Содержание статьи

Поиск на сайте начинается не с алгоритмов и баз данных, а с корректно подготовленной HTML-разметки. Именно HTML определяет, какие данные доступны для поиска, как они структурированы и в каком виде передаются обработчику запроса. Неправильное использование тегов, отсутствие семантики или хаотичная разметка напрямую ограничивают точность и полноту результатов, независимо от выбранной серверной или клиентской логики.
HTML участвует в поиске на двух ключевых этапах: ввод запроса пользователем и представление результатов. Через элементы <form> и <input> формируется поисковый запрос, а атрибуты name, value и method задают структуру данных, с которой далее работает поиск. Ошибки на этом уровне приводят к потере параметров, невозможности фильтрации и некорректной индексации контента.
Не менее важна роль HTML в подготовке самого контента. Использование семантических тегов, логичных заголовков и структурированных текстовых блоков позволяет поисковому механизму сайта точно определять границы документов, фрагменты для выдачи и релевантные совпадения. Например, контент, помещённый в навигационные или служебные блоки, не должен смешиваться с основным текстом, иначе поиск будет возвращать нерелевантные результаты.
HTML не выполняет поиск самостоятельно, но задаёт жёсткие рамки, внутри которых этот поиск возможен. Понимание принципов работы HTML в контексте поиска позволяет заранее исключить архитектурные ошибки, сократить объём дополнительной логики и получить предсказуемое поведение поисковой системы на сайте.
Вот детальный план информационной статьи с прикладным фокусом и 6 узкими заголовками , без подзаголовков:

Роль HTML-разметки в организации поисковых данных на сайте – раздел раскрывает, какие именно элементы HTML формируют основу для поиска: текстовые узлы, атрибуты, порядок вложенности тегов. Делается акцент на том, как семантическая разметка влияет на корректное извлечение контента и исключение служебных блоков из поисковой выборки.
Использование форм HTML для ввода поисковых запросов – описывается практическая реализация поисковой формы: выбор типа input, задание атрибута name, использование placeholder и влияние method=»get» на формирование URL запроса. Указывается, какие ошибки в разметке делают поиск нефункциональным.
Передача поискового запроса из HTML в обработчик поиска – рассматривается, как данные из HTML-формы превращаются в параметры, доступные серверному или клиентскому коду. Раздел концентрируется на структуре запроса, кодировке символов и ограничениях, задаваемых HTML на этапе передачи данных.
HTML-структура страницы с результатами поиска – разбирается построение HTML-документа с результатами: использование списков, заголовков и контейнеров для обеспечения читаемости и возможности повторного анализа данных поиском или скриптами.
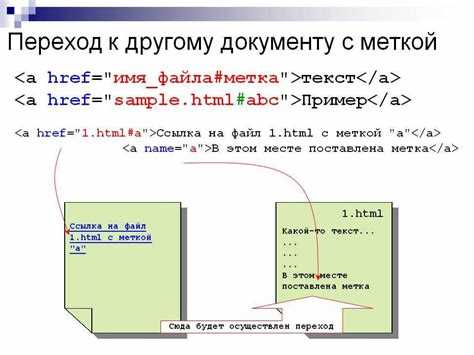
Выделение найденных фрагментов средствами HTML – описываются способы пометки совпадений с поисковым запросом через HTML-теги без вмешательства в логику поиска. Делается упор на корректное внедрение разметки без нарушения структуры документа.
Ограничения HTML в реализации логики поиска на сайте – фиксируются границы ответственности HTML: отсутствие возможностей фильтрации, ранжирования и анализа данных. Раздел подчёркивает, какие задачи невозможно решить на уровне разметки и почему это важно учитывать при проектировании поиска.
Роль HTML-разметки в организации поисковых данных на сайте

HTML-разметка определяет, какие фрагменты контента доступны для поиска и в каком виде они могут быть извлечены. Поисковый механизм сайта работает с уже сформированным DOM, поэтому логика поиска напрямую зависит от структуры документа, вложенности элементов и типов используемых тегов.
Основная задача HTML на этом этапе – чётко разделить содержательный и служебный контент. Для этого необходимо:
- размещать основной текст внутри логически замкнутых контейнеров, а не в общих div без назначения;
- изолировать навигацию, фильтры и вспомогательные блоки от текстов, которые должны участвовать в поиске;
- избегать дублирования одного и того же текста в разных частях документа.
