Содержание статьи

Gini impurity – это показатель неоднородности выборки, используемый в алгоритмах классификации, особенно в деревьях решений. Он вычисляется по формуле G = 1 — Σ(p_i²), где p_i – доля объектов класса i в узле. Значение колеблется от 0 для полностью однородной группы до почти 1 для максимально смешанной выборки.
На практике Gini impurity помогает определить, какое разбиение данных обеспечивает наибольшую чистоту классов. Например, при анализе клиентов банка по уровню риска кредитования, минимизация Gini impurity позволяет выделять группы с однородным уровнем дефолта, что повышает точность модели.
При построении дерева решений узел с минимальной Gini impurity выбирается как оптимальный для разделения данных. Это означает, что алгоритм ищет такие признаки и пороговые значения, которые максимально разделяют классы. Использование Gini impurity ускоряет выбор разбиений по сравнению с альтернативными метриками, такими как энтропия, особенно на больших наборах данных.
Gini impurity легко интегрировать в модели машинного обучения: большинство библиотек, включая scikit-learn, предоставляют встроенные функции для расчета и оптимизации. Практическая рекомендация – проверять распределение классов перед применением, так как сильный дисбаланс может исказить значение Gini и привести к неверным разбиениям.
Определение Gini impurity и формула расчета
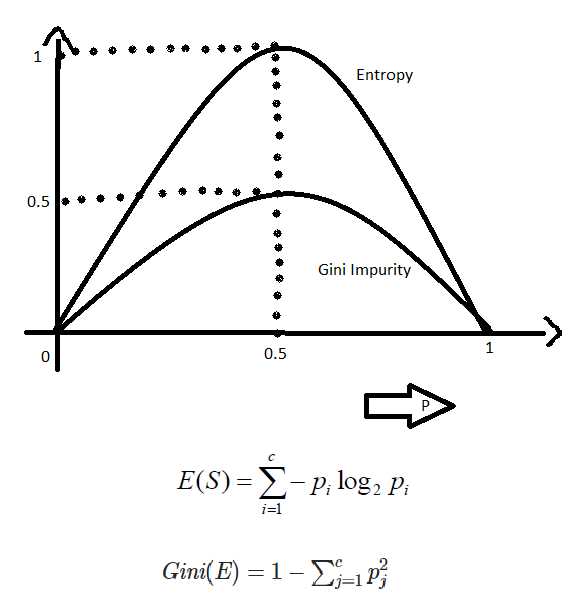
Gini impurity измеряет вероятность ошибочной классификации случайного объекта из выборки, если присвоить его класс на основе распределения в узле. Для узла с K классами формула выглядит так:
G = 1 — Σ(p_i²), где p_i – доля объектов класса i в узле, Σ – суммирование по всем классам.
Пример расчета на конкретных данных:
| Класс | Количество объектов | Доля (p_i) | p_i² |
|---|---|---|---|
| A | 40 | 0.4 | 0.16 |
| B | 30 | 0.3 | 0.09 |
| C | 30 | 0.3 | 0.09 |
Суммируем квадраты долей: 0.16 + 0.09 + 0.09 = 0.34. Тогда Gini impurity узла равна 1 — 0.34 = 0.66. Значение 0.66 указывает на высокую неоднородность выборки, что подсказывает алгоритму необходимость дальнейшего разбиения.
Рекомендация: для оценки качества разбиений в деревьях решений использовать Gini impurity совместно с количеством объектов в узле, чтобы избежать переоценки значимости маленьких групп.
Пример расчета Gini impurity на конкретных данных

Для наглядного расчета Gini impurity рассмотрим выборку клиентов банка, классифицированных по вероятности дефолта:
- Класс «Высокий риск» – 50 человек
- Класс «Средний риск» – 30 человек
- Класс «Низкий риск» – 20 человек
Общее количество объектов в узле: 50 + 30 + 20 = 100.
Доли классов рассчитываются как отношение числа объектов класса к общему числу:
- pВысокий = 50 / 100 = 0.5
- pСредний = 30 / 100 = 0.3
- pНизкий = 20 / 100 = 0.2
Далее возводим доли в квадрат и суммируем:
- 0.5² = 0.25
- 0.3² = 0.09
- 0.2² = 0.04
Сумма квадратов: 0.25 + 0.09 + 0.04 = 0.38
Расчет Gini impurity:
G = 1 — 0.38 = 0.62
Значение 0.62 отражает значительную неоднородность выборки. Рекомендация: на основании этого показателя алгоритм дерева решений выберет разбиение по признаку, который максимально уменьшает Gini impurity в дочерних узлах.
Использование Gini impurity при построении деревьев решений

В алгоритмах деревьев решений Gini impurity применяется для выбора оптимальных разбиений на каждом узле. Алгоритм оценивает все возможные признаки и пороговые значения, рассчитывая Gini impurity для каждого варианта разбиения.
Пример: при классификации клиентов банка по вероятности дефолта рассматривается признак «Доход». Узел с клиентами, доход которых меньше 50 000, содержит 40 высокорисковых и 10 низкорисковых клиентов. Узел с доходом выше 50 000 содержит 10 высокорисковых и 40 низкорисковых клиентов.
Расчет Gini impurity для левого узла:
G = 1 — ((40/50)² + (10/50)²) = 1 — (0.64 + 0.04) = 0.32
Для правого узла:
G = 1 — ((10/50)² + (40/50)²) = 0.32
Среднее значение после разбиения учитывает количество объектов в каждом узле, что позволяет оценить чистоту всего разбиения. Выбор признака с минимальным средним Gini impurity повышает однородность дочерних узлов и точность классификации.
Рекомендация: при больших наборах данных предварительно проверять распределение классов и избегать признаков с низкой вариативностью, так как они дают малое снижение Gini impurity и не улучшают структуру дерева.
Сравнение Gini impurity с энтропией в машинном обучении
Gini impurity и энтропия – два показателя качества разбиений в деревьях решений. Gini измеряет вероятность ошибки случайного выбора класса, тогда как энтропия оценивает среднюю информацию, необходимую для правильной классификации.
Формула энтропии: H = -Σ(p_i * log₂(p_i)), где p_i – доля объектов класса i. Для однородного узла обе метрики стремятся к минимальному значению, для полностью смешанной выборки Gini близка к 1 — 1/K, а энтропия растет до log₂(K).
Пример: узел с 70 объектами класса A и 30 объекта класса B.
Gini impurity: 1 — (0.7² + 0.3²) = 1 — (0.49 + 0.09) = 0.42
Энтропия: — (0.7 * log₂0.7 + 0.3 * log₂0.3) ≈ 0.881
Рекомендация: для больших выборок и задач с выраженными доминирующими классами предпочтительно использовать Gini impurity из-за меньших вычислительных затрат, при сбалансированных классах можно рассматривать энтропию для более точной оценки разделений.
Влияние Gini impurity на выбор оптимального разбиения
При построении дерева решений алгоритм оценивает все возможные разбиения по каждому признаку и выбирает то, которое минимизирует среднее Gini impurity дочерних узлов. Это обеспечивает максимальное разделение классов и повышает однородность групп.
Пример: выбор порога по признаку «Возраст» для классификации клиентов на группы с высоким и низким риском дефолта. Узел с клиентами младше 35 лет содержит 20 высокорисковых и 5 низкорисковых клиентов. Узел старше 35 лет – 30 высокорисковых и 45 низкорисковых.
Расчет Gini impurity:
Левый узел: 1 — ((20/25)² + (5/25)²) = 1 — (0.64 + 0.04) = 0.32
Правый узел: 1 — ((30/75)² + (45/75)²) = 1 — (0.16 + 0.36) = 0.48
Среднее взвешенное: (25/100)*0.32 + (75/100)*0.48 = 0.44
Рекомендация: выбирать разбиения с минимальным взвешенным Gini impurity. Если несколько разбиений дают близкие значения, стоит дополнительно учитывать размер узлов и стабильность признаков, чтобы избежать переобучения.
Ошибки и ограничения при применении Gini impurity
Gini impurity чувствительна к дисбалансу классов. В узлах с сильным преобладанием одного класса незначительное присутствие меньшей группы почти не влияет на значение метрики, что может привести к пропуску полезных разбиений.
Пример: узел с 90 объектами класса A и 10 объектами класса B. Разбиение, полностью выделяющее объекты класса B в отдельный узел, уменьшит Gini лишь немного, и алгоритм может проигнорировать это разбиение, теряя точность классификации редкого класса.
Другой риск – использование признаков с множеством уникальных значений. Такие признаки создают малые узлы, что снижает Gini impurity, но повышает вероятность переобучения.
Рекомендации:
- Проверять баланс классов и при необходимости использовать методы коррекции, например, взвешивание или oversampling.
- Контролировать размер узлов, чтобы маленькие группы не доминировали в оценке разбиений.
- Сравнивать результаты с другими метриками, например энтропией, для оценки чувствительности к дисбалансу и множеству уникальных значений признаков.
Вопрос-ответ:
Что такое Gini impurity и для чего она нужна в машинном обучении?
Gini impurity — это показатель неоднородности узла в деревьях решений. Он показывает вероятность того, что случайно выбранный объект будет ошибочно классифицирован, если присвоить ему класс согласно распределению в узле. Чем ниже значение Gini impurity, тем более однороден узел. Используется для выбора признаков и порогов разбиения, которые лучше всего разделяют классы и повышают точность модели.
Как рассчитать Gini impurity на примере конкретных данных?
Для расчета берут долю каждого класса в узле, возводят в квадрат и суммируют. Затем результат вычитают из 1. Например, если в узле 40 объектов класса A, 30 класса B и 30 класса C, доли будут 0.4, 0.3 и 0.3, квадраты 0.16, 0.09 и 0.09. Сумма 0.34, Gini impurity = 1 — 0.34 = 0.66. Это число отражает неоднородность выборки.
В чем отличие Gini impurity от энтропии при построении деревьев решений?
Обе метрики оценивают неоднородность узла, но Gini impurity быстрее вычисляется и чувствительна к преобладанию одного класса. Энтропия учитывает среднее количество информации, необходимое для классификации, и более чувствительна к узлам с близкими по размеру классами. На практике Gini чаще используется для больших наборов данных, а энтропия — при равномерном распределении классов.
Как значение Gini impurity влияет на выбор оптимального разбиения узла?
Алгоритм дерева решений вычисляет Gini impurity для всех возможных разбиений и выбирает то, где среднее значение в дочерних узлах минимально. Меньшее значение означает более однородные группы, что улучшает классификацию. Например, при разделении клиентов по доходу выбирается порог, который минимизирует Gini в обоих узлах, учитывая число объектов в каждой группе.
Какие ошибки могут возникнуть при использовании Gini impurity и как их избежать?
Основные ошибки связаны с дисбалансом классов и признаками с множеством уникальных значений. В сильно несбалансированных узлах редкие классы могут игнорироваться, а признаки с большим количеством уникальных значений создают мелкие узлы, повышая риск переобучения. Рекомендуется контролировать размер узлов, балансировать классы и проверять разбиения с другими метриками, например энтропией.
Как Gini impurity помогает в построении дерева решений и на что обратить внимание при её использовании?
Gini impurity оценивает неоднородность узла, показывая вероятность ошибки при случайном выборе класса на основе распределения объектов. В деревьях решений алгоритм выбирает разбиение, которое минимизирует среднее значение Gini в дочерних узлах, создавая более однородные группы. При использовании важно учитывать дисбаланс классов: если один класс преобладает, мелкие группы могут быть проигнорированы, что снижает точность. Также следует контролировать размер узлов при признаках с множеством уникальных значений, чтобы избежать создания маленьких узлов, ведущих к переобучению. Для проверки корректности разбиений можно сравнивать результаты с другими метриками, например, с энтропией, и корректировать распределение классов при необходимости.