
Содержание статьи

При работе с несколькими узлами приложение сталкивается с расхождениями в состоянии данных. Для устранения таких ситуаций используется специализированный компонент, отвечающий за согласование записей, контроль последовательности операций и обмен служебной информацией между серверами.
Этот компонент фиксирует порядок изменений через логи операций, распределённые версии объектов или механизмы векторных меток. Такой подход позволяет определить источник конфликта, восстановить цепочку действий и сохранить корректное состояние даже при временной изоляции узлов.
Репликация настраивается с учётом характера нагрузки: однонаправленная передача подходит для систем с доминирующим центральным узлом, а двунаправленный обмен применяется там, где данные изменяются на каждом узле. При выборе схемы учитываются задержки сети, объём обновлений и вероятность одновременных записей.
При длительной работе распределённой системы важно контролировать метаданные: версии объектов, состояние подключений, очереди отправки и подтверждения. Точная фиксация служебных показателей даёт возможность вовремя обнаружить отставание узла, избыточный рост журнала операций или сбой репликации.
Настройка роли координатора для распределённого хранения

Роль координатора определяет, какой узел управляет последовательностью операций, отвечает за выбор лидера и фиксирует ключевые изменения в распределённых наборах данных. Для корректной работы требуется жёсткая регламентация правил выбора координатора, его приоритетов и механизмов переключения.
Перед назначением координатора необходимо определить параметры, влияющие на стабильность кластера:
- логический идентификатор узла, исключающий пересечения при перезапусках;
- очередность участия узлов в голосовании;
- источник синхронизации времени;
- границы допустимой задержки отклика;
- условия перевода роли координатора на другой узел.
Процесс назначения координатора обычно опирается на протоколы выбора лидера. При настройке необходимо проверить параметры, которые формируют устойчивость решения:
- значение таймаута выборов и его пропорцию к сетевой задержке;
- количество голосующих узлов, участвующих в подтверждении выбранного лидера;
- условия, при которых узел отказывается от роли координатора при снижении производительности или потере связи.
На уровне конфигурации важно указать источники журналирования. Координатор должен фиксировать все решения, влияющие на состояние данных. Журналы рекомендуется распределять по отдельным носителям, чтобы исключить потери при сбоях.
После первичной настройки выполняется проверка сценариев переключения роли. Для этого запускаются тесты сетевых разрывов, задержек и перегрузок. Цель – убедиться, что передача роли происходит контролируемо и без расхождений в данных.
Механизм согласования изменений между узлами

Для синхронизации изменений между узлами требуется фиксированная схема обмена сообщениями, где каждый шаг строго определён. Компонент должен поддерживать журналы операций с монотонно увеличивающимися версиями, чтобы исключить неоднозначность при обработке обновлений.
При передаче изменений узел отправляет пакет с идентификатором операции, хэшем содержимого и временной меткой. Получатель сверяет данные с локальным журналом, определяет необходимость применения и формирует ответ с подтверждением или отказом. Это снижает риск несогласованных состояний при высоких нагрузках.
Для ускорения согласования рекомендуется использовать протоколы с минимальным числом раундов обмена. В системах с большим числом узлов подходящим вариантом становится модель с лидером, который фиксирует порядок операций и распространяет согласованную последовательность. В небольших кластерах можно применять многослойные алгоритмы голосования, где каждый участник проверяет корректность изменений локально.
Для контроля расхождений требуется периодическая сверка хэшей сегментов данных. Если обнаружено отклонение, узлы запрашивают недостающие операции из журнала друг друга и выполняют восстановление состояния. Это позволяет уменьшить объём передаваемых данных и ускорить исправление ошибок.
Обработка конфликтов при одновременной записи данных
Для корректной работы распределённого хранилища компонент должен фиксировать точный порядок операций. Это достигается за счёт применения логических меток версии, генерируемых каждым узлом при изменении набора данных. Узлы сравнивают версии и определяют, какое изменение считать актуальным.
Если два узла отправляют несовместимые обновления, компонент использует заранее выбранный алгоритм разрешения. На практике применяются три подхода: приоритет источника, сравнение меток версии или анализ содержимого записи. Выбор механизма зависит от характера данных и допустимого уровня расхождений.
Дополнительный уровень контроля обеспечивается хранением журнала операций. Узлы могут повторно воспроизвести последовательность изменений и восстановить корректное состояние. При обнаружении несовпадений компонент отправляет запрос на согласование и ожидает подтверждение от всех активных участников.
Для повышения предсказуемости обновлений администратор задаёт правила отклонения конфликтных записей. Например, можно блокировать изменения при устаревшей версии или ограничивать допустимое расстояние между метками. Такие ограничения снижают риск некорректного объединения данных.
Выбор стратегии репликации для разных типов нагрузки
Стратегия репликации определяется характеристиками запросов, допустимыми задержками и объёмом операций записи. Компонент должен поддерживать несколько режимов, позволяя переключаться между ними без остановки обслуживания.
Для систем с преобладанием чтения подходит асинхронная модель. Узлы получают обновления с задержкой, что снижает нагрузку на координатор. Такой вариант применяют при аналитических выборках или кэширующих слоях.
При высоком количестве транзакций записи используется синхронный режим. Координатор передаёт данные на несколько узлов и ждёт подтверждения. Этот метод минимизирует риск расхождений, но увеличивает задержку отклика. Его выбирают для финансовых операций и задач с требованием строгой последовательности.
- Для распределённых очередей и журналов подходит модель «leader–follower», где лидер фиксирует изменения, а остальные узлы повторяют их в исходном порядке.
- При географически удалённых центрах обработки данных используют каскадную репликацию, уменьшающую нагрузку на главный узел.
- В системах с непостоянной нагрузкой целесообразно применять адаптивную стратегию, при которой компонент увеличивает или сокращает число целей репликации в зависимости от текущего потока запросов.
Перед выбором схемы необходимо оценивать интервалы обновлений, чувствительность к задержкам и вероятность конфликтов. Компонент должен фиксировать метрики пропускной способности, времени ответа и количества пересинхронизаций, чтобы корректировать параметры репликации без ручного вмешательства.
Контроль целостности данных при передаче между узлами
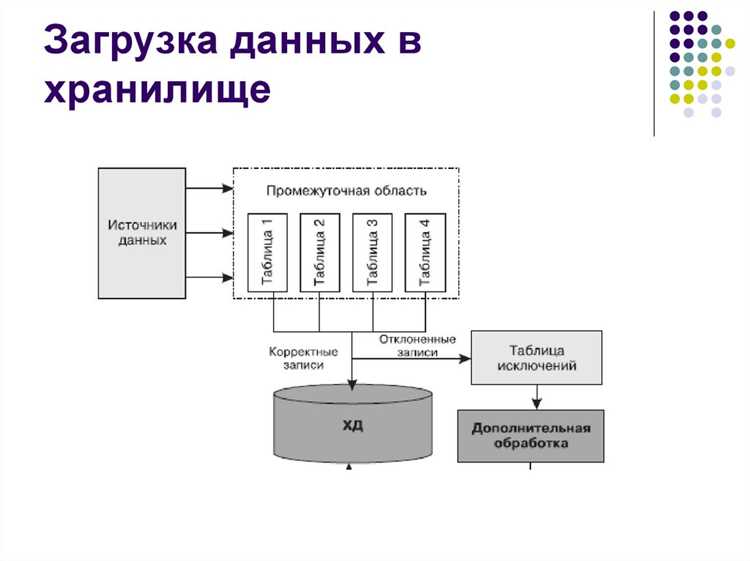
Компонент, отвечающий за перемещение данных между узлами, должен проверять каждый пакет с помощью предсказуемых и воспроизводимых механизмов. На практике применяют контрольные суммы, сравнение версий и проверку структурированных форматов перед записью в хранилище получателя.
Для оценки точности передачи используют несколько уровней проверки. Минимальный набор включает вычисление хешей, сверку длины полезной нагрузки и подтверждение от получающего узла. В распределённой среде такая схема снижает риск накопления повреждённых сегментов.
| Метод проверки | Назначение | Применение |
|---|---|---|
| CRC32 | Выявление искажений в небольших блоках | Пакетная передача между соседними узлами |
| SHA-256 | Проверка неизменности содержимого | Передача крупных сегментов, репликация |
| Сравнение версии | Определение актуальности данных | Финальная проверка перед записью |
При построении схемы контроля рекомендуется выделять отдельный канал для служебных пакетов, чтобы подтверждения не конкурировали с пользовательскими запросами. Такое разделение помогает снизить задержки при высоком уровне сетевого трафика.
Дополнительная проверка структуры полезной нагрузки нужна при передаче сериализованных объектов. Несоответствие схемы или нарушение порядка полей фиксируется до десериализации, что позволяет избежать повреждения локального хранилища.
Организация кэширования с учётом распределённой структуры

Рекомендации по организации кэширования:
- Локальные кэши на узлах: хранят часто используемые данные для минимизации сетевых запросов. Используйте TTL (time-to-live) для автоматического обновления устаревших записей.
- Распределённые кэши: применяются для совместного использования данных между узлами. Рассмотрите решения на основе Redis или Memcached с поддержкой кластеризации.
