Содержание статьи

Функция ВПР часто возвращает #Н/Д, даже когда на первый взгляд значение присутствует в таблице. Основная причина – несовпадение формата данных. Например, числа, записанные как текст, не распознаются как совпадения с числовыми ячейками, а даты, скопированные из внешних источников, могут иметь скрытые коды времени, мешающие поиску.
Еще одна распространенная причина – лишние пробелы и невидимые символы. Даже один пробел перед или после значения превращает точное совпадение в невозможное. ВПР строго сравнивает содержимое ячеек, поэтому очистка текста через функцию СЖПРОБЕЛЫ или проверка невидимых символов существенно увеличивает вероятность корректного поиска.
Неверные настройки самой функции также вызывают ошибки. Часто используется приблизительный поиск без сортировки диапазона, или указан неверный номер столбца. В результате ВПР не находит совпадение, хотя данные визуально идентичны. Простая проверка параметра точного совпадения и структуры диапазона решает большинство проблем.
Объединённые ячейки в диапазоне поиска – еще один источник сбоев. ВПР читает только верхнюю левую ячейку объединенной группы, игнорируя остальные, что приводит к непредсказуемым результатам. Разделение объединённых ячеек или корректировка диапазона позволяет восстановить точность поиска.
Понимание этих нюансов позволяет не только устранить ошибку #Н/Д, но и выстроить надежную систему поиска данных, минимизируя ручную проверку и повторное редактирование таблиц. Каждая мелочь – формат, пробел или настройка функции – напрямую влияет на результат ВПР.
Числа сохранены как текст и не совпадают с числовыми значениями
Проверить, сохранено ли число как текст, можно с помощью функции ТИП. Если результат равен 2, это текст, если 1 – число. Еще один способ – обратить внимание на выравнивание: текстовые числа по умолчанию выравниваются влево, а числовые – вправо.
Исправить формат можно несколькими способами. Использование функции ЗНАЧ преобразует текст в число. Альтернатива – выделить диапазон, выбрать «Преобразовать в число» в контекстном меню Excel или умножить все ячейки на 1 через формулу. После этого ВПР начнет корректно находить совпадения.
Для больших таблиц полезно использовать проверку с помощью условного форматирования: выделить все ячейки, где формат текста отличается от числа. Это позволяет быстро локализовать проблемные данные и минимизировать ошибки при поиске.
Лишние пробелы и непечатаемые символы мешают совпадению
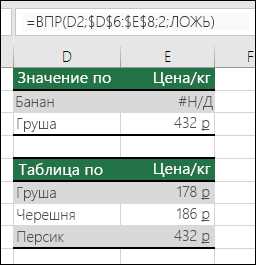
Даже один пробел в начале или конце ячейки делает точное совпадение невозможным. Например, значение «123 » визуально идентично 123, но ВПР не распознает его как совпадение. Аналогично, невидимые символы, скопированные из веб-страниц или PDF, создают ошибки поиска.
Выявить проблему помогает функция ДЛСТР для сравнения длины содержимого и визуального значения. Если длина превышает ожидаемую, есть лишние символы. Также полезно применять СЖПРОБЕЛЫ для удаления пробелов в начале и конце и ПРОБЕЛЫ(ТЕКСТ) для очистки лишних пробелов внутри текста.
Для удаления непечатаемых символов используют функцию ПРОБЕЛЫСИМВОЛЫ или комбинацию СЖПРОБЕЛЫ(ПОДСТАВИТЬ(ТЕКСТ;СИМВОЛ(160);»»)) для удаления символов с кодом 160. После очистки диапазона ВПР начинает корректно находить совпадения и возвращает нужные значения без ошибок.
Параметр точного совпадения не указан или задан неверно
ВПР по умолчанию выполняет приблизительный поиск, если параметр точного совпадения не задан. Это означает, что функция ищет ближайшее значение, а не идентичное, и возвращает #Н/Д, если диапазон не отсортирован по возрастанию.
Для точного совпадения необходимо указать последний аргумент функции как ЛОЖЬ. Например, =ВПР(123;A1:B100;2;ЛОЖЬ) гарантирует поиск именно значения 123, игнорируя соседние числа.
Если этот параметр пропущен или указан как ИСТИНА, ВПР может вернуть некорректное значение или ошибку, особенно при работе с несортированными столбцами. Проверка аргументов и установка точного совпадения решает большинство проблем, связанных с отсутствием результата.
Используется приблизительный поиск при несортированном столбце
Если параметр последнего аргумента ВПР установлен как ИСТИНА или пропущен, функция выполняет приблизительный поиск. В этом случае Excel предполагает, что столбец поиска отсортирован по возрастанию. При работе с несортированным столбцом ВПР может возвращать неверные значения или #Н/Д, даже если точное совпадение существует.
Проверить, отсортирован ли столбец, можно с помощью встроенной функции сортировки. Если сортировка отсутствует, либо необходимо отсортировать диапазон по возрастанию, либо изменить параметр ВПР на ЛОЖЬ для точного поиска. Это гарантирует, что функция будет искать строго совпадающее значение без зависимости от порядка данных.
