представлены изменяемыми типами, их необходимо привести к кортежам или строкам до добавления в множество. Игнорирование этого шага приводит к ошибкам выполнения и делает преобразование невозможным.
- Определить глубину вложенности и формат итоговых элементов.
- Выполнить обход словаря с помощью циклов или генераторов.
- Добавлять в множество только хешируемые объекты.
Результатом становится плоское множество, удобное для анализа структуры данных, поиска уникальных элементов или сравнения вложенных конфигураций между собой.
Работа с не хешируемыми значениями при создании множества
Множество в Python принимает только хешируемые объекты, поэтому значения словаря в виде списков, других словарей или множеств не могут быть добавлены напрямую. Попытка преобразовать такие данные приводит к исключению TypeError: unhashable type, что требует предварительной подготовки структуры.
Наиболее распространённое решение – преобразование изменяемых объектов в неизменяемые аналоги. Списки заменяются на кортежи, а вложенные словари могут быть приведены к кортежам пар или сериализованы в строки. Выбор подхода зависит от того, какие свойства данных важны при дальнейшем использовании множества.
Если значение словаря содержит сложную структуру, допустимо извлекать только её хешируемую часть. Например, из словаря с пользовательскими настройками можно выбрать отдельные параметры, игнорируя вложенные коллекции. Это снижает риск логических ошибок и упрощает сравнение элементов.
В случаях, когда исходный объект не должен изменяться, преобразование следует выполнять на копии данных. Такой подход сохраняет целостность словаря и позволяет использовать множество как независимый набор для проверок, поиска совпадений и операций над уникальными элементами с применением set().
Потеря порядка элементов при использовании множества и обходные решения

При преобразовании словаря в множество порядок элементов утрачивается, так как set не фиксирует последовательность добавления. Это отличие особенно заметно на фоне словарей, которые начиная с Python 3.7 сохраняют порядок вставки ключей. Если дальнейшая логика опирается на позицию элементов, прямое использование множества становится проблемой.
Один из практических вариантов – сохранять порядок отдельно от множества. Например, сначала получить список ключей или значений в нужной последовательности, а затем использовать множество только для проверок уникальности или принадлежности. Такой подход разделяет задачи хранения порядка и логических операций.
Для случаев, когда требуется и уникальность, и контроль последовательности, можно формировать список с устранением повторов вручную, отслеживая уже добавленные элементы через вспомогательное множество. В этом сценарии set используется как служебная структура, а итоговые данные остаются упорядоченными.
Если данные планируется сравнивать или объединять, порядок чаще всего не играет роли, и потеря последовательности не влияет на корректность результата. Важно заранее определить, используется ли порядок как часть бизнес-логики, чтобы выбрать подходящий способ преобразования словаря в множество или комбинацию структур данных.
Вопрос-ответ:
Почему при вызове set() от словаря в множество попадают только ключи?
Словарь при итерации проходит по ключам, а функция set() принимает любой итерируемый объект. Поэтому выражение set(my_dict) работает так же, как set(my_dict.keys()). Это поведение зафиксировано в языке и не зависит от версии Python, начиная с самых ранних реализаций.
Как получить множество значений словаря, если среди них есть повторы?
Для этого используется метод values(), результат которого передаётся в set(). Повторяющиеся значения автоматически отбрасываются. Такой способ часто применяют при анализе справочников или параметров, где разные ключи указывают на одинаковые данные.
Почему возникает ошибка TypeError при создании множества из значений словаря?
Ошибка появляется, когда значения словаря относятся к не хешируемым типам, например спискам или вложенным словарям. Множество может хранить только неизменяемые объекты, поэтому перед добавлением такие значения нужно преобразовать, например заменить список на кортеж или извлечь отдельные элементы.
Можно ли создать множество из пар ключ-значение и для каких задач это подходит?
Да, для этого применяется преобразование set(my_dict.items()). Каждый элемент такого множества представляет собой кортеж из ключа и значения. Этот подход используют для сравнения словарей, поиска различий между версиями данных и проверки совпадений содержимого.
Как сохранить порядок данных, если нужно использовать множество?
Само множество порядок не сохраняет, поэтому его используют как вспомогательную структуру. Распространённый приём — хранить упорядоченный список элементов и параллельно поддерживать множество для проверки уникальности. Это позволяет контролировать последовательность без отказа от операций, которые удобно выполнять через set().
Чем отличается set(dict.values()) от set(dict.items()) и как выбрать подходящий вариант?
set(dict.values()) создаёт множество только из значений словаря и подходит для задач проверки уникальности данных без учёта ключей. В таком наборе теряется информация о том, какому ключу принадлежало значение. set(dict.items()) формирует множество кортежей вида (ключ, значение), что сохраняет связь между элементами и позволяет сравнивать словари целиком или искать точные совпадения пар. Выбор варианта зависит от того, требуется ли учитывать соответствие ключа и значения или достаточно работать с самими значениями.