Содержание статьи

random_state задаёт конкретное начальное значение генератора псевдослучайных чисел в sklearn. Это значение позволяет получать одинаковые результаты там, где алгоритм использует случайность: разбиение выборки, подбор признаков, инициализация параметров. Без фиксированного числа каждый запуск может выдавать другой набор данных или иную последовательность вычислений, что затрудняет проверку моделей.
Фиксированный random_state особенно важен в задачах, где требуется повторить эксперимент или сравнить несколько методов на одном и том же разбиении данных. Указание одного и того же числа обеспечивает полную совпадаемость результатов между разными средами, версиями ноутбуков и сеансами запуска.
При работе со sklearn целесообразно задавать random_state в функциях, задействующих случайность: train_test_split, модели со стохастическими элементами, методы ансамблей, инструменты векторизации текста. Это упрощает отладку, ускоряет проверку гипотез и исключает влияние случайных факторов на сравнение моделей.
Как random_state влияет на воспроизводимость результатов в моделях sklearn
random_state фиксирует последовательность случайных чисел, которую используют алгоритмы sklearn при разбиении данных, генерации поднабора признаков и инициализации параметров. При одинаковом значении параметра модель получает один и тот же порядок элементов, что делает вычисления предсказуемыми.
При работе с train_test_split фиксированное число гарантирует идентичный состав обучающей и тестовой выборок. Это позволяет сравнивать модели при равных условиях и исключить влияние различий в составе выборок на итоговые метрики.
В стохастических алгоритмах, таких как RandomForestClassifier или SGDClassifier, random_state контролирует порядок выбора признаков, формирование подмножеств данных и начальные веса. Благодаря фиксированному значению можно получить одинаковые результаты при повторном запуске, что упрощает анализ качества и корректировку параметров.
Фиксация random_state при разбиении датасета через train_test_split
Использование random_state в train_test_split задаёт неизменную последовательность выбора индексов, формирующих обучающую и тестовую части. При указании одного и того же числа разбиение совпадает на каждом запуске, независимо от среды выполнения и порядка операций в коде.
Фиксация параметра важна при сравнении моделей: одинаковый состав выборок исключает смещение метрик из-за случайного распределения объектов. Это особенно заметно на небольших датасетах, где перемещение нескольких записей между выборками способно изменить значение точности, F1 или ROC-AUC.
При многократной отладке стоит использовать одно фиксированное значение random_state, а при финальной проверке – дополнительно протестировать модель на нескольких различных значениях, чтобы оценить устойчивость поведения к смене разбиения.
Применение random_state в алгоритмах классификации и его влияние на обучение

Значение random_state регулирует последовательность случайных операций, влияющих на результат обучения в стохастических классификаторах. Это касается выбора признаков, инициализации параметров и порядка обработки объектов.
- LogisticRegression (solver=sag/saga) – параметр задаёт начальное состояние генератора, от которого зависит траектория обновления весов. При фиксированном числе модель формирует одинаковые коэффициенты при каждом запуске.
- SGDClassifier – порядок подачи примеров в стохастический градиент влияет на итоговые веса. Фиксированный random_state обеспечивает один и тот же порядок итераций.
- KNeighborsClassifier при использовании weights=’distance’ или при подборе соседей в случайном порядке может опираться на генератор случайных чисел. Параметр исключает различия между запусками.
- Tree-based методы (DecisionTreeClassifier, RandomForestClassifier) используют случайный выбор признаков на каждом шаге. Фиксированное число создаёт стабильную структуру деревьев.
Для задач, где требуется сопоставить результаты разных классификаторов, стоит задавать одинаковый random_state во всех моделях, чтобы исключить влияние случайных факторов при обучении и обеспечить корректность сравнения метрик.
Использование random_state в моделях регрессии с внутренней случайностью
Регрессионные алгоритмы, включающие стохастические компоненты, используют random_state для контроля начальных условий и порядка вычислительных шагов. Это влияет на структуру моделей, распределение ошибок и стабильность итоговых коэффициентов.
В RandomForestRegressor и ExtraTreesRegressor параметр определяет выбор признаков и подвыборок на каждом дереве. Фиксированное значение позволяет получить одинаковый набор моделей внутри ансамбля, что важно при анализе влияния отдельных признаков.
В SGDRegressor порядок обработки примеров влияет на траекторию обновления весов. Указание конкретного числа обеспечит повторяемость результата при одинаковых настройках шага обучения и регуляризации.
При подготовке отчётов и при сравнении нескольких архитектур регрессоров фиксированный random_state упрощает диагностику отклонений в поведении моделей и помогает избежать ложных различий, возникающих из-за случайных вариаций.