Семантические теги упрощают определение значимости данных. Их корректное применение позволяет поиску на сайте понимать, где находится ключевая информация, а где – второстепенные элементы:
- <main> – контейнер контента, который должен участвовать в поиске в первую очередь;
- <article> – самостоятельные единицы текста, удобные для индексации;
- <section> – логические блоки внутри материала;
- <header> и <footer> – области, которые часто требуется исключать из поиска.
Заголовочная структура влияет на точность выдачи. Использование <h1>–<h6> позволяет определить иерархию смысловых блоков и формировать релевантные фрагменты результатов. Поиск, ориентирующийся на DOM, может использовать заголовки для генерации сниппетов и уточнения контекста совпадений.
Атрибуты HTML также участвуют в организации данных для поиска. Практически значимыми являются:
- атрибут data-* для хранения дополнительных параметров, используемых при фильтрации;
- id и class для точечного выбора элементов при клиентском поиске;
- атрибут hidden для исключения элементов из видимого и поискового пространства.
Текстовый контент должен присутствовать в HTML в явном виде. Контент, подгружаемый только через скрипты или внедрённый в нестандартные структуры, усложняет или делает невозможным его использование в поиске. Для устойчивой работы поисковой системы важно, чтобы ключевые данные были доступны в DOM сразу после загрузки страницы.
Грамотно организованная HTML-разметка снижает сложность логики поиска, уменьшает объём дополнительной обработки и обеспечивает стабильные результаты даже при простых алгоритмах сопоставления запросов.
Использование форм HTML для ввода поисковых запросов

Для текстового поиска используется элемент <input type=»search»> или <input type=»text»>. Атрибут name обязателен, так как именно он формирует имя параметра в запросе. Отсутствие name делает введённое значение недоступным для поиска независимо от содержимого поля.
Атрибут method формы влияет на формат передачи данных. Значение get предпочтительно для поиска, так как:
– позволяет формировать URL с параметрами запроса;
– обеспечивает возможность повторного открытия результатов;
– упрощает отладку и анализ поисковых запросов.
При использовании method=»get» важно учитывать кодировку. Значение атрибута accept-charset должно соответствовать кодировке сайта, иначе поисковые запросы на кириллице будут искажены при передаче.
Атрибут action задаёт адрес страницы с результатами поиска. Он должен вести на документ, способный корректно обработать параметры формы. Отправка формы на текущую страницу оправдана только при заранее предусмотренной логике обработки запроса.
Для повышения точности поиска следует ограничивать ввод лишних данных. Это достигается за счёт:
– указания атрибута placeholder с форматом допустимого запроса;
– отключения автокоррекции и автозамены, если они искажают термины;
– использования одного поля ввода для базового поиска без перегрузки формы.
Кнопка отправки формы реализуется через <button type=»submit»> или <input type=»submit»>. Явное указание type исключает случайную отправку формы при взаимодействии с другими элементами и обеспечивает предсказуемое поведение поиска.
Корректно собранная HTML-форма обеспечивает стабильную передачу поискового запроса, минимизирует ошибки на этапе ввода и создаёт основу для точной и воспроизводимой работы поисковой системы сайта.
Передача поискового запроса из HTML в обработчик поиска
После отправки HTML-формы поисковый запрос преобразуется в набор параметров, доступных обработчику поиска. Формат этих данных полностью определяется разметкой формы: значениями атрибутов name, method и action. Любая ошибка на этом уровне приводит к тому, что обработчик получает неполные или некорректные данные.
При использовании method=»get» параметры добавляются к URL в виде строки запроса. Это позволяет обработчику однозначно извлечь поисковый запрос, использовать его для формирования результатов и повторно воспроизвести поиск при обновлении страницы или переходе по ссылке.
Структура передаваемых данных формируется по строгим правилам. Каждый элемент формы с атрибутом name создаёт отдельный параметр, значение которого берётся из value поля ввода. Ниже приведён пример типовой передачи поискового запроса.
| Элемент формы | Атрибут name | Передаваемое значение |
|---|---|---|
| Поле ввода | q | текст поискового запроса |
| Форма | method | get |
| Форма | action | адрес страницы с результатами |
Обработчик поиска не анализирует HTML целиком, он работает только с полученными параметрами. Поэтому важно исключить:
– поля без атрибута name;
– динамическое изменение name через скрипты без синхронизации с обработчиком;
– использование одинаковых имён параметров для разных целей.