Для больших таблиц и динамических диапазонов предпочтительно использовать точное совпадение, чтобы избежать ошибок, вызванных несортированными данными. Это особенно важно при автоматическом обновлении таблиц из внешних источников, где порядок записей может меняться.
Искомый столбец находится не первым в диапазоне ВПР
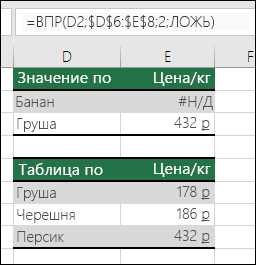
ВПР ищет совпадение только в первом столбце указанного диапазона. Если нужное значение находится во втором или третьем столбце, функция не сможет его найти и вернет #Н/Д.
Чтобы исправить эту проблему, можно использовать несколько подходов:
- Переставить столбцы так, чтобы искомый ключ находился первым в диапазоне.
- Использовать функцию ИНДЕКС совместно с ПОИСКПОЗ для поиска значения в любом столбце, независимо от его позиции.
- Создать вспомогательный столбец, который дублирует ключевые данные в первой позиции диапазона.
Важно при работе с большими таблицами проверять, что диапазон ВПР начинается с нужного столбца, иначе функция не сможет найти совпадение даже при полной идентичности данных.
Неверный номер столбца приводит к возврату ошибки
Аргумент номер_столбца в функции ВПР указывает, из какого столбца диапазона вернуть значение. Если указан столбец, которого нет в диапазоне, функция возвращает #ЗНАЧ! или #Н/Д.
Чтобы избежать ошибок, следует соблюдать несколько правил:
- Проверять, что номер столбца не превышает количество столбцов в диапазоне поиска.
- Использовать ПОСЛЕДНИЙ или динамическую ссылку через СТОЛБЕЦ, если структура таблицы может изменяться.
- При добавлении или удалении столбцов пересматривать аргумент номер_столбца, чтобы он соответствовал текущему диапазону.
Особенно важно при автоматизации или работе с большими данными, когда изменение структуры таблицы может привести к массовым ошибкам ВПР. Плановая проверка номеров столбцов снижает риск некорректных результатов.
Объединённые ячейки искажают структуру диапазона поиска
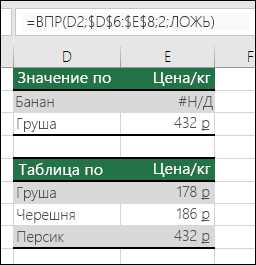
Объединённые ячейки создают разрыв логической структуры диапазона, который использует ВПР. Функция читает только верхнюю левую ячейку объединённого блока, игнорируя остальные, из-за чего поиск может возвращать #Н/Д даже при визуальном совпадении данных.
Чтобы исправить ситуацию, применяют несколько подходов:
- Разъединить объединённые ячейки и заполнить каждую отдельной копией значения.
- Использовать вспомогательные столбцы с дублированными ключевыми данными, чтобы диапазон поиска стал непрерывным.
- Проверять диапазоны перед применением ВПР, особенно при импортированных таблицах, где объединённые ячейки часто встречаются.
Систематическая проверка и исправление объединённых ячеек обеспечивает корректную работу ВПР и исключает ошибки, связанные с нарушением структуры диапазона.
Вопрос-ответ:
Почему ВПР возвращает #Н/Д, хотя значение точно присутствует в таблице?
Наиболее частая причина — несовпадение формата данных. Например, число может быть сохранено как текст, или дата имеет скрытый код времени. ВПР проверяет точное соответствие ячеек, поэтому даже визуально идентичные значения могут не совпадать. Проверка формата с помощью функции ТИП и приведение данных к одному формату через ЗНАЧ или СЖПРОБЕЛЫ помогает устранить проблему.
Как убрать лишние пробелы и невидимые символы, которые мешают ВПР найти совпадение?
Лишние пробелы и непечатаемые символы можно обнаружить с помощью функции ДЛСТР: если длина текста больше, чем видимое значение, есть лишние символы. Для их удаления используют СЖПРОБЕЛЫ для пробелов в начале и конце строки и комбинацию ПРОБЕЛЫСИМВОЛЫ с подстановкой символа 160 для скрытых пробелов. После очистки диапазона ВПР начинает корректно находить совпадения.
Почему ВПР не возвращает значение, если столбец поиска не первый в диапазоне?
ВПР ищет совпадение только в первом столбце указанного диапазона. Если нужное значение находится в другом столбце, функция не найдет его и покажет #Н/Д. Решение — переставить столбцы так, чтобы ключевой столбец был первым, либо использовать комбинацию функций ПОИСКПОЗ и ИНДЕКС, которая позволяет искать данные в любом столбце.
Как влияет использование объединённых ячеек на работу ВПР?
Объединённые ячейки создают разрыв логической структуры диапазона: ВПР читает только верхнюю левую ячейку блока. Остальные ячейки игнорируются, из-за чего функция может возвращать #Н/Д, даже если данные визуально совпадают. Решение — разъединить ячейки и заполнить каждую отдельным значением, либо использовать вспомогательные столбцы с дублирующими данными для корректного поиска.