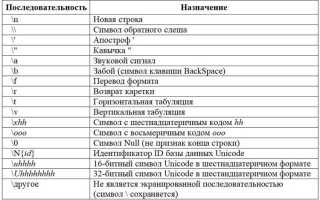
Строки в Python хранятся как последовательности символов Unicode, а двоичный код формируется только после преобразования строки в байты. Это означает, что перед переводом в биты необходимо явно выбрать кодировку, чаще всего UTF-8. Один и тот же символ может занимать от одного до четырёх байт, и это напрямую влияет на итоговую двоичную строку, что критично при передаче данных или сравнении хэшей.
На практике перевод строки в двоичный код выполняется в несколько шагов: сначала используется метод encode() для получения байтовой последовательности, затем каждый байт преобразуется в двоичный формат с фиксированной длиной, как правило, 8 бит. Отсутствие выравнивания по длине делает результат непригодным для анализа и обратного преобразования.
Понимание различий между ASCII-символами, многобайтовыми Unicode-символами и управляющими кодами позволяет избежать типичных ошибок, таких как потеря данных или некорректная интерпретация результата. В статье подробно рассматриваются прикладные приёмы перевода строк в двоичный код на Python с акцентом на предсказуемый и проверяемый результат.
Получение байтовой последовательности строки с помощью encode()
Метод encode() выполняет ключевую операцию – преобразует строку Python, представленную в Unicode, в объект типа bytes. Именно байты служат исходными данными для последующего перевода в двоичный код. Без этого шага работа с битами невозможна, так как строка не имеет прямого бинарного представления.
Базовый вызов выглядит следующим образом:
text = "Python"
data = text.encode("utf-8")Результатом будет последовательность байтов, где каждый элемент – целое число от 0 до 255. Для строки «Python» метод вернёт шесть байтов, так как все символы входят в диапазон ASCII и кодируются одним байтом в UTF-8. Это упрощает анализ, но не отражает поведение для большинства нелатинских символов.
Выбор кодировки напрямую влияет на длину и содержимое байтового массива. Например, символ «Я» в UTF-8 занимает два байта, а в UTF-16 – четыре:
"Я".encode("utf-8") # b'\xd0\xaf'
"Я".encode("utf-16") # b'\xff\xfe/\x04'Для задач, связанных с обменом данными, рекомендуется всегда явно указывать кодировку и не полагаться на значения по умолчанию. Это исключает расхождения между системами и версиями интерпретатора.
Метод encode() поддерживает параметр обработки ошибок, который позволяет контролировать поведение при недопустимых символах. На практике чаще всего используется режим ‘strict’, так как он гарантирует целостность данных и немедленно сигнализирует о проблеме:
text.encode("utf-8", errors="strict")После получения объекта bytes каждый байт можно безопасно и однозначно перевести в двоичное представление, что делает encode() обязательным этапом при работе с бинарным кодированием строк.
Преобразование символов ASCII в двоичное представление
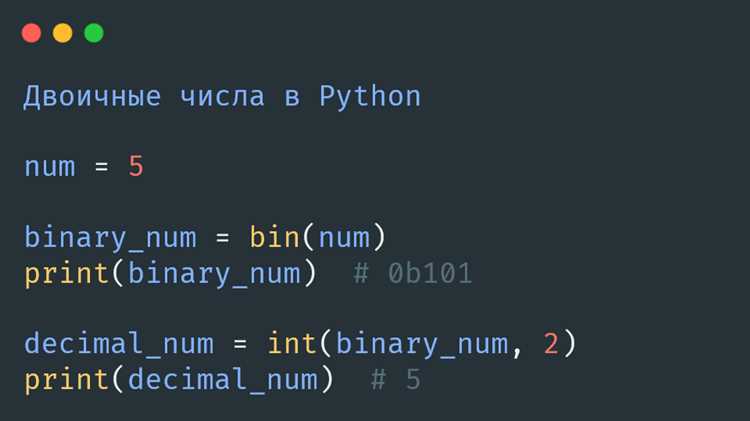
Символы ASCII занимают диапазон кодов от 0 до 127 и кодируются одним байтом, что делает их удобной отправной точкой для понимания перевода строки в двоичный код. В Python каждый такой символ после кодирования в UTF-8 соответствует одному байту, значение которого напрямую переводится в двоичную форму.
