Содержание статьи

DataFrame в библиотеке pandas представляет собой двумерную таблицу с метками строк и столбцов. Для работы с большими наборами данных важно точно выбирать нужные элементы, чтобы избежать лишних вычислений и ошибок. Обращение к данным может выполняться по именам столбцов, позициям или условиям фильтрации.
Методы loc и iloc позволяют извлекать значения строк и столбцов разными способами. loc использует метки индексов, а iloc – числовые позиции. Понимание различий между ними помогает предотвращать смещения данных при выборке и гарантирует корректность расчетов.
Для быстрого доступа к отдельным столбцам или набору строк можно применять прямое обращение по имени, срезы или булевы маски. Использование фильтров с условиями позволяет выбирать элементы, удовлетворяющие конкретным критериям, что сокращает объем обрабатываемых данных и упрощает последующую агрегацию.
Практическая работа с DataFrame требует аккуратного сочетания методов выбора элементов. Комбинации loc с булевыми масками, срезами и query обеспечивают точное извлечение данных для анализа, подготовки отчетов или построения визуализаций.
Доступ к отдельным значениям через loc
Метод loc используется для выборки данных по меткам индексов и именам столбцов. Для получения конкретного элемента синтаксис выглядит как df.loc[индекс, ‘имя_столбца’]. Например, df.loc[3, ‘Цена’] вернет значение в строке с индексом 3 и столбце «Цена».
Для одновременного доступа к нескольким элементам можно передавать списки меток: df.loc[[1,4], [‘Имя’,’Возраст’]] вернет подтаблицу с выбранными строками и столбцами. Такой подход уменьшает необходимость применения циклов и ускоряет обработку.
При использовании loc можно комбинировать выборку строк с условием: df.loc[df[‘Возраст’] > 30, ‘Имя’] вернет все имена, где значение возраста больше 30. Это позволяет извлекать только релевантные данные без дополнительной фильтрации.
Метод поддерживает также присваивание: df.loc[2, ‘Статус’] = ‘Активный’ изменяет конкретное значение напрямую. Такой способ полезен для корректировки отдельных ячеек без пересоздания всего DataFrame.
Использование iloc для позиционного обращения к данным
Метод iloc позволяет выбирать данные по числовым позициям строк и столбцов. Синтаксис выглядит как df.iloc[номер_строки, номер_столбца]. Например, df.iloc[2, 1] вернет значение в третьей строке и втором столбце, независимо от имени столбца.
Для извлечения нескольких строк или столбцов можно использовать срезы: df.iloc[0:5, 1:3] вернет подтаблицу с первыми пятью строками и вторым и третьим столбцами. Срезы удобны для выборки подряд идущих элементов без знания их меток.
С помощью iloc легко менять значения конкретных ячеек: df.iloc[0, 2] = 150 присвоит новое значение элементу в первой строке третьего столбца. Такой подход полезен при пакетной обработке данных, когда позиция известна заранее.
Метод поддерживает комбинирование списков индексов и срезов: df.iloc[[0,2,4], 1:3] вернет выбранные строки и столбцы. Это упрощает выбор данных по сложным позиционным схемам без обращения к именам столбцов.
Обращение к столбцам по имени
Для извлечения столбца из DataFrame используется синтаксис df[‘Имя_столбца’]. Например, df[‘Цена’] вернет Series с данными из столбца «Цена». Это позволяет быстро получить доступ к конкретной информации без перебора строк.
Для работы с несколькими столбцами сразу применяют список имен: df[[‘Имя’,’Возраст’]]. Результатом будет подтаблица с выбранными столбцами, что удобно при подготовке данных для анализа или визуализации.
Столбцы по имени можно изменять напрямую: df[‘Статус’] = ‘Активен’ присвоит новое значение всем строкам. Также возможно присваивание серии или массива той же длины: df[‘Скидка’] = [10,15,20], что позволяет обновлять данные по определенным правилам.
Для динамического выбора столбцов используют переменные: col = ‘Цена’; df[col]. Такой подход полезен при построении функций и обработке DataFrame с изменяющимися названиями столбцов.
Выбор нескольких строк и столбцов одновременно

Для одновременного извлечения нескольких строк и столбцов применяются методы loc и iloc. Они позволяют комбинировать выборку по меткам или позициям, избегая лишних циклов.
Примеры использования loc:
- df.loc[[0,2,5], [‘Имя’,’Возраст’]] – вернет строки с индексами 0, 2 и 5 и столбцы «Имя» и «Возраст».
- df.loc[1:4, [‘Цена’,’Скидка’]] – выберет строки с индексами от 1 до 4 и указанные столбцы.
Примеры использования iloc для позиционной выборки:
- df.iloc[[0,3,5], [1,2]] – строки по позициям 0, 3, 5 и столбцы по позициям 1 и 2.
- df.iloc[2:6, 0:3] – подтаблица из строк с 2 по 5 и первых трех столбцов.
Для условного выбора можно комбинировать булевы маски с loc:
- df.loc[df[‘Возраст’]>25, [‘Имя’,’Статус’]] – выберет строки, где возраст больше 25, и только указанные столбцы.
Такой подход сокращает объем обрабатываемых данных и упрощает последующую агрегацию или визуализацию.
Фильтрация данных с булевыми масками
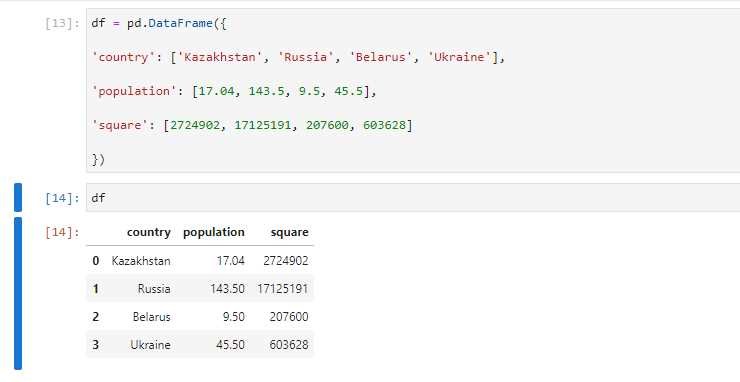
Булевы маски позволяют выбирать строки DataFrame, соответствующие заданным условиям. Создается маска через сравнение столбца с значением: mask = df[‘Возраст’] > 30. Результатом будет Series из True и False для каждой строки.
Для фильтрации применяют маску к DataFrame: df[mask]. Этот синтаксис вернет только строки, где маска равна True. Например, df[df[‘Статус’]==’Активный’] выберет всех активных пользователей.
Можно комбинировать условия с логическими операторами:
- df[(df[‘Возраст’] > 25) & (df[‘Город’]==’Москва’)] – строки с возрастом больше 25 и городом «Москва».
- df[(df[‘Сумма’] < 1000) | (df[‘Скидка’] > 10)] – строки, где сумма меньше 1000 или скидка больше 10.
Булевы маски можно сохранять в переменные для повторного использования и комбинировать с loc для выбора конкретных столбцов: df.loc[mask, [‘Имя’,’Сумма’]]. Это ускоряет обработку данных при работе с большими таблицами.
Извлечение данных по условию с query

Метод query позволяет выбирать строки DataFrame на основе текстового выражения. Синтаксис: df.query(«условие»). Например, df.query(«Возраст > 30») вернет все строки, где возраст больше 30.
Можно комбинировать несколько условий с логическими операторами and, or и not:
df.query("Возраст > 25 and Город == 'Москва'")
Этот запрос вернет строки, где возраст больше 25 и город совпадает с «Москва».
Для выбора конкретных столбцов используют комбинацию с loc или создают подтаблицу после query:
| Пример | Результат |
|---|---|
| df.query(«Сумма > 1000»)[[‘Имя’,’Сумма’]] | Строки с суммой больше 1000, отображаются только столбцы «Имя» и «Сумма» |
| df.query(«Статус == ‘Активный’ and Скидка > 10») | Все активные пользователи с скидкой больше 10 |
Метод query ускоряет фильтрацию при сложных условиях, делая код компактным и удобным для динамических запросов.
Обращение к элементам с помощью атрибутов DataFrame
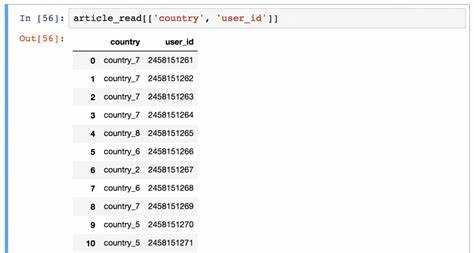
DataFrame позволяет получать доступ к столбцам через атрибуты, используя синтаксис df.Имя_столбца. Например, df.Цена вернет Series с данными столбца «Цена». Этот метод удобен при быстром обращении к одиночным столбцам без квадратных скобок.
