Количество абзацев в документе напрямую влияет на читаемость и структуру текста. В среднем текстовый документ объёмом 3–5 тысяч слов содержит от 150 до 250 абзацев, если каждый абзац составляет 15–20 предложений. Для аналитических и научных материалов этот показатель снижается до 80–120 абзацев на тот же объём, чтобы сохранить логическую связность и глубину изложения.
Подсчёт абзацев можно выполнять различными способами. В простейшем варианте используется разделение по символу переноса строки, что позволяет быстро определить количество логических блоков. Более точный метод включает анализ структуры текста с учётом заголовков, списков и цитат, поскольку стандартное деление на перенос строки может не учитывать вложенные элементы и объединённые параграфы.
Для больших документов оптимально использовать автоматизированные инструменты. Например, текстовые редакторы и специализированные утилиты позволяют учитывать форматирование и скрытые символы, что повышает точность подсчёта. Рекомендуется сохранять промежуточные результаты подсчёта и проверять их выборочно вручную, чтобы исключить ошибки, связанные с нестандартной разметкой или несоблюдением стилевых правил.
Правильный подсчёт абзацев помогает не только оценивать объём текста, но и планировать структуру, распределять информационные блоки и поддерживать единый ритм повествования. При редактировании документа аналитики и редакторы используют эти данные для оптимизации читабельности и согласования с требованиями издателей или внутренних стандартов компаний.
Как определить абзац в разных текстовых редакторах
В Microsoft Word абзац формируется нажатием клавиши Enter. Его границы определяются маркерами ¶, которые можно включить через вкладку «Главная» → «Отображение всех символов». Каждый абзац имеет собственные форматирования: отступ первой строки, межстрочный интервал и выравнивание.
В LibreOffice Writer абзац также создаётся клавишей Enter. Отличие в том, что Writer позволяет визуально определить абзац по отступам и границам рамок. Через меню «Формат» → «Абзац» можно просмотреть настройки отступов и интервалов, что помогает точнее идентифицировать отдельные блоки текста.
В Google Docs абзац отделяется клавишей Enter, а разрывы строк без создания нового абзаца реализуются сочетанием Shift+Enter. Системные маркеры ¶ отсутствуют, поэтому для проверки границ абзаца рекомендуется использовать линейку и панель форматирования для анализа отступов и интервалов.
В текстовых редакторах для программирования, таких как Visual Studio Code или Sublime Text, абзац определяется последовательностью строк без пустых строк между ними. Пустая строка выступает явным разделителем. Для точного подсчёта абзацев можно использовать поиск регулярных выражений, например, \n\s*\n для поиска двойных переносов строк.
В Notepad++ абзац определяется так же, как и в редакторах кода: пустая строка служит границей. В меню «Вид» → «Отображать символы» можно включить показ символов конца строки, что облегчает визуальное определение абзацев.
При работе с PDF-документами абзац определяется визуально по отступу первой строки и промежутку между блоками текста, так как стандартных маркеров ¶ нет. Для анализа структуры текста удобно использовать инструменты конвертации PDF в редактируемый формат, например Word или LibreOffice, где абзацы становятся явно видимыми.
Использование встроенных функций подсчёта абзацев
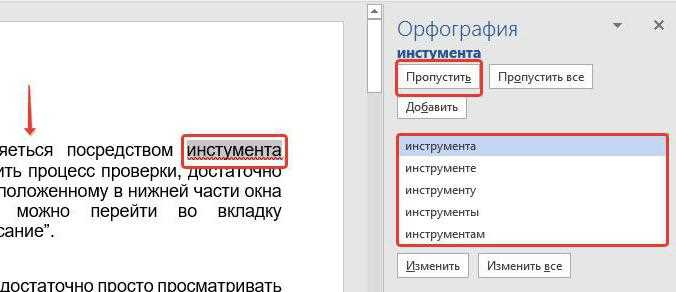
Современные текстовые редакторы и библиотеки программного обеспечения предоставляют встроенные методы для точного подсчёта абзацев, что позволяет избежать ошибок, связанных с ручным анализом текста.