После получения объекта bytes каждый байт представляет собой целое число. Например, символ ‘A’ имеет ASCII-код 65, а его двоичное представление – 01000001. В Python это выглядит следующим образом:
byte = ord('A')
binary = format(byte, '08b')Использование функции format() с шаблоном ’08b’ гарантирует фиксированную длину в 8 бит. Отсутствие ведущих нулей нарушает структуру данных и затрудняет обратное преобразование, поэтому выравнивание по байту является обязательным.
При работе со строкой каждый символ ASCII обрабатывается отдельно. Практический вариант – итерироваться по байтовой последовательности, а не по самой строке:
text = "ABC"
binary_list = [format(b, '08b') for b in text.encode('ascii')]Такой подход исключает неоднозначность и гарантирует соответствие между символом, его числовым кодом и двоичным представлением. Для ASCII-строк использование кодировки ‘ascii’ предпочтительнее, так как она сразу выявляет символы вне допустимого диапазона.
Понимание этого механизма позволяет точно контролировать структуру бинарных данных и служит основой для работы с более сложными кодировками, где один символ может быть представлен несколькими байтами.
Работа с Unicode-строками и кодировкой UTF-8

Unicode-строки в Python представляют собой последовательности символов, не привязанные к фиксированному размеру в памяти. При переводе таких строк в двоичный код используется кодировка UTF-8, где каждый символ занимает от одного до четырёх байт. Это означает, что длина двоичного результата не совпадает с количеством символов в исходной строке.
При вызове метода encode с указанием UTF-8 каждый символ преобразуется в один или несколько байтов. Например, кириллический символ «Ж» кодируется двумя байтами, а эмодзи – четырьмя. Проверить это можно напрямую, получив длину байтовой последовательности после кодирования.
Для корректного перевода в двоичный формат необходимо обрабатывать каждый байт отдельно, а не пытаться переводить символ целиком. После кодирования строка становится объектом bytes, элементы которого уже готовы к преобразованию в бинарное представление фиксированной длины.
Использование UTF-8 позволяет сохранить совместимость между системами и избежать потери данных при передаче строк, содержащих нелатинские символы. Жёсткая фиксация кодировки при вызове encode предотвращает расхождения в результатах и упрощает последующее декодирование двоичной последовательности обратно в строку.
При анализе или хранении бинарных данных важно учитывать, что один визуальный символ может соответствовать нескольким байтам. Игнорирование этого факта приводит к ошибкам при разборе битовых потоков и нарушает структуру данных.
Использование функции bin() для перевода байтов в двоичный вид
Функция bin() в Python применяется для преобразования целого числа в строковое представление в двоичной системе счисления. При работе с переводом строки в бинарный формат она используется на этапе обработки отдельных байтов, полученных после кодирования строки.
Каждый элемент объекта bytes – это число в диапазоне от 0 до 255. Передача такого значения в bin() возвращает строку, начинающуюся с префикса 0b. Например, для байта со значением 97 результат будет 0b1100001, что требует дополнительной обработки.
Основной недостаток bin() заключается в отсутствии выравнивания по длине. Биты возвращаются без ведущих нулей, поэтому полученная строка не соответствует стандартному восьмибитному формату. Это делает результат непригодным для прямого объединения в бинарную последовательность без предварительной нормализации.
| Исходный байт | Результат bin() | Корректный 8-битный вид |
| 65 | 0b1000001 | 01000001 |
| 97 | 0b1100001 | 01100001 |
Для приведения результата к фиксированной длине необходимо удалить префикс 0b и дополнить строку нулями слева. На практике bin() применяется редко в чистом виде и чаще используется для отладки или демонстрации бинарного значения байта.