Роль random_state в методах ансамблей: RandomForest, ExtraTrees, GradientBoosting
Ансамблевые модели используют случайные операции на каждом этапе построения деревьев. Параметр random_state фиксирует эти операции и делает структуру ансамбля стабильной при повторных запусках.
- RandomForest использует случайный выбор признаков на каждом разбиении узла и случайные подвыборки объектов. Фиксированное число позволяет получить один и тот же набор деревьев, что упрощает анализ важности признаков и сравнение с другими моделями.
- ExtraTrees добавляет дополнительный уровень случайности, выбирая пороги разбиений случайным образом. Без фиксированного random_state структура деревьев заметно меняется, что влияет на вариации метрик.
- GradientBoosting опирается на стохастическую подвыборку объектов (subsample < 1.0). Указание конкретного значения делает последовательность построения деревьев предсказуемой и позволяет проверять влияние гиперпараметров без скрытых колебаний.
При использовании ансамблей рекомендуется задавать одно число random_state для всех моделей в рамках эксперимента, чтобы различия в качестве зависели только от параметров и набора признаков, а не от случайных отклонений в структуре деревьев.
Использование random_state при векторизации текста и работе со случайным порядком признаков
При преобразовании текста в числовые признаки многие алгоритмы sklearn используют случайные процессы. Параметр random_state контролирует эти процессы, обеспечивая воспроизводимость результатов.
В HashingVectorizer и TruncatedSVD random_state фиксирует генератор случайных чисел, который определяет распределение хэш-функций и случайное разбиение матрицы. Это позволяет получить идентичное представление текста при повторных запусках.
При случайной перестановке признаков в FeatureUnion или при отборе подмножеств в SelectKBest использование random_state гарантирует, что выбранные признаки и порядок их обработки останутся одинаковыми. Это критично для сравнения моделей и оценки стабильности метрик.
Рекомендуется всегда задавать random_state при векторизации и работе со случайным порядком признаков, особенно при экспериментах с подмножествами данных, чтобы исключить влияние скрытой случайности на результаты обучения и тестирования.
Как random_state помогает при подборе гиперпараметров и повторяемости экспериментов
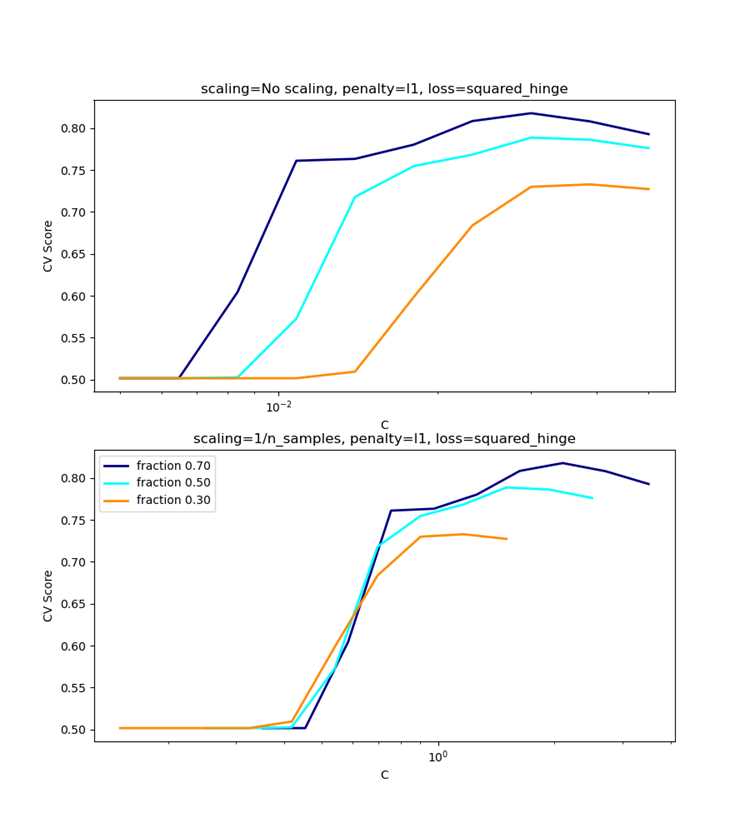
random_state фиксирует последовательность случайных операций, используемых при обучении моделей и разбиении данных, что делает результаты воспроизводимыми. Это важно при настройке гиперпараметров, так как без фиксации генератора случайных чисел повторные запуски могут давать разные метрики для одинаковых настроек.
В GridSearchCV и RandomizedSearchCV random_state влияет на разбиение данных в кросс-валидации и порядок перебора параметров. Фиксированное значение позволяет сравнивать комбинации гиперпараметров в одинаковых условиях, исключая случайные колебания метрик.
