Содержание статьи

Работа со строками в Python часто требует их разбор на отдельные элементы. В типичных задачах встречаются списки чисел, слов или символов, упакованные в одну строку. Ошибка на этапе разбиения приводит к неверным данным, поэтому важно учитывать формат входного текста и возможные отклонения: лишние пробелы, отсутствующие разделители, разнородные типы значений.
В языке предусмотрены базовые инструменты для разбиения строки, а также возможности для тонкой обработки входных данных. split() подходит для простых случаев, map() помогает привести элементы к нужному типу, а регулярные выражения позволяют разобрать строку с непредсказуемой структурой. Чёткое понимание этих подходов ускоряет работу и уменьшает вероятность логических ошибок.
Корректное преобразование строки в массив особенно важно при разборе конфигураций, данных из файлов, параметров запросов или текстовых логов. В таких ситуациях полезно заранее определить возможные форматы строки и подобрать инструмент, который справится с ними без дополнительных исправлений.
Разбор строки по разделителю с помощью split()
Метод split() разбивает строку на элементы по указанному символу или последовательности символов. Если разделитель не указан, Python использует пробелы и табуляции, что удобно для простых текстовых списков. Явное указание разделителя требуется при работе с данными, где в одном фрагменте могут встречаться разные пробельные символы.
При разборе строк с фиксированным форматом важно указывать точный разделитель: запятую, точку с запятой, вертикальную черту или табуляцию. Например, запись параметров вида «10,20,30» корректно превращается в массив через split(‘,’). Если строка содержит лишние пробелы вокруг разделителя, требуется дополнительная обработка каждого элемента методом strip().
Для предотвращения появления пустых элементов стоит проверять входные данные. Например, последовательность вида «a,,b» при использовании split(‘,’) создаст пустую строку между двумя запятыми. Такие элементы можно исключить с помощью генераторов списка или фильтрации по длине.
В задачах с ограничением по количеству разбиений полезен параметр maxsplit. Он задаёт верхнюю границу количества разборов, сохраняя оставшуюся часть строки в последнем элементе. Это помогает корректно извлекать первые значения из строки, содержащей комментарии или дополнительный текст после основных данных.
Преобразование строки в список чисел через map() и int()
Когда строка содержит набор цифровых значений, разбиение по разделителю – лишь первый шаг. Чтобы получить список чисел, каждое значение нужно привести к целому типу. Комбинация map(int, …) позволяет выполнить преобразование без явного цикла и уменьшает риск ошибок при ручной обработке.
Перед применением map() важно убедиться, что в строке нет символов, препятствующих преобразованию: лишних пробелов внутри чисел, пустых элементов или неподходящих знаков. Например, после разбиения строки «10, 25, 40» через split(‘,’) безопаснее дополнительно вызвать strip() для каждого фрагмента.
Если данные поступают из файлов или внешних систем, возможны значения, не подходящие под формат целого числа. В таких случаях полезно предусмотреть обработку исключений или проверку каждого элемента через метод isdigit(). Это помогает исключить строки с единичными ошибками, не затрагивая остальные корректные значения.
Для преобразования чисел с плавающей точкой можно заменить int() на float(). Это удобно при работе с измерениями, параметрами конфигураций или вычислительными результатами, представленными в текстовых файлах. Принцип остаётся тем же: разбиение строки, очистка данных и применение функции преобразования через map().
Разделение строки на отдельные символы
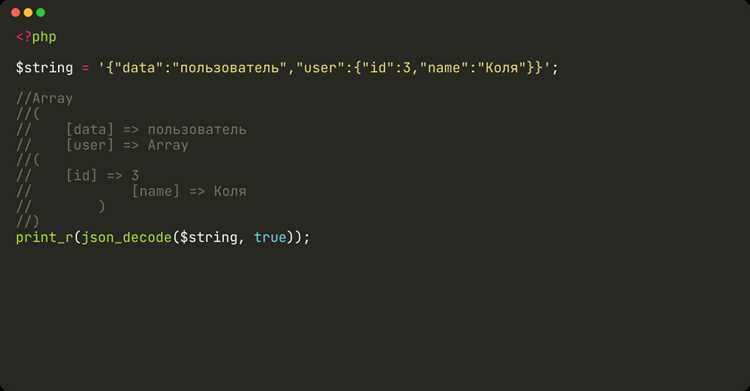
Получение массива символов требуется при анализе паролей, обработке кода, работе с форматами, где каждый знак имеет собственное значение. В Python строка уже поддерживает последовательный доступ к элементам, поэтому преобразование в массив сводится к явному созданию списка: list(строка). Такой подход сохраняет порядок и не требует указания разделителя.
Если строка содержит пробелы, управляющие символы или нестандартные Unicode-знаки, список будет включать их без изменений. Это важно при обработке данных, где пробелы играют роль маркеров. Чтобы исключить нежелательные элементы, можно применить фильтрацию через генератор списка, проверяя кодовые точки или принадлежность символов к нужным диапазонам.
При разборе строк, содержащих пары символов или составные знаки, стоит учитывать, что некоторые Unicode-символы состоят из нескольких кодовых единиц. В таких случаях результат, полученный через list(), может не совпадать с визуальным представлением строки. Для обработки таких фрагментов применяют модуль unicodedata или методы нормализации, что позволяет корректно работать с комбинированными символами.
Обработка лишних пробелов и пустых элементов при разбиении

Пустые элементы возникают при последовательных разделителях, например в строке «a,,b,». Метод split() создаёт пустые строки между такими разделителями. Чтобы исключить их, удобно использовать генератор списка с условием по длине или фильтровать элементы функцией filter(). Такой подход оставляет только содержательные значения и предотвращает ошибки при дальнейшем анализе.
Если входные данные могут содержать случайные табуляции или смешанные пробельные символы, перед разбиением можно применить замену через replace() или регулярные выражения. Это позволяет привести строку к единому виду и упростить контроль качества массива, полученного после обработки.
Преобразование форматированных строк (CSV, логовые записи) в массив

Строки из CSV-файлов и логов содержат фиксированные структуры, которые необходимо корректно разобрать. Простого split() часто недостаточно: внутри полей могут встречаться запятые, кавычки и пробелы, влияющие на итоговое разбиение. Для CSV оптимально использовать модуль csv, который учитывает экранирование и специальные случаи.
- При разборе строки CSV через csv.reader учитывается формат полей, заключённых в кавычки.
- Если строка содержит вложенные запятые, модуль корректно восстанавливает исходные значения без ручной фильтрации.
- При необходимости можно задать собственный разделитель, например точку с запятой или табуляцию.
Для логовых строк структура зависит от конкретного формата: временные метки, уровни записи, текст сообщения. В таких случаях удобнее использовать split() с параметром maxsplit, что позволяет отделить служебные части от основного текста.
- Извлечь первые поля, фиксированные по количеству.
- Оставшуюся часть строки сохранить без дальнейшего разбиения.
- Очистить массив от лишних пробелов и символов форматирования.
Если лог содержит сложные структуры, применяют регулярные выражения: они позволяют выделить дату, уровень события, путь к файлу и текст сообщения, формируя массив из заранее известных групп.
Разбор строки в массив слов по регулярным выражениям
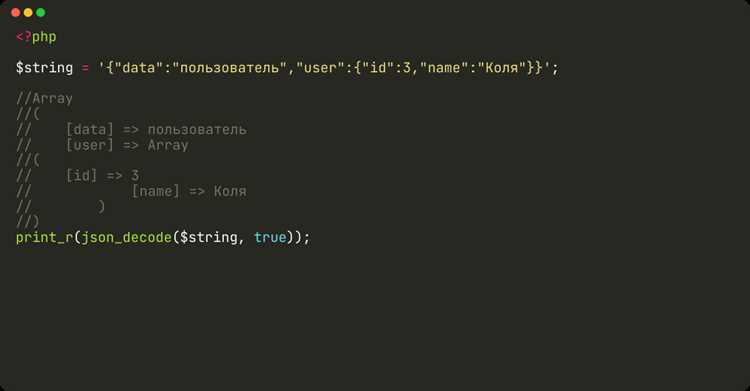
Регулярные выражения позволяют извлекать слова из строки, где разделители непредсказуемы: пробелы, знаки препинания, табуляции или сочетания символов. В Python используется модуль re с функцией re.findall(), которая возвращает список всех совпадений по заданному шаблону.
Пример шаблона для извлечения слов: r’\w+’. Он захватывает последовательности букв и цифр, игнорируя знаки препинания. Для расширенной обработки можно использовать классы символов, включающие кириллицу и специальные символы, если текст мультиязычный.
Применение регулярных выражений удобно для структурирования текста перед анализом. Для наглядного примера приведена таблица с разбором строки:
| Исходная строка | Регулярное выражение | Результат массива |
|---|---|---|
| «Ошибка: файл не найден, путь /usr/local/bin» | r’\w+’ | [‘Ошибка’, ‘файл’, ‘не’, ‘найден’, ‘путь’, ‘usr’, ‘local’, ‘bin’] |
| «123;abc,тест!@#» | r’\w+’ | [‘123’, ‘abc’, ‘тест’] |
При работе с логами или текстами с большим количеством разделителей регулярные выражения упрощают преобразование в массив слов, позволяя затем выполнять фильтрацию, подсчёт частот или анализ содержимого без лишних шагов очистки.
Вопрос-ответ:
Как разделить строку на массив чисел в Python?
Для преобразования строки с числами в массив сначала используйте метод split(), чтобы разбить строку по разделителю, например запятой. Затем примените map(int, …) для преобразования каждого элемента в целое число. Например: nums = list(map(int, «10,20,30».split(‘,’))) создаст массив [10, 20, 30]. Перед этим полезно вызвать strip() для удаления лишних пробелов.
Можно ли разбить строку на отдельные символы без использования циклов?
Да, в Python достаточно применить list(строка). Это создаст массив, где каждый элемент — отдельный символ строки. Например, list(«abc») вернёт [‘a’, ‘b’, ‘c’]. Если в строке есть пробелы или спецсимволы, они тоже попадут в массив. Для удаления пробелов можно использовать генератор списка с условием, например: [c for c in s if c != ‘ ‘].
Как обработать строки с пустыми элементами после разбиения?
Пустые элементы появляются, когда разделитель встречается подряд или в начале/конце строки. Чтобы их исключить, после split() применяют фильтрацию. Например: elements = [x.strip() for x in s.split(‘,’) if x.strip()]. Это удалит пустые строки и пробелы, оставив только содержательные значения.
Когда стоит использовать регулярные выражения для разбиения строки?
Регулярные выражения нужны, когда разделители непредсказуемые или их несколько видов одновременно: пробелы, запятые, точки с запятой, специальные символы. Функция re.findall() позволяет извлечь все слова или числа по заданному шаблону, игнорируя лишние символы. Например, re.findall(r’\w+’, s) создаёт массив слов, удаляя знаки препинания и разделители.