При формировании двоичной строки из текста рекомендуется использовать bin() только в сочетании с дополнительной логикой выравнивания, иначе структура бинарных данных будет нарушена и станет нечитаемой при обратном преобразовании.
Форматирование двоичного кода до фиксированной длины

При переводе строки в двоичный код каждый байт должен быть представлен строго восемью битами. Если длина бинарной записи различается, восстановление исходных данных становится невозможным. Поэтому после получения двоичного значения требуется обязательное выравнивание.
Наиболее надёжный способ – использовать форматирование с указанием фиксированной длины. Для байтов применяется шаблон 08b, который гарантирует наличие ведущих нулей:
format(65, '08b') # 01000001При обработке байтовой последовательности важно соблюдать единый алгоритм для каждого элемента:
- принять байт как целое число;
- преобразовать его в двоичный вид;
- дополнить нулями слева до 8 бит;
- добавить результат в общую бинарную строку.
Альтернативный вариант – метод zfill(), который используется после удаления префикса 0b у результата bin():
bin(5)[2:].zfill(8) # 00000101Для Unicode-строк длина фиксируется не по символам, а по байтам, поэтому каждый байт форматируется независимо. При этом итоговая длина бинарной строки всегда кратна восьми.
При построении полной бинарной последовательности рекомендуется придерживаться следующего порядка действий:
- кодировать строку в bytes;
- итерироваться по байтам, а не по символам;
- применять единый шаблон форматирования;
- соединять фрагменты без разделителей.
Такой подход обеспечивает предсказуемую структуру данных и позволяет без потерь выполнить обратное преобразование в исходную строку.
Объединение двоичных значений символов в одну строку
После преобразования каждого байта строки в восьмибитное двоичное представление возникает задача собрать отдельные фрагменты в единую бинарную строку. Именно на этом этапе формируется итоговый результат, пригодный для передачи, хранения или последующего анализа.
Объединение выполняется строго в том порядке, в котором байты следуют в объекте bytes. Нарушение последовательности приводит к искажению данных и делает обратное декодирование невозможным. Разделители между байтами не используются, так как длина каждого блока заранее известна и равна 8 битам.
Типовой алгоритм выглядит следующим образом: байты кодированной строки преобразуются в бинарные блоки фиксированной длины, после чего объединяются методом join(). В результате получается одна строка, длина которой всегда кратна восьми.
| Символ | Байт | Двоичный блок |
| A | 65 | 01000001 |
| B | 66 | 01000010 |
После объединения для строки «AB» итоговая бинарная последовательность будет выглядеть как 0100000101000010. Отсутствие пробелов и служебных символов позволяет однозначно восстановить исходные байты, разбив строку на блоки по 8 бит.
При работе с Unicode-строками количество двоичных блоков может превышать число символов, так как один символ может быть представлен несколькими байтами. Поэтому объединение всегда выполняется на уровне байтов, а не символов исходной строки.
Сформированная бинарная строка служит универсальным представлением данных и может использоваться для обратного декодирования, побитовых операций или передачи через каналы, работающие только с двоичным форматом.
Обработка пробелов и специальных символов при переводе

Пробелы, знаки пунктуации и управляющие символы при переводе строки в двоичный код обрабатываются так же, как и обычные символы, но их байтовые значения часто остаются незамеченными. Например, пробел имеет код 32 и в двоичном виде представлен как 00100000, что важно учитывать при анализе структуры бинарной строки.
Символы перевода строки, табуляции и возврата каретки имеют собственные коды: \n соответствует 10, \t – 9, \r – 13. После кодирования в UTF-8 они занимают по одному байту, а их двоичное представление включается в общую последовательность без каких-либо исключений.
Особое внимание требуется при обработке специальных символов внутри строк, полученных из внешних источников. Наличие невидимых управляющих кодов можно выявить только после кодирования и перевода в бинарный формат, где каждый байт становится явно различимым.
