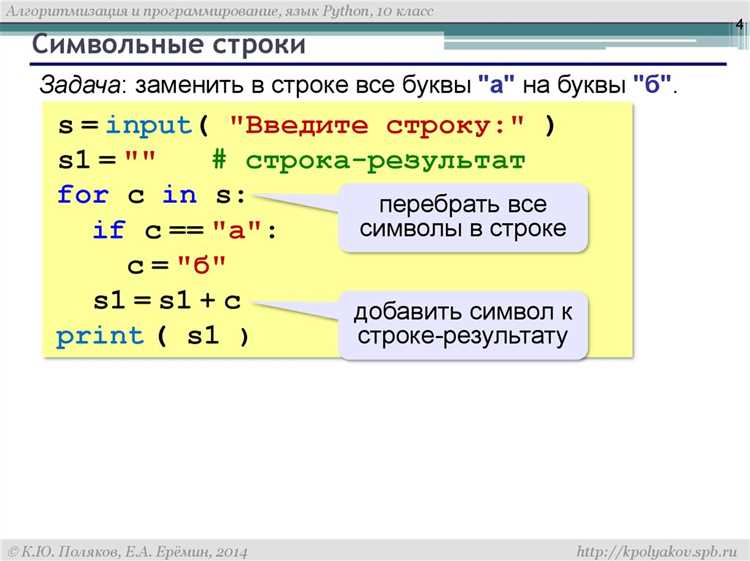
Содержание статьи

Определение длины строки – ключевая задача при обработке текста. В большинстве языков программирования для этого предусмотрены встроенные функции, возвращающие точное количество символов, включая пробелы и спецсимволы. Например, в Python используется len(), в JavaScript – string.length, а в PHP – strlen(). Каждая функция оптимизирована для быстрого подсчета и работает за константное время относительно длины строки.
Важно учитывать различия между символами и байтами. В UTF-8 многобайтовые символы занимают больше одного байта, поэтому при подсчете длины строки, предназначенной для хранения текста на разных языках, следует использовать функции, корректно работающие с кодировкой. В PHP для этого применяют mb_strlen(), а в Python строки уже обрабатываются как последовательность Unicode-символов.
Знание точной длины строки также необходимо при работе с алгоритмами поиска и сортировки, где операции зависят от количества символов. Функции длины строки обеспечивают детерминированный результат, что критично для сравнения строк и генерации хэш-значений. Это делает их не просто утилитой, а фундаментальным инструментом для стабильного и безопасного кода.
Использование функции strlen в PHP
Функция strlen возвращает количество байт в строке, включая пробелы и специальные символы. В PHP вызов выглядит как strlen($строка), где $строка – переменная типа string. Например, strlen(«PHP») вернёт 3.
Важно учитывать, что strlen считает именно байты, а не символы Unicode. Для многобайтовых кодировок, таких как UTF-8, использование strlen может давать результат, превышающий количество видимых символов. В таких случаях рекомендуется применять mb_strlen($строка, «UTF-8»).
Функция strlen полезна при проверке длины пароля, ограничении ввода в форме или для обработки текстовых данных перед сохранением в базу. Она выполняется быстро, поскольку работает на уровне внутреннего представления строки.
При работе с динамическими строками, например при конкатенации или чтении из файлов, можно использовать strlen для проверки границ или условий цикла. Например, if (strlen($текст) > 255) позволяет предотвратить переполнение поля базы данных.
Функция также учитывает управляющие символы, такие как \n, \t, что важно при анализе форматов файлов или логов. Любые скрытые символы будут включены в результат, поэтому при необходимости стоит предварительно использовать trim или str_replace.
Для оптимизации скриптов избегайте многократного вызова strlen внутри циклов, лучше сохранить длину строки в переменной и использовать повторно. Это снижает количество операций и ускоряет выполнение при работе с большими массивами текста.
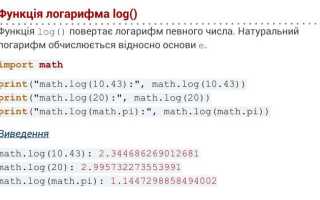
Подсчет символов в Python через len()

Функция len() возвращает точное количество элементов в объекте, включая строки. Для строк она подсчитывает каждый символ, включая пробелы, цифры и знаки препинания. Например, len("Python 3.11") вернет 10.