Кодировка данных передаётся в соответствии с настройками формы и страницы. Если кодировка не согласована, поисковый запрос на кириллице может быть искажён ещё до начала обработки. Для стабильной передачи необходимо, чтобы кодировка HTML-документа и ожидаемая кодировка обработчика совпадали.
При клиентской обработке поиска данные извлекаются из строки запроса или из объекта формы, но источник остаётся тем же – HTML-разметка. Чётко определённая структура параметров упрощает разбор запроса, снижает количество проверок и ускоряет обработку.
Грамотная передача поискового запроса из HTML в обработчик обеспечивает предсказуемую работу поиска, корректную интерпретацию пользовательского ввода и стабильное формирование результатов независимо от выбранной технологии обработки.
HTML-структура страницы с результатами поиска
Страница с результатами поиска должна иметь предсказуемую и однозначную HTML-структуру, так как она используется не только для отображения данных пользователю, но и для повторной обработки результатов скриптами и поисковыми механизмами сайта. Основной контейнер результатов должен быть отделён от служебных элементов и содержать только релевантные совпадения.
– заголовок найденного материала;
– краткий текстовый фрагмент с совпадением;
– ссылка на исходную страницу или раздел.
Заголовок результата следует размещать в отдельном теге заголовка соответствующего уровня. Это сохраняет иерархию документа и позволяет однозначно определить границы каждого результата при последующей обработке DOM.
Фрагмент текста, отображающий совпадение с запросом, должен формироваться из основного контента страницы, а не из служебных или навигационных блоков. В HTML-разметке такой фрагмент должен быть представлен как обычный текстовый узел без вложения в элементы, не предназначенные для контента.
Результаты поиска целесообразно объединять в список или общий контейнер. Это позволяет:
– легко определять количество найденных элементов;
– реализовывать постраничную навигацию;
– выполнять повторную фильтрацию без пересборки страницы.
Служебная информация, такая как количество найденных результатов или сообщение об отсутствии совпадений, должна быть вынесена за пределы контейнера с результатами. Это предотвращает её случайное включение в поисковую выдачу при повторных запросах.
HTML-структура страницы должна оставаться стабильной независимо от количества результатов. Даже при отсутствии совпадений контейнеры и ключевые элементы должны присутствовать в DOM, что упрощает обработку состояния поиска и исключает ошибки в клиентской логике.
Чётко организованная HTML-разметка страницы результатов обеспечивает корректное отображение данных, предсказуемую работу поиска и возможность масштабирования функциональности без изменения базовой структуры документа.
Выделение найденных фрагментов средствами HTML
Выделение совпадений в результатах поиска реализуется на уровне HTML-разметки после обработки запроса. На этом этапе задача состоит не в поиске, а в точечном внедрении тегов, которые визуально и структурно обозначают найденные фрагменты без изменения исходного смысла текста.
Наиболее подходящим элементом для такой задачи является тег <mark>. Он предназначен для логического выделения частей текста и не нарушает структуру документа. Использование <mark> предпочтительно по следующим причинам:
- не изменяет семантику окружающего контента;
- может применяться к отдельным словам и фразам;
- легко удаляется или заменяется при повторном поиске.
В случаях, когда требуется дополнительный контроль над выделением, допустимо использование <span> с чётко заданным назначением. Такой подход оправдан, если необходимо отличать разные типы совпадений, например точные и частичные.
При внедрении HTML-выделений важно соблюдать порядок операций:
- сначала формируется чистый текстовый фрагмент результата;
- затем выполняется поиск совпадений внутри этого текста;
- после этого в нужных позициях добавляются HTML-теги выделения.
Нельзя добавлять теги выделения внутрь существующих HTML-элементов без проверки вложенности. Вмешательство в структуру ссылок, заголовков или других контейнеров может привести к некорректному DOM и ошибкам отображения.
Выделяться должен только тот текст, который реально совпадает с поисковым запросом. Не допускается маркировка соседних слов или целых абзацев, так как это снижает точность восприятия результатов и усложняет повторную обработку данных.
Для корректной работы повторных запросов выделенные фрагменты должны быть легко очищаемыми. Это достигается за счёт использования минимального набора HTML-тегов без вложенных элементов и дополнительных атрибутов.
Грамотное выделение найденных фрагментов средствами HTML повышает читаемость результатов, не перегружает разметку и сохраняет стабильную структуру страницы при любых поисковых запросах.
