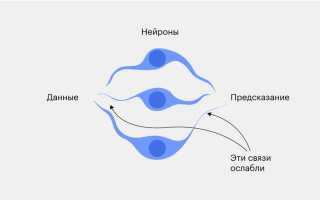
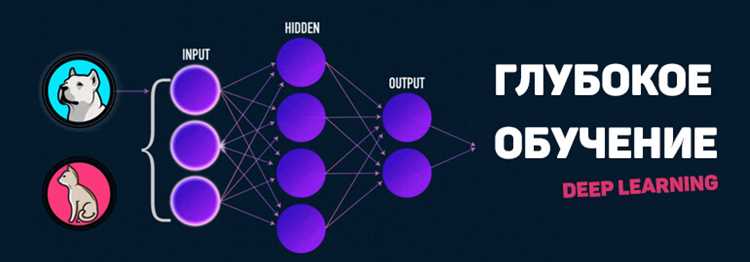
Deep learning – это метод машинного обучения, который использует многослойные нейронные сети для анализа данных. Сеть состоит из множества нейронов, объединённых в слои, где каждый слой преобразует входные данные в более сложные признаки. Такой подход позволяет сети распознавать закономерности, которые трудно выявить обычными алгоритмами.
Для обучения сети применяются большие наборы данных. На каждом этапе сеть сравнивает свои прогнозы с правильными ответами и корректирует веса соединений между нейронами. Этот процесс называется обратным распространением ошибки и обеспечивает постепенное улучшение точности модели.
Сети глубокого обучения применяются для обработки изображений, текста и звука. Например, сверточные сети анализируют пиксели фотографий для распознавания объектов, а рекуррентные сети работают с последовательностями слов или сигналов. Выбор типа сети зависит от формата данных и задачи, которую необходимо решить.
Создавая модель, важно контролировать переобучение. Для этого используют методы регуляризации, нормализации данных и разделение набора на тренировочный и тестовый. Такие меры помогают сети работать стабильно при обработке новых данных и повышают точность прогнозов.
Что такое нейронная сеть и как она имитирует мозг
Основные компоненты нейронной сети можно представить в таблице:
| Компонент | Роль |
|---|---|
| Входной слой | Принимает исходные данные для анализа |
| Скрытые слои | Преобразуют информацию, выявляя сложные признаки |
| Выходной слой | Генерирует результат обработки |
| Нейроны | Обрабатывают сигналы, соединяя слои |
| Весовые коэффициенты | Определяют важность каждого входного сигнала |
| Функции активации | Вводят нелинейность для сложных вычислений |
Имитируя мозг, нейронная сеть способна выявлять закономерности и адаптироваться к данным через обучение. Сеть корректирует веса на основе ошибок предсказания, что позволяет постепенно улучшать точность при распознавании изображений, текста или аудиосигналов.
Разновидности нейронных сетей и их назначение

Существует несколько типов нейронных сетей, каждая из которых оптимальна для определённых задач. Полносвязные сети (Fully Connected) используют каждый нейрон одного слоя для соединения со всеми нейронами следующего слоя. Они подходят для анализа структурированных данных и прогнозирования числовых значений.
Сверточные сети (Convolutional Neural Networks, CNN) применяются для обработки изображений и видео. Они используют фильтры, которые выявляют локальные признаки, такие как края, текстуры и формы, что упрощает распознавание объектов без предварительной ручной обработки.
Рекуррентные сети (Recurrent Neural Networks, RNN) предназначены для работы с последовательностями данных, включая текст, аудио и временные ряды. Благодаря обратным связям они учитывают предыдущие состояния при анализе текущего элемента последовательности, что важно для предсказаний и генерации текста.
Сети с долгой краткосрочной памятью (LSTM) – особый вид RNN, способный сохранять информацию на длительные промежутки. Они применяются в задачах перевода текста, распознавания речи и анализа временных зависимостей.
Выбор типа сети зависит от структуры данных и конечной цели. Сверточные сети эффективны для визуальных данных, рекуррентные – для последовательностей, а полносвязные – для табличных и числовых данных. При проектировании модели важно учитывать совместимость архитектуры с задачей для точного и быстрого обучения.