В Microsoft Word функция Paragraphs.Count возвращает количество абзацев в документе. Она учитывает каждый отдельный символ конца абзаца, включая пустые строки, что важно при работе с форматированными документами.
В LibreOffice Writer аналогичная возможность реализована через API UNO. Метод getCount() объекта TextParagraphEnumeration позволяет получить число всех абзацев без необходимости обхода документа вручную.
Для программирования на Python с использованием библиотеки python-docx подсчёт абзацев осуществляется через свойство document.paragraphs. Пример:
- Импортировать библиотеку:
from docx import Document. - Загрузить документ:
doc = Document('example.docx'). - Получить количество абзацев:
len(doc.paragraphs).
Встроенные функции позволяют также фильтровать абзацы по содержимому или стилю. Например, в Word можно применять фильтры по стилям с помощью VBA:
- Фильтрация по заголовкам:
For Each para In ActiveDocument.Paragraphs If para.Style = "Heading 1" Then count = count + 1. - Учёт только непустых абзацев через проверку
Len(Trim(para.Range.Text)) > 0.
Использование встроенных методов обеспечивает:
- Высокую точность подсчёта вне зависимости от длины документа.
- Возможность автоматизации анализа большого объёма текстов.
- Фильтрацию по стилям и структуре документа без дополнительных библиотек.
Рекомендация: при работе с большими документами всегда проверять, как конкретное приложение трактует пустые абзацы, чтобы корректно интерпретировать результаты подсчёта.
Подсчёт абзацев через поиск и замену символов переноса строки
В большинстве текстовых редакторов поиск по символу переноса строки доступен через специальные коды: \n для LF и \r\n для CRLF. Для подсчёта абзацев необходимо заменить каждый перенос строки на уникальный маркер, например #ABZ#. После этого можно выполнить подсчёт количества этих маркеров с помощью функции «Найти» или «Подсчитать вхождения».
При работе с текстами, где абзацы разделяются двумя переводами строки подряд, необходимо учитывать двойные переносы как границы абзацев. В этом случае поиск и замена выполняется по шаблону \n\n или \r\n\r\n. Замена на маркер позволяет однозначно определить количество абзацев даже в длинных документах без необходимости вручную прокручивать текст.
Для автоматизации можно использовать скрипты на Python или PowerShell. В Python функция re.split(r'\n{2,}', text) разделяет текст на абзацы, учитывая несколько переносов подряд. Длина полученного списка элементов соответствует количеству абзацев.
Метод поиска и замены символов переноса строки подходит для текстов с однородной структурой, где абзацы не объединяются в рамках таблиц или списков. Он обеспечивает точный количественный результат и позволяет одновременно подготовить текст к последующей обработке или анализу.
Автоматизация подсчёта абзацев с помощью макросов и скриптов
Для автоматического подсчёта абзацев в документах можно использовать встроенные макросы в текстовых редакторах, таких как Microsoft Word или LibreOffice Writer. В Word макрос на VBA позволяет пройтись по коллекции Paragraphs и вывести точное число абзацев без учёта пустых строк:
Макросы сокращают время обработки больших файлов: при документе объёмом 500 страниц ручной подсчёт займёт часы, тогда как макрос выполнит подсчёт за доли секунды. Для повышения точности рекомендуется исключать абзацы, содержащие только пробелы или разрыв страницы.
Для LibreOffice Writer можно использовать Python-скрипты с UNO API. Скрипт подключается к документу, перебирает элементы текстового потока и учитывает только реальные текстовые абзацы, игнорируя таблицы и элементы форматирования. Такой подход удобен при пакетной обработке сотен файлов в формате .odt.
Автоматизация через скрипты также позволяет интегрировать подсчёт абзацев в рабочие процессы: например, генерировать отчёты о структуре документа, проверять соответствие редакционным стандартам или строить статистику по объёму текстов для аналитики.
Использование макросов и скриптов уменьшает вероятность ошибок при подсчёте и позволяет автоматизировать повторяющиеся задачи, что критично при работе с большими объёмами текста или при регулярной проверке множества документов.
Сравнение количества абзацев в нескольких документах

При сравнении нескольких документов важно учитывать не только общее число абзацев, но и их распределение по разделам. Например, текст с 120 абзацами, равномерно распределёнными по 10 разделам, воспринимается иначе, чем документ с 120 абзацами, но с концентрированными блоками по 30–40 абзацев.
Для точного анализа полезно подсчитать среднее количество абзацев на страницу или на стандартный блок текста. В документах объёмом 50–70 страниц нормой считается 2–3 абзаца на страницу, что обеспечивает удобочитаемость. Если один документ содержит 200 абзацев на 60 страниц, а другой – 120 абзацев на 40 страниц, плотность абзацев первого выше: 3,33 против 3,0.
Сравнение можно усилить с помощью выделения максимальных и минимальных блоков абзацев. Например, длинный раздел с 25 абзацами может сигнализировать о перегрузке информации, тогда как короткие разделы по 5–7 абзацев улучшают восприятие и структурирование.
Рекомендация при анализе нескольких документов – фиксировать не только общее число абзацев, но и их длину, распределение по разделам и плотность. Это позволяет выявить различия в структуре текста и выбрать оптимальный формат для дальнейшего редактирования или публикации.
Ошибки при ручном подсчёте абзацев и как их избежать
Основная ошибка при ручном подсчёте абзацев – отсутствие чёткого критерия их определения. Многие считают абзацем любой блок текста, разделённый переносом строки, однако в документах с нестандартным форматированием один абзац может занимать несколько строк или включать встроенные списки.
Пропуск абзацев возникает при использовании пустых строк только для визуального отделения. Если документ содержит строки с пробелами или табуляцией без текста, их легко принять за абзац или проигнорировать настоящий абзац. Рекомендуется проверять, содержит ли строка хотя бы один видимый символ, прежде чем её учитывать.
Дублирование подсчёта встречается при наличии многоуровневых списков и цитат. Например, если цитата разбита на несколько визуальных строк, ручной подсчёт может ошибочно увеличить количество абзацев. Чтобы избежать этого, следует считать только логически завершённые смысловые блоки.
Ошибки также возникают при смешанном использовании символов конца строки: Windows (CRLF) и Unix (LF). При ручном просмотре части абзацев могут быть объединены или разделены неправильно. Проверка формата документа с помощью текстового редактора с видимыми символами конца строки минимизирует эту проблему.
Для уменьшения ошибок полезно вести пометки при подсчёте, например, пронумеровывать каждый абзац на листе или в цифровой копии. Разделение документа на секции и подсчёт абзацев по отдельности снижает вероятность пропуска или дублирования.
Контрольные проверки через случайный повторный подсчёт части документа помогают выявить систематические ошибки и корректировать методику. Рекомендуется фиксировать критерии, по которым определяется абзац, чтобы одинаково учитывать текстовые блоки при повторных подсчётах.
Экспорт данных о количестве абзацев для анализа

Для анализа структуры текстового документа важно иметь возможность экспортировать данные о количестве абзацев в формате, удобном для статистической обработки. Наиболее распространённые форматы – CSV, JSON и XML. CSV позволяет быстро импортировать информацию в Excel или Google Sheets, JSON обеспечивает совместимость с Python, R и другими языками программирования для аналитики, XML подходит для интеграции с системами управления контентом.
При экспорте данных рекомендуется фиксировать не только количество абзацев, но и их порядковый номер, длину в символах и количество слов. Это позволяет строить динамические графики плотности текста, выявлять перегруженные абзацы и проводить сравнительный анализ разных документов. Например, для текста на 10 000 слов с 250 абзацами можно автоматически создать CSV со столбцами: № абзаца, количество слов, количество символов, тип абзаца (основной, цитата, список).
Инструменты для автоматического экспорта включают текстовые редакторы с макросами, Python-библиотеки (например, `docx`, `pandas`) и специализированные плагины для Word и LibreOffice. Процесс обычно состоит из трёх этапов: считывание документа, подсчёт абзацев с вычислением метрик, запись данных в выбранный формат. При этом важно корректно обрабатывать пустые абзацы и абзацы с нестандартными разделителями, чтобы не искажать статистику.
Для упрощения анализа можно добавлять метки по стилю или теме абзаца. В CSV это реализуется отдельным столбцом, в JSON – через объектные свойства. Такой подход позволяет быстро фильтровать абзацы, строить графики распределения длины текста и анализировать соотношение цитат и основного материала без ручной проверки.
Экспорт данных о количестве абзацев также полезен для построения визуализаций: гистограмм распределения длины абзацев, тепловых карт плотности текста и временных графиков изменений при редактировании документа. Практика показывает, что автоматизированный экспорт снижает трудозатраты на 70–80 % при подготовке аналитических отчётов по крупным текстам и позволяет выявлять структурные аномалии, которые сложно заметить при чтении вручную.
Вопрос-ответ:
Что считается абзацем в текстовом документе?
Абзац — это отдельная часть текста, обычно оформленная как блок, отделённый от предыдущего и следующего пустой строкой или отступом. Он может состоять из одного или нескольких предложений и служит для структурирования информации, чтобы текст был удобен для чтения. В большинстве текстовых редакторов новая строка с отступом или пустая строка автоматически формирует новый абзац.
Какими способами можно подсчитать количество абзацев в документе?
Существует несколько подходов. Вручную можно просто пройтись по тексту и отметить каждый новый абзац. В текстовых редакторах, таких как Word или LibreOffice, есть встроенные инструменты для статистики текста, которые показывают количество абзацев. Также можно использовать автоматические скрипты или функции в языках программирования, которые ищут разделители абзацев, например перенос строки или пустую строку, и на их основе подсчитывают блоки текста.
Почему количество абзацев может быть важно при работе с текстом?
Число абзацев отражает структуру текста и его читаемость. Много коротких абзацев делает материал более лёгким для восприятия, а длинные абзацы могут затруднять чтение и понимание. При редактировании или подготовке текста для публикации количество абзацев помогает определить, как логично распределена информация и насколько удобен текст для аудитории.
Можно ли подсчитать абзацы автоматически без использования текстового редактора?
Да, это возможно с помощью простых программ или скриптов. Например, на Python можно открыть файл, разделить текст по символу переноса строки и определить блоки, которые не пустые, как абзацы. Подобные методы применяются для анализа больших текстовых массивов, когда ручной подсчёт становится трудоёмким.
Как обработка пустых строк влияет на подсчёт абзацев?
При подсчёте абзацев важно учитывать, что пустые строки обычно отделяют один блок текста от другого. Если пустые строки не распознаются как разделители, программа может объединять несколько абзацев в один, и результат будет неточным. Напротив, лишние пустые строки могут увеличить количество абзацев в статистике. Поэтому при автоматическом подсчёте часто используют фильтрацию пустых строк, чтобы результат отражал фактическое деление текста на смысловые блоки.
Как можно быстро узнать количество абзацев в большом текстовом документе?
Существует несколько способов подсчёта абзацев. В текстовых редакторах, таких как Microsoft Word или LibreOffice Writer, обычно отображается количество абзацев в строке состояния или в статистике документа. Если такой функции нет, можно использовать поиск по символам переноса строки: каждый новый абзац обычно начинается с новой строки. Для больших файлов иногда применяют специальные скрипты на Python или других языках, которые считывают текст и считают разделители абзацев, что значительно ускоряет процесс.