Атрибутный доступ поддерживает большинство операций, доступных для Series: фильтрацию, арифметические действия, агрегирование. Например, df.Количество.sum() вернет сумму всех значений в столбце «Количество».
Для изменения данных используется присваивание через атрибут: df.Скидка = df.Скидка + 5. Это увеличит значения в столбце «Скидка» на 5 для всех строк.
Следует учитывать ограничения: атрибутный доступ работает только если имя столбца является допустимым идентификатором Python (без пробелов и специальных символов). Для столбцов с пробелами или конфликтующими именами рекомендуется использовать df[‘Имя_столбца’].
Использование срезов для строк и столбцов
Срезы позволяют выбирать последовательные строки или столбцы без явного указания индексов каждого элемента. Синтаксис выглядит как df[начало:конец] для строк и df.iloc[:, начало:конец] для столбцов.
Примеры выбора строк:
- df[0:5] – строки с индексами от 0 до 4.
- df[2:10:2] – каждая вторая строка с 2-й по 9-ю.
Примеры выбора столбцов через iloc:
- df.iloc[:, 0:3] – первые три столбца для всех строк.
- df.iloc[:, 1:5:2] – второй и четвертый столбцы.
Срезы можно комбинировать для выбора подтаблицы:
- df.iloc[0:5, 1:4] – строки с 0 по 4 и столбцы со 2-го по 4-й.
- df.loc[2:6, ‘Имя’:’Сумма’] – строки с индексами 2–6 и столбцы от «Имя» до «Сумма».
Использование срезов ускоряет обработку данных и упрощает работу с подтаблицами при подготовке аналитики или построении отчетов.
Вопрос-ответ:
Как получить значение конкретной ячейки в DataFrame?
Для извлечения значения используйте метод loc по меткам или iloc по позициям. Например, df.loc[3, ‘Цена’] вернет значение в строке с индексом 3 и столбце «Цена». Альтернативно, df.iloc[3, 2] вернет значение по позиции третьей строки и второго столбца.
Можно ли одновременно выбрать несколько строк и столбцов?
Да, это можно сделать через loc или iloc. Например, df.loc[[1,4,5], [‘Имя’,’Возраст’]] вернет подтаблицу с указанными строками и столбцами. Позиционный аналог через iloc: df.iloc[[0,2,3], 1:3]. Такой метод позволяет извлекать подмножества данных без циклов.
Как фильтровать строки по условию?
Используйте булевы маски. Например, df[df[‘Возраст’] > 30] вернет все строки, где возраст больше 30. Для сложных условий применяют логические операторы: df[(df[‘Возраст’] > 25) & (df[‘Город’]==’Москва’)]. Маски можно комбинировать с loc для выбора определенных столбцов.
В чем отличие обращения к столбцу по имени и через атрибут DataFrame?
Обращение через квадратные скобки, например df[‘Цена’], работает с любыми именами столбцов. Атрибутный способ df.Цена удобен для быстрого доступа, но работает только если имя столбца является допустимым идентификатором Python, без пробелов и специальных символов.
Как использовать метод query для выборки данных?
Метод query позволяет писать условия в виде строки: df.query(«Возраст > 25 and Город==’Москва'»). Он возвращает строки, удовлетворяющие условиям. Для выбора конкретных столбцов после query используют подтаблицу: df.query(«Сумма > 1000»)[[‘Имя’,’Сумма’]]. Это ускоряет работу с фильтрацией и упрощает синтаксис сложных условий.
Как выбрать несколько строк и столбцов в DataFrame одновременно?
Для выбора подмножества данных используйте loc или iloc. Через loc можно указать список индексов строк и список имен столбцов: df.loc[[0,2,5], [‘Имя’,’Возраст’]] вернет строки с индексами 0, 2 и 5 и столбцы «Имя» и «Возраст». Через iloc выбор происходит по позициям: df.iloc[[0,3,4], 1:3] вернет строки по позициям 0, 3, 4 и второй и третий столбцы. Такой подход позволяет быстро работать с подтаблицами без циклов и упрощает анализ данных.