Как нейроны и слои взаимодействуют между собой
Каждый нейрон в слое получает входные данные от нейронов предыдущего слоя. Каждый сигнал умножается на весовой коэффициент, который определяет значимость данного входа, после чего суммируется и передаётся через функцию активации, добавляющую нелинейность.
Результат работы нейрона становится входом для следующего слоя. Слои могут быть скрытыми, выполняющими промежуточную обработку данных, или выходными, формирующими окончательный прогноз модели. Такая последовательная передача сигналов позволяет сети выявлять сложные зависимости между признаками.
Для улучшения сходимости используют нормализацию сигналов между слоями, что предотвращает затухание или взрыв градиентов. Также применяются дропауты – временное отключение части нейронов, чтобы уменьшить переобучение и повысить устойчивость сети к шуму в данных.
Интерактивность слоев реализуется через обратное распространение ошибки. После вычисления прогноза сеть сравнивает результат с эталоном, вычисляет ошибку и корректирует веса нейронов, обеспечивая постепенное улучшение точности при повторных итерациях обучения.
Роль функций активации в обработке данных
Функции активации определяют выход нейрона после суммирования взвешенных входов. Они вводят нелинейность, которая позволяет сети моделировать сложные зависимости между признаками, недоступные линейным преобразованиям.
Наиболее распространённые функции активации:
ReLU (Rectified Linear Unit) – возвращает ноль для отрицательных входов и значение входа для положительных. Применяется в скрытых слоях для ускорения обучения и уменьшения проблемы затухающих градиентов.
Sigmoid – сжимает вход в диапазон от 0 до 1, что удобно для вероятностных прогнозов, например, в задачах классификации двух классов.
Softmax – нормализует выходной вектор в распределение вероятностей, подходящее для многоклассовой классификации.
Выбор функции активации зависит от задачи и архитектуры сети. ReLU подходит для глубоких скрытых слоев, Sigmoid и Softmax – для выходных слоев при прогнозировании категорий. Неправильный выбор может замедлить обучение или привести к потере информации при прохождении сигнала через сеть.
Принцип обучения сети на примерах и ошибках
Обучение нейронной сети основано на сравнении предсказаний с правильными ответами и корректировке весов для уменьшения ошибки. Этот процесс позволяет сети постепенно улучшать точность прогнозов.
Основные этапы обучения можно представить следующим образом:
- Передача данных: входные примеры подаются на входной слой и проходят через скрытые слои до выхода.
- Вычисление ошибки: результат сравнивается с эталонным значением, используя функцию потерь (например, MSE для регрессии или кросс-энтропию для классификации).
- Обратное распространение: ошибка распространяется обратно через слои для расчёта градиентов.
- Корректировка весов: веса нейронов изменяются с помощью метода градиентного спуска или его модификаций, чтобы уменьшить ошибку на следующей итерации.
Для ускорения обучения применяются приёмы:
- Мини-батчи – обработка небольших порций данных вместо всей выборки.
- Регуляризация – добавление штрафа к функции потерь для предотвращения переобучения.
- Инициализация весов – правильный выбор начальных значений, чтобы избежать затухания или взрыва градиентов.
Регулярная проверка сети на отдельном тестовом наборе помогает контролировать качество обучения и корректировать параметры без влияния на тренировочные данные.
Обучение с учителем и без учителя: различия

Обучение с учителем предполагает наличие размеченных данных, где каждому входу соответствует правильный выход. Сеть сравнивает свои прогнозы с эталоном и корректирует веса для уменьшения ошибки. Этот подход используется в классификации, регрессии и задачах прогнозирования.
Обучение без учителя работает с неразмеченными данными. Сеть ищет закономерности, объединяет похожие объекты в группы или выделяет скрытые структуры. Основные методы – кластеризация и понижение размерности, например, алгоритмы K-Means, PCA и автоэнкодеры.
Сравнение методов:
- С учителем: требует размеченных наборов, даёт точные прогнозы, подходит для конкретных задач.
- Без учителя: не требует меток, выявляет скрытые структуры, полезно для анализа больших объёмов данных.
Выбор метода зависит от доступности данных и цели задачи. Если имеются точные примеры вход-выход – используется обучение с учителем, если нужно выявить закономерности в массиве данных – без учителя.