Функцию можно применять к переменным, содержащим строки: text = "Пример"; length = len(text). В переменной length окажется значение 6, соответствующее числу символов.
При работе с юникодными символами, включая эмодзи и символы кириллицы, len() учитывает каждый кодовый пункт отдельно. Например, len("😊") может вернуть 1, но комбинированные символы могут считаться несколькими элементами.
Для динамического подсчета символов в больших текстах используйте len() без изменений структуры строки. Это позволяет быстро определить размер текста перед записью в файл, базу данных или при проверке ограничений на длину ввода.
Если необходимо исключить пробелы, предварительно примените replace(" ", "") или join с фильтром. Например: len(" ".join(text.split())) вернет количество видимых символов без пробелов.
Функция len() работает на всех версиях Python 3.x одинаково, гарантируя совместимость скриптов и стабильное измерение длины строк вне зависимости от их содержания.
Функция length() для строк в JavaScript
В JavaScript длину строки можно определить через свойство length, а не функцию. Оно возвращает количество символов в строке, включая пробелы, специальные символы и знаки пунктуации.
Пример: let str = "Привет"; console.log(str.length); вернёт 6, так как слово состоит из шести символов.
Свойство length учитывает все UTF-16 символы. Это важно при работе с эмодзи или редкими символами, которые могут занимать два кода. Например, '😀'.length вернёт 2.
Для динамического контроля длины строки используйте length при проверках условий: обрезка текста, валидация ввода, ограничение количества символов. Пример: if (input.value.length > 100) { alert("Слишком длинная строка"); }.
Свойство length работает только для строк и массивов, не вызывается как функция. Попытка написать str.length() вызовет ошибку.
При работе с многострочными строками, символы перевода строки \n также учитываются в length. Это важно для корректного подсчёта символов при сохранении или отображении текста.
Для обхода сложных символов (эмодзи, диакритика) рекомендуется использовать спред-оператор или Array.from(str).length, чтобы получить реальное количество видимых символов.
Использование свойства length эффективно для измерения и контроля строк без необходимости дополнительных библиотек или функций.
Определение длины строки в Java через length()
В Java длина строки определяется с помощью метода length(), который возвращает количество символов в объекте типа String. Метод не принимает аргументов и всегда возвращает значение типа int.
Примеры использования:
- Простая строка:
String text = "Привет";int length = text.length(); // результат 6
- Пустая строка:
String empty = "";int length = empty.length(); // результат 0
- Строка с пробелами и спецсимволами:
String special = "A B\tC\nD";int length = special.length(); // учитываются пробелы, табуляции и переносы строк
Рекомендации по использованию:
- Метод
length()всегда возвращает реальное количество символов в строке, включая пробелы и спецсимволы. - Перед вызовом
length()стоит проверять, что объект строки не равенnull, чтобы избежатьNullPointerException. - Для подсчета символов с учетом Unicode-суррогатных пар используется
codePointCount(), так какlength()учитывает только 16-битные единицы. - Метод полезен для проверки ограничений на ввод пользователя, валидации данных и динамического управления длиной строк в алгоритмах.
Пример с проверкой null:
String str = getInput();
int len = (str != null) ? str.length() : 0;
Работа с длиной строк в C и C++ через strlen()
Функция strlen() из заголовочного файла <cstring> (в C++ или <string.h> в C) возвращает количество символов в строке до первого нулевого символа '\0'. Она принимает указатель на массив символов char* и возвращает значение типа size_t, что обеспечивает совместимость с 32- и 64-битными системами.
Пример вызова: size_t len = strlen(str);. Здесь str должна быть корректно завершенной нулем строкой. Если строка не оканчивается '\0', результат strlen() будет неопределенным и может привести к ошибкам памяти.
Функция выполняет линейный обход символов массива, поэтому время выполнения пропорционально длине строки. Для длинных строк это может быть заметно, особенно при многократных вызовах внутри циклов. В таких случаях лучше сохранять результат strlen() в переменную, а не вызывать функцию повторно.