При необходимости исключить пробелы или служебные символы из результата, фильтрация должна выполняться до этапа кодирования. Удаление или замена уже после формирования бинарной строки нарушает выравнивание по байтам и делает данные непригодными для обратного преобразования.
Для сохранения точного соответствия между исходной строкой и двоичным кодом рекомендуется переводить строку без предварительной очистки, а анализ содержимого выполнять на уровне байтов. Такой подход позволяет точно определить наличие специальных символов и избежать скрытых искажений данных.
Проверка корректности результата и обратное декодирование
После формирования двоичной строки необходимо убедиться, что она точно отражает исходные данные. Первым критерием корректности служит длина результата: она должна быть кратна восьми, так как каждый байт представлен восемью битами. Несоответствие этому правилу указывает на ошибку форматирования или потерю данных.
Далее выполняется разбиение бинарной строки на байтовые блоки и преобразование каждого блока обратно в числовое значение. Для этого каждый фрагмент длиной 8 бит интерпретируется как целое число в двоичной системе счисления.
Процедура обратного декодирования включает несколько последовательных шагов:
- разделить бинарную строку на блоки по 8 бит;
- преобразовать каждый блок в целое число;
- сформировать объект bytes из полученных значений;
- декодировать байты в строку с указанием исходной кодировки.
Для проверки соответствия результата исходной строке выполняется прямое сравнение строк после декодирования. Совпадение символов подтверждает, что двоичное представление построено корректно и не содержит смещений или лишних битов.
При работе с Unicode-строками особое внимание уделяется кодировке, используемой на этапе decode. Она должна полностью совпадать с кодировкой, применённой при encode, иначе восстановленная строка будет содержать искажённые символы или приведёт к ошибке.
Рекомендуется проверять корректность перевода на тестовых строках, включающих:
- латинские и кириллические символы;
- пробелы и знаки пунктуации;
- управляющие символы;
- многобайтовые Unicode-символы.
Такой контроль позволяет гарантировать, что двоичная строка пригодна для хранения и передачи без риска потери информации.
Вопрос-ответ:
Почему при переводе строки в двоичный код нельзя работать напрямую со строкой, минуя bytes?
Строка в Python — это набор Unicode-символов, а не байтов. У символов нет фиксированного бинарного размера, поэтому прямого соответствия битам не существует. Только после вызова encode() строка превращается в bytes, где каждый элемент — число от 0 до 255. Именно эти значения можно корректно перевести в двоичный вид без неоднозначностей.
Почему двоичная строка для Unicode-текста получается длиннее, чем количество символов?
В UTF-8 один символ может занимать от одного до четырёх байт. Кириллица кодируется двумя байтами, многие эмодзи — четырьмя. При переводе в двоичный формат каждый байт превращается в 8 бит, поэтому итоговая длина зависит от байтов, а не от числа визуальных символов.
Можно ли использовать bin() для получения готового двоичного кода строки?
bin() возвращает двоичное представление числа без фиксированной длины и с префиксом 0b. Для байта это приводит к отсутствию ведущих нулей. Без дополнительного форматирования такой результат нельзя объединять в единую бинарную строку, так как нарушается структура данных. bin() подходит только как промежуточный инструмент.
Почему нельзя удалять пробелы и управляющие символы уже после перевода в двоичный вид?
Удаление битов из готовой бинарной строки нарушает выравнивание по байтам. После этого невозможно определить границы исходных байтов, а обратное декодирование становится недостоверным. Если требуется очистка текста, её выполняют до кодирования в bytes.
Как проверить, что полученный двоичный код можно без ошибок преобразовать обратно в строку?
Бинарную строку делят на блоки по 8 бит, каждый блок переводят в число и собирают объект bytes. Затем выполняют decode с той же кодировкой, что использовалась при encode. Если восстановленная строка полностью совпадает с исходной, значит бинарное представление сформировано корректно.