Ограничения HTML в реализации логики поиска на сайте
HTML предназначен для описания структуры документа и не содержит механизмов для выполнения поисковых операций. Он не способен анализировать текст, сравнивать строки, учитывать морфологию или определять релевантность совпадений. Любые попытки реализовать поиск исключительно средствами разметки приводят к статичным и нефункциональным решениям.
HTML не поддерживает работу с условиями и состояниями. Невозможно средствами разметки определить, какие элементы должны быть включены в результаты поиска, как сортировать найденные данные или как реагировать на изменение поискового запроса. Эти задачи всегда требуют участия клиентского или серверного кода.
Ограничения HTML проявляются и в работе с данными. Разметка не умеет:
– хранить поисковые индексы;
– выполнять фильтрацию по значениям;
– обрабатывать частичные совпадения и опечатки;
– учитывать синонимы и формы слов.
HTML также не предоставляет средств для управления приоритетами контента. Все элементы документа равнозначны с точки зрения логики, если не подключены дополнительные механизмы. Это означает, что разметка не может самостоятельно определить, какие результаты важнее и в каком порядке их показывать.
Динамическое обновление результатов поиска невозможно без внешней логики. HTML не реагирует на ввод пользователя, не пересчитывает данные и не обновляет содержимое страницы. Даже базовое обновление результатов требует повторной загрузки документа или вмешательства скриптов.
Ещё одно ограничение связано с обработкой больших объёмов контента. HTML не оптимизирован для поиска по длинным документам или множеству страниц. Без предварительной подготовки данных и отдельного механизма поиска разметка становится лишь пассивным источником текста.
При проектировании поиска HTML следует рассматривать как инструмент подготовки и представления данных. Попытка возложить на него функции анализа и принятия решений усложняет архитектуру и приводит к нестабильной работе. Чёткое разделение ролей между HTML и логикой поиска является обязательным условием масштабируемого решения.
Вопрос-ответ:
Можно ли реализовать поиск по сайту только с помощью HTML без JavaScript и сервера?
HTML не выполняет поиск и не обрабатывает запросы. Он способен лишь передать введённые данные и отобразить заранее подготовленный результат. Поиск без скриптов возможен только в виде статических страниц с заранее сформированными ссылками или якорями, что подходит лишь для очень простых случаев и не масштабируется.
Почему поисковая форма отправляет запрос, но результаты всегда пустые?
Чаще всего причина связана с HTML-разметкой формы. Отсутствие атрибута name у поля ввода, несовпадение ожидаемого имени параметра на стороне обработчика или неправильный method формы приводят к тому, что запрос фактически не передаётся. Проверка структуры HTML — первый шаг при отладке такой ситуации.
Как HTML-разметка влияет на точность результатов поиска на сайте?
Поиск работает с DOM-структурой, сформированной HTML. Если основной текст смешан с навигацией, повторяется в разных блоках или не отделён семантически, поиск начинает находить нерелевантные совпадения. Чёткая разметка позволяет заранее ограничить область анализа и снизить количество ложных результатов.
Как правильно выделять найденные слова, чтобы не ломать разметку страницы?
Выделение должно выполняться только после формирования итогового текста результата. Вставка тегов внутрь ссылок, заголовков или вложенных элементов без проверки приводит к ошибкам DOM. Использование тега <mark> или простого span вокруг совпадений позволяет сохранить структуру и легко очищать выделение при новом запросе.
Нужно ли скрывать служебные элементы страницы от поиска и как это связано с HTML?
Да, иначе поиск начинает возвращать пункты меню, кнопки и технический текст. HTML позволяет заранее разделить такие элементы через контейнеры, атрибут hidden или логическую структуру документа. Это снижает нагрузку на обработчик поиска и делает выдачу предсказуемой.
Почему поиск по сайту может находить лишний текст из меню и подвала, и как это связано с HTML?
Поиск анализирует DOM, сформированный HTML-разметкой, а не визуальное представление страницы. Если навигация, подвал и основной контент находятся в одном уровне вложенности или не разделены логическими контейнерами, поисковый механизм воспринимает их как равнозначный текст. В результате в выдачу попадают пункты меню, ссылки и служебные надписи. Решение заключается в чётком разделении структуры: основной контент должен находиться в отдельном контейнере, а навигационные и вспомогательные блоки — быть изолированы. Тогда поиск сможет работать только с нужной частью документа без дополнительных проверок.