Создание интерпретатора на языке C позволяет глубоко разобраться в том, как исходный текст программы превращается в выполняемые действия. В отличие от работы с готовыми виртуальными машинами или генераторами парсеров, здесь разработчик вручную реализует каждый этап: от чтения символов из файла до вычисления выражений в памяти процесса. Такой подход дает практическое понимание устройства языков программирования и ограничений низкоуровневой реализации.
В основе интерпретатора лежит четко определенный набор компонентов: лексический анализатор, синтаксический анализатор, структура абстрактного синтаксического дерева и механизм выполнения. При написании на C особое внимание уделяется управлению памятью: выделению узлов AST, хранению строковых литералов, освобождению ресурсов при ошибках разбора. Ошибки проектирования на этом этапе быстро приводят к утечкам памяти или неопределенному поведению, поэтому архитектура должна быть продумана заранее.
Практика показывает, что оптимальной отправной точкой является минимальный язык с выражениями, переменными и условными операторами. Такой набор позволяет отработать все ключевые механизмы интерпретации без усложнения синтаксиса. Использование рекурсивного спуска для парсинга упрощает отладку и делает код прозрачным, а таблица символов на базе хеш-таблицы или связного списка подходит для хранения переменных на раннем этапе.
В статье рассматривается полный цикл разработки интерпретатора, ориентированный на ручную реализацию всех этапов без сторонних библиотек. Примеры и рекомендации опираются на реальные ограничения языка C: отсутствие встроенных строк, необходимость явного контроля времени жизни объектов и работу с указателями. Такой разбор будет полезен тем, кто хочет понять внутреннее устройство языков программирования на уровне исходного кода и системных деталей.
Выбор минимального синтаксиса и формата исходного кода языка
Минимальный синтаксис должен покрывать полный цикл интерпретации, но оставаться компактным для ручной реализации. Практичный стартовый набор включает числовые литералы, идентификаторы, бинарные операторы +, —, *, /, оператор присваивания и скобки для управления приоритетом. Этого достаточно, чтобы проверить корректность лексического анализа, построение дерева выражений и вычисление результатов без усложнения грамматики.
Формат исходного кода лучше ограничить построчным текстом в ASCII или UTF-8 без поддержки юникодных идентификаторов. Такое ограничение упрощает чтение входного файла и позволяет сосредоточиться на логике интерпретатора, а не на кодировках. Разделение инструкций символом конца строки или точкой с запятой дает однозначное завершение выражений и облегчает восстановление после синтаксических ошибок.
Грамматику языка целесообразно описать в виде набора правил для рекурсивного спуска: выражение, терм, фактор. Такая структура напрямую отображается в функции на C и исключает необходимость генерации таблиц разбора. Приоритет операторов фиксируется порядком вызовов функций, что снижает риск логических ошибок при вычислении сложных выражений.
Комментарии стоит реализовывать в одном формате, например строки, начинающиеся с # или //, и полностью игнорировать их на этапе лексического анализа. Это позволяет тестировать интерпретатор на реальных примерах кода без влияния комментариев на синтаксис. Поддержка многострочных комментариев на начальном этапе не требуется и увеличивает сложность анализатора.
Каждое языковое решение должно проверяться на простоте разбора в терминах символов и токенов. Если конструкция требует просмотра нескольких токенов вперед или усложняет обработку ошибок, ее лучше исключить из минимальной версии языка. Такой подход ускоряет разработку и делает поведение интерпретатора предсказуемым уже на ранних этапах.
Реализация лексического анализатора с ручным разбором токенов
Лексический анализатор преобразует поток символов исходного файла в последовательность токенов, пригодных для синтаксического разбора. В реализации на C рационально работать напрямую с буфером символов, загруженным через fread или построчное чтение. Индекс текущей позиции и текущий символ должны храниться в структуре состояния лексера, чтобы упростить контроль переходов и возвратов.
Набор токенов следует зафиксировать заранее и представить в виде перечисления. Минимальный список обычно включает:
- числовые литералы (целые или с плавающей точкой);
- идентификаторы;
- операторы (+, —, *, /, =);
- скобки и разделители;
- признак конца входного потока.
Каждый токен должен сопровождаться значением и позицией в исходном тексте. Для чисел это обычно long или double, для идентификаторов – указатель на выделенную строку или срез исходного буфера. Хранение номера строки и столбца упрощает диагностику ошибок и не требует значительных затрат памяти.
Разбор выполняется посимвольно с использованием цикла и набора проверок:
- пропуск пробелов, табуляций и переводов строки;
- распознавание чисел через последовательное чтение цифр;
- распознавание идентификаторов по шаблону [a-zA-Z_][a-zA-Z0-9_]*;
- обработка одиночных символов операторов и скобок;
- фиксация неизвестных символов как ошибок.
Для числовых литералов полезно разделять целую и дробную части во время чтения, а преобразование выполнять через strtol или strtod. Такой подход упрощает контроль переполнения и позволяет корректно обрабатывать некорректные записи.
Комментарии должны отсеиваться на уровне лексера. После обнаружения начального маркера строка пропускается до символа конца строки без генерации токенов. Это исключает влияние комментариев на синтаксический анализ и снижает количество проверок на следующих этапах.
Интерфейс лексического анализатора обычно строится вокруг функций получения следующего токена и просмотра текущего без сдвига позиции. Такое разделение упрощает реализацию рекурсивного спуска и позволяет локализовать ошибки разбора в пределах одного модуля.
Построение синтаксического анализатора на основе рекурсивного спуска

Синтаксический анализатор на основе рекурсивного спуска напрямую отражает грамматику языка в виде набора функций на C. Каждое правило грамматики реализуется отдельной функцией, которая проверяет последовательность токенов и формирует узлы абстрактного синтаксического дерева. Такой подход позволяет работать без генераторов парсеров и полностью контролировать логику разбора.
Грамматику следует привести к форме без левой рекурсии, иначе парсер зациклится. Для арифметических выражений практична классическая иерархия:
- expression – обработка сложения и вычитания;
- term – обработка умножения и деления;
- factor – числа, идентификаторы и выражения в скобках.
Каждая функция должна:
- проверять ожидаемый тип текущего токена;
- потреблять токен при совпадении;
- создавать и возвращать узел AST;
- сообщать об ошибке при несоответствии.
Контроль токенов удобно реализовать через функции current_token и consume. Первая возвращает текущий токен без изменения состояния, вторая проверяет его тип и сдвигает позицию. Это снижает количество условных операторов внутри парсерных функций и упрощает чтение кода.
Для операторов с одинаковым приоритетом используется цикл, а не рекурсивный вызов. Например, выражение a — b + c разбирается последовательным созданием бинарных узлов, где левый операнд обновляется на каждом шаге. Такой прием предотвращает глубокую рекурсию и облегчает вычисление.
Ошибки синтаксиса должны фиксироваться сразу при обнаружении неожиданного токена. Практика показывает, что достаточно сохранить сообщение с указанием позиции и прервