Содержание статьи

В модуле string присутствует готовая константа punctuation, содержащая полный перечень символов, которые интерпретируются как знаки пунктуации: от стандартных точек и запятых до специальных знаков вроде @ или #. Этот набор упрощает разбор текстов, поскольку исключает необходимость вручную перечислять каждый символ.
При работе с пользовательскими данными константа помогает быстро выявлять лишние символы, выделять структурные части строки или готовить текст для последующей обработки. Полезно заранее определиться, какие знаки требуется оставить, а какие – исключить, чтобы избежать искажений данных.
Чаще всего punctuation применяют при очистке входных сообщений, создании фильтров для текстовых полей, генерации токенов или подготовке строк к регулярным выражениям. Константа легко комбинируется с методами строк, генераторами списков и функциями валидации, что делает её удобным инструментом для задач, связанных с контролем структуры текстов.
Python string punctuation: что это и как использовать

Константа string.punctuation представляет собой строку из 32 символов, включающих точку, запятую, тире, скобки, кавычки, символы валют и знаки, применяемые в технических протоколах. Набор формируется разработчиками Python и соответствует ASCII-пунктуации.
При обработке текста этот список используют для фильтрации, классификации и преобразования данных. Он удобен тем, что его можно подключить одной строкой и сразу применять в проверках и итерациях без ручного перечисления каждого символа.
- Проверка наличия пунктуации в строке через выражения вида char in string.punctuation.
- Создание фильтрующего списка или генератора для подготовки входных данных к токенизации.
- Комбинация с методами replace, translate и таблицами трансляции для удаления или замены отдельных символов.
- Использование в регулярных выражениях для точной настройки шаблонов и избежания ошибок при ручном наборе классов символов.
Перед применением полезно определить допустимые символы, чтобы не удалить критичные элементы, например дефисы в телефонных номерах или двоеточия в временных метках. Для таких случаев создают собственные списки путём расширения или сокращения базового набора punctuation.
Получение набора punctuation из модуля string

Модуль string предоставляет константу punctuation, содержащую полный перечень ASCII-знаков пунктуации. Доступ к ней открывается после простой операции импорта: from string import punctuation. Переменная представляет собой строку, которую можно сразу использовать в проверках, циклах и функциях очистки данных.
Для диагностики состава набора удобно вывести его в консоль или применить к нему операции сортировки и преобразования в множество, когда требуется устранить дубли и ускорить поиск. При подготовке собственных правил текста допускается создавать комбинированные наборы, объединяя punctuation с дополнительными символами через конкатенацию строк.
Проверка символов строки на принадлежность punctuation
Определение того, относится ли символ к пунктуации, сводится к сравнению каждого элемента строки с набором string.punctuation. Условие вида if char in punctuation подходит для поэлементного анализа текста и позволяет точно выделять нужные позиции.
Для последовательной проверки используют циклы или генераторы, чтобы получать список индексов, подлежащих обработке. Это упрощает задачи, связанные с удалением или подсчётом знаков, поскольку дальнейшие операции можно выполнять только над обнаруженными элементами.
Если требуется анализ больших объёмов данных, стоит преобразовать строку punctuation в множество. Операция set(punctuation) ускоряет поиск за счёт хеш-структуры, что особенно полезно при потоковой обработке входных сообщений.
Удаление знаков пунктуации из текста с помощью строковых методов
Для удаления пунктуации из строки подходят базовые методы Python, поскольку каждый из них позволяет контролировать набор исключаемых символов. Чаще всего используют конструкции с последовательной заменой, основанные на переборе элементов string.punctuation.
Метод replace применяют для точечного удаления символов. Его удобно использовать при работе с небольшими списками, когда требуется исключить только часть знаков. Цикл вида for char in punctuation: text = text.replace(char, «») формирует очищенную строку без внесения дополнительных структур.
Метод translate подходит для более плотной обработки. Таблица трансляции создаётся через str.maketrans(«», «», punctuation), после чего text.translate(…) удаляет все символы набора за одну операцию. Такой подход снижает количество проходов по строке и удобен при работе с длинными сообщениями.
Фильтрация пунктуации через генераторы списков и join
Генераторы списков позволяют формировать новую строку путём отбора только тех символов, которые отсутствуют в string.punctuation. Такой подход исключает лишние проходы и даёт полный контроль над логикой фильтрации.
Конструкция вида «».join([ch for ch in text if ch not in punctuation]) создаёт последовательность символов, минуя каждый элемент набора punctuation. Полученный результат подходит для последующей токенизации, разметки или сравнения строк.
Если требуется оставить часть знаков, например дефисы или двоеточия, создаётся локальный список исключений. Затем условие фильтрации расширяется проверкой вида ch not in punctuation or ch in allowed, что даёт возможность строить собственные правила обработки текста.
Использование регулярных выражений для обработки punctuation

Регулярные выражения позволяют быстро находить и удалять или заменять любые знаки пунктуации в строках. Для этого используют шаблон [{}], куда подставляют символы из string.punctuation. Пример: re.sub(r»[{}]+».format(re.escape(punctuation)), «», text) удаляет все указанные знаки.
Метод re.findall помогает подсчитать количество каждого знака, а re.split – разбить текст на сегменты без вмешательства в слова. Использование re.escape гарантирует, что специальные символы, такие как *, +, ?, будут корректно интерпретированы.
Регулярные выражения особенно полезны при обработке больших объёмов данных или сложных текстов с разнообразной пунктуацией, поскольку позволяют управлять удалением, заменой и извлечением знаков в одной компактной операции.
Нормализация пользовательского ввода путём исключения punctuation

Исключение знаков пунктуации из пользовательского ввода помогает стандартизировать данные для хранения, поиска и анализа. Это особенно важно для форм, чат-ботов и систем поиска, где наличие лишних символов может нарушить логику обработки.
Практические шаги по нормализации:
- Преобразовать строку в нижний регистр для унификации текста.
- Удалить все символы из string.punctuation с помощью генераторов списков, translate или регулярных выражений.
- Оставить критичные знаки через фильтры или списки разрешённых символов.
- Очистить лишние пробелы после удаления знаков с помощью strip() и split/join для нормализации интервалов.
- Проверить результат на наличие специальных символов, не входящих в ASCII, если система требует строгого соответствия формату.
Такая последовательность действий позволяет получить чистый и предсказуемый ввод, снижает вероятность ошибок при хранении данных и повышает точность поиска или сравнения строк.
Создание пользовательского набора punctuation для специальных задач

Стандартный набор string.punctuation может быть слишком широким для отдельных задач, например при обработке форматов кода, номеров телефонов или хештегов. В таких случаях создают кастомный список знаков для точной фильтрации.
Пример формирования пользовательского набора:
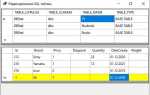
| Задача | Допустимые символы | Исключаемые символы |
|---|---|---|
| Очистка текста для токенизации | Все буквы и цифры | Все знаки из string.punctuation |
| Номера телефонов | + и — | Запятые, точки, скобки |
| Обработка хештегов | # | Вся остальная пунктуация |
| Кодовые строки или лог-файлы | {}, [], :, ; | Кавычки, точки, запятые |
Для применения создают новую строку или множество, комбинируя базовую punctuation с добавочными символами или исключая лишние. Далее используют стандартные методы очистки: translate, генераторы списков или регулярные выражения, опираясь на кастомный набор.