В C++ с объектами std::string использование strlen() не обязательно, так как метод size() или length() возвращает длину строки без обхода массива и безопасен для любых символов, включая нулевые внутри строки.
Важно помнить, что strlen() измеряет количество символов до '\0' и не учитывает байты, занимаемые многобайтовыми кодировками (UTF-8). Для подсчета реального количества символов в UTF-8 требуется дополнительная обработка.
Использование strlen() оправдано при работе с классическими C-строками, проверке ввода и выделении динамической памяти. Для динамических массивов символов всегда проверяйте корректность завершения нулем, чтобы избежать чтения за пределами выделенной области.
Особенности подсчета символов Unicode в строках
Стандарт Unicode использует переменную длину кодовых точек, что усложняет точный подсчет символов. Один визуальный символ может состоять из нескольких кодовых точек: например, эмодзи с модификатором цвета, символы с диакритикой или составные знаки. Функции, которые просто возвращают длину строки по байтам или элементам массива, часто дают некорректный результат для таких случаев.
В языках программирования, таких как Python, метод len() возвращает количество кодовых единиц UTF-16 или UTF-32, а не визуальных символов. Для точного подсчета «графемных кластеров» рекомендуется использовать специализированные библиотеки, например, regex с поддержкой \X, или модуль unicodedata. В JavaScript стандартная функция string.length считает кодовые единицы UTF-16, что приводит к двойному учету некоторых символов, включая эмодзи и редкие иероглифы.
При работе с Unicode важно различать следующие понятия: кодовая точка, кодовая единица и графемный кластер. Кодовая точка – это уникальный номер символа в таблице Unicode. Кодовая единица – минимальный блок хранения в выбранной кодировке (UTF-8, UTF-16). Графемный кластер – визуально воспринимаемый символ, который может включать несколько кодовых точек. Для подсчета длины текста с визуальной точностью нужно ориентироваться на графемные кластеры.
Рекомендации при подсчете символов Unicode: использовать библиотеки, поддерживающие подсчет графемных кластеров; избегать прямого обращения к байтам или стандартной функции длины строки без учета кодировки; учитывать возможность составных символов при индексации и обрезке текста, чтобы не нарушать корректность отображения.
Вопрос-ответ:
Как определить количество символов в строке на Python?
В Python для подсчёта длины строки используется функция len(). Она принимает строку в качестве аргумента и возвращает целое число, равное количеству символов, включая пробелы и знаки препинания. Например, если вызвать len(«Привет»), функция вернёт 6.
Можно ли узнать длину строки, если она хранится в переменной?
Да, функция, подсчитывающая количество символов, работает с переменными. Если строка сохранена в переменной, например text = «Здравствуйте», вызов len(text) вернёт число 12, так как в слове 12 символов. Это удобно, когда строки меняются динамически в программе.
Считаются ли пробелы и знаки препинания при подсчёте длины строки?
Да, функция, возвращающая длину строки, учитывает все символы, включая пробелы, точки, запятые и специальные символы. Например, len(«Привет, мир!») вернёт 12, потому что здесь 12 символов: буквы, запятая, пробел и восклицательный знак.
Можно ли использовать эту функцию для подсчёта длины строки на других языках программирования?
Да, хотя синтаксис отличается, почти во всех языках есть встроенные способы определить длину текста. Например, в JavaScript используется свойство length: «Привет».length вернёт 6. В C# есть метод .Length для строк. Идея одна — подсчитать количество символов в тексте.
Что произойдёт, если передать функции не строку, а число или список?
Если передать числовое значение, функция выдаст ошибку, так как она рассчитана на строковые данные. Для списка функция вернёт количество элементов, а не символов. Поэтому важно проверять тип данных перед вызовом функции или приводить значение к строке через str(), если нужно узнать длину текстового представления числа.
Как с помощью функции определить количество символов в строке?
Чтобы узнать длину строки, можно использовать встроенные функции языка программирования, которые возвращают количество символов. Например, во многих языках есть функция, принимающая строку и возвращающая целое число — это число и будет длиной. Важно помнить, что пробелы, знаки препинания и даже специальные символы учитываются как отдельные символы. Такая функция полезна при обработке текста, проверке форматов данных или ограничении длины ввода.