- Инвалидация кэша: реализуется через уведомления от координатора о изменениях данных. Это позволяет избежать устаревшей информации и уменьшить вероятность конфликтов.
- Политики обновления: используйте стратегию write-through для синхронизации записей при изменении данных или write-back для уменьшения нагрузки на основной хранилище.
Пример распределённой кэш-схемы:
| Компонент | Роль | Пример реализации |
|---|---|---|
| Локальный кэш узла | Снижение задержки доступа | Guava Cache, Caffeine |
| Распределённый кэш | Согласованное хранение данных между узлами | Redis Cluster, Memcached |
| Координатор | Управление инвалидацией и синхронизацией | Custom service с уведомлениями через pub/sub |
Организация кэширования с учётом распределённой структуры позволяет уменьшить нагрузку на сеть, ускорить отклик приложений и снизить вероятность чтения устаревших данных.
Мониторинг состояния узлов и обработка отказов
Для поддержания целостности распределённого хранилища критически важно отслеживать состояние каждого узла и оперативно реагировать на сбои. Система должна фиксировать как полные отказы, так и частичные деградации функциональности.
Рекомендации по мониторингу и обработке отказов:
- Регулярные heartbeat-проверки: узлы отправляют сигналы о своём состоянии через заданные интервалы. Использование алгоритмов quorum позволяет определить недоступность узла без ложных срабатываний.
- Логирование и метрики: собирайте данные о задержках, пропускной способности и частоте ошибок. Инструменты Prometheus или Grafana обеспечивают визуализацию и оповещения.
- Автоматическое переключение ролей: при обнаружении сбоя координатор переназначает лидера или реплики для обеспечения непрерывности работы.
- Восстановление данных: после выхода узла из состояния отказа выполняется синхронизация изменённых данных с другими узлами для восстановления актуального состояния.
- Политики повторных попыток и таймауты: определяют, как долго система ожидает отклика от узла и сколько повторов разрешено перед пометкой его как недоступного.
Комплексный мониторинг и чётко настроенные процедуры обработки отказов позволяют минимизировать потерю данных и обеспечивают стабильную работу распределённого компонента приложения даже при частичных сбоях инфраструктуры.
Интеграция компонента с сервисами приложения через API
Для взаимодействия распределённого компонента с другими сервисами приложения необходим чётко определённый API. Он обеспечивает доступ к данным, управление репликацией и мониторинг состояния узлов без нарушения целостности системы.
Рекомендации по интеграции через API:
- REST или gRPC: выбирайте протокол в зависимости от требований к скорости и объёму данных. gRPC подходит для высоконагруженных систем с бинарными данными, REST удобен для совместимости и отладки.
- Методы CRUD с распределённой логикой: каждая операция записи должна учитывать согласование между узлами, а чтение – приоритет локальной или ближайшей реплики для снижения задержки.
- Аутентификация и авторизация: применяйте токены или сертификаты для защиты API от несанкционированного доступа и предотвращения конфликтов между сервисами.
- Версионирование API: сохраняет совместимость с существующими сервисами при расширении функциональности компонента или изменении формата данных.
- Обработка ошибок и повторные попытки: сервисы должны корректно реагировать на временную недоступность узлов и получать ответы о состоянии транзакций для предотвращения неконсистентности.
Продуманная интеграция через API позволяет использовать распределённый компонент как единый интерфейс для всех сервисов приложения, ускоряет доступ к данным и поддерживает согласованность информации при одновременной работе нескольких сервисов.
Вопрос-ответ:
Что делает компонент управления распределёнными данными в приложении?
Компонент отвечает за согласованное хранение и обмен данными между несколькими узлами. Он обеспечивает репликацию, обработку конфликтов при одновременных изменениях и поддерживает актуальность информации на всех серверах.
Как настроить координатор для распределённого хранения?
Координатор управляет распределением данных и синхронизацией между узлами. Настройка включает выбор лидера, установку heartbeat-интервалов для проверки состояния узлов, настройку очередей для записи изменений и распределение нагрузки между репликами.
Какие стратегии репликации лучше использовать для разных типов нагрузки?
Для часто читаемых данных подойдёт асинхронная репликация с несколькими копиями, чтобы снизить задержки. Для критичных данных с высокой частотой обновлений лучше применять синхронную репликацию, чтобы изменения фиксировались на всех узлах одновременно.
Как интегрировать компонент с другими сервисами приложения через API?
Интеграция предполагает использование REST или gRPC интерфейсов для доступа к данным и управлению их репликацией. Необходимо внедрить аутентификацию, обработку ошибок и повторные попытки при недоступности узлов, а также версионирование API для поддержки совместимости при изменении формата данных.