Как сеть обрабатывает изображения, текст и звук
Нейронные сети применяют разные архитектуры в зависимости от типа данных для извлечения признаков и анализа информации.
Обработка изображений:
- Сверточные сети (CNN) используют фильтры, которые сканируют изображения и выявляют границы, текстуры и формы.
- Каждый фильтр формирует карты признаков, которые объединяются в скрытых слоях для выявления более сложных объектов.
- Pooling-слои уменьшают размерность, сохраняя ключевую информацию и ускоряя обучение.
Обработка текста:
- Рекуррентные сети (RNN) и LSTM анализируют последовательности слов, учитывая контекст предыдущих элементов.
- Токенизация и векторизация преобразуют текст в числовой формат для подачи на вход сети.
- Векторные представления слов (word embeddings) помогают улавливать смысловые связи между словами.
Обработка звука:
- Аудиосигналы сначала преобразуются в спектрограммы, которые представляют частотные характеристики во времени.
- Сверточные и рекуррентные слои извлекают особенности звука, такие как тон, ритм и тембр.
- Модели могут использоваться для распознавания речи, классификации звуков и генерации аудиосигналов.
Выбор архитектуры и методов обработки зависит от формата данных и требуемого результата. Правильная подготовка и нормализация входов повышает точность и стабильность работы сети.
Типичные ошибки и трудности при создании моделей
Недостаток данных затрудняет обучение и снижает качество прогнозов. В таких случаях используют аугментацию данных, генерацию синтетических примеров или предобученные модели.
Неправильная инициализация весов может привести к затуханию или взрыву градиентов, особенно в глубоких сетях. Рекомендуется использовать методы He или Xavier и нормализацию сигналов между слоями.
Выбор неподходящей архитектуры снижает точность. Сверточные сети лучше работают с изображениями, рекуррентные и LSTM – с последовательностями. Важно сопоставлять структуру сети с типом данных и задачей.
Проблемы с обучением возникают при слишком высокой или низкой скорости обучения, недостатке вычислительных ресурсов или шумных данных. Контроль гиперпараметров, нормализация и очистка данных помогают минимизировать такие трудности.
Вопрос-ответ:
Что такое нейронная сеть и как она работает?
Нейронная сеть — это структура из искусственных нейронов, объединённых в слои. Каждый нейрон принимает сигналы от предыдущего слоя, умножает их на веса, суммирует и пропускает через функцию активации. Результат передаётся следующему слою. Такая последовательная обработка позволяет сети выявлять сложные зависимости и закономерности в данных.
Какие типы нейронных сетей существуют и для чего они применяются?
Существуют разные архитектуры: полносвязные сети анализируют числовые и структурированные данные, сверточные (CNN) распознают изображения и видео, рекуррентные (RNN) и LSTM работают с последовательностями текста или аудио. Выбор зависит от формата данных и задачи: визуальные данные требуют CNN, текстовые и временные последовательности — RNN или LSTM, табличные данные — полносвязные сети.
Почему важны функции активации и какие из них чаще используют?
Функции активации добавляют нелинейность, позволяя сети выявлять сложные зависимости. Популярные варианты: ReLU — для скрытых слоёв, ускоряет обучение; Sigmoid — сжимает значения от 0 до 1 для вероятностных прогнозов; Softmax — нормализует вектор выходов для многоклассовой классификации. Неправильный выбор может замедлить обучение или снизить точность.
Чем обучение с учителем отличается от обучения без учителя?
При обучении с учителем сеть использует размеченные данные: каждому входу соответствует правильный выход. Ошибка предсказания используется для корректировки весов. Обучение без учителя работает с неразмеченными данными и ищет скрытые закономерности, объединяя объекты в группы или снижая размерность. Метод выбирают исходя из наличия меток и цели анализа данных.
Какие типичные ошибки возникают при создании моделей глубокого обучения?
Частые ошибки: переобучение, когда сеть слишком подстраивается под тренировочные данные; недостаток данных, приводящий к низкой точности; неправильная инициализация весов, вызывающая затухание или взрыв градиентов; выбор неподходящей архитектуры для типа данных; некорректные гиперпараметры и шумные входные данные. Методы борьбы включают регуляризацию, нормализацию, очистку данных и подбор архитектуры под задачу.