Применение одного random_state во всех экспериментах помогает:
- Сохранять стабильность оценок точности, F1 и ROC-AUC при повторных запусках.
- Сравнивать разные модели на одинаковых разбиениях данных.
- Воспроизводить эксперименты на разных устройствах и версиях библиотек sklearn.
Рекомендуется задавать одно и то же значение random_state при всех этапах подбора гиперпараметров, чтобы исключить влияние случайной инициализации и ускорить выявление оптимальных настроек.
Типичные ошибки при работе с random_state и способы их избежать
Неправильное использование random_state может привести к непредсказуемым результатам и затруднить повторяемость экспериментов. Основные ошибки связаны с отсутствием фиксации, несогласованностью значений между разными функциями и случайным переопределением параметра в разных этапах работы с моделью.
Ниже приведена таблица с типичными проблемами и рекомендациями по их устранению:
| Ошибка | Описание | Рекомендации |
|---|---|---|
| Не зафиксирован random_state | Каждый запуск модели или разбиение данных даёт разные результаты. | Всегда указывать конкретное число при train_test_split, моделях с стохастическими элементами и при кросс-валидации. |
| Несогласованность значений | Используются разные значения random_state для разбиения данных и обучения модели. | Применять одно и то же значение random_state для всех функций, участвующих в эксперименте. |
| Переопределение random_state внутри цикла | Случайно изменяется значение при повторных итерациях или подборе гиперпараметров. | Задавать random_state один раз перед началом эксперимента и использовать ссылку на это значение везде. |
| Игнорирование random_state при векторизации или преобразовании признаков | Случайные операции в обработке данных меняют признаки между запусками. | Фиксировать random_state в трансформерах типа HashingVectorizer, TruncatedSVD, FeatureUnion. |
Соблюдение этих правил позволяет избежать непредсказуемых отклонений в метриках и гарантирует воспроизводимость результатов на разных системах и при повторных экспериментах.
Вопрос-ответ:
Что такое random_state в sklearn и для чего он нужен?
random_state — это параметр, который задаёт начальное состояние генератора случайных чисел, используемого в алгоритмах sklearn. Он нужен для того, чтобы результаты разбиения данных, обучения моделей и случайных операций оставались одинаковыми при повторных запусках. Это позволяет точно воспроизводить эксперименты и сравнивать модели без влияния случайности.
Как random_state влияет на train_test_split?
При использовании train_test_split random_state определяет порядок, в котором данные распределяются между обучающей и тестовой выборками. Если не задавать значение, каждый запуск создаёт разные выборки, что может изменять метрики модели. Задав фиксированное число, можно получать одинаковое разбиение при повторных запусках.
Нужно ли указывать random_state для всех моделей и функций в проекте?
Указывать random_state желательно для всех функций, где присутствует случайность: разбиение данных, стохастические классификаторы, ансамблевые методы, векторизация текста. Это позволяет сопоставлять результаты моделей и исключает скрытые изменения из-за случайного порядка объектов или признаков.
Как random_state влияет на методы ансамблей вроде RandomForest и GradientBoosting?
В ансамблевых алгоритмах random_state задаёт порядок выбора подвыборок объектов и признаков для каждого дерева, а также случайные разбиения узлов. Фиксированное значение создаёт стабильную структуру ансамбля и одинаковый результат при повторных запусках, что облегчает анализ важности признаков и сравнение моделей.
Какие ошибки чаще всего допускают при работе с random_state и как их избежать?
Типичные ошибки: отсутствие фиксации random_state, использование разных значений в разных функциях, переопределение параметра внутри циклов. Чтобы их избежать, рекомендуется выбрать одно число для всех функций проекта и использовать его во всех моделях и трансформерах, где присутствует случайность. Это обеспечивает стабильность метрик и воспроизводимость экспериментов.
Что происходит, если не задавать random_state в моделях sklearn?
Если random_state не указан, алгоритмы, использующие случайность, каждый раз будут давать разные результаты. Это касается разбиения данных, стохастических классификаторов, ансамблевых методов и трансформаций признаков. Разные запуски модели на одном и том же датасете могут показывать разные метрики, что затрудняет сравнение и повторение экспериментов.
Как выбрать значение random_state для своих экспериментов?
Значение random_state может быть любым целым числом. Главное — использовать одно и то же число для всех функций и моделей в рамках эксперимента. Это обеспечивает одинаковое разбиение данных, одинаковый порядок генерации случайных параметров и стабильные результаты при повторных запусках. Для разных проектов можно использовать разные числа, чтобы проверить устойчивость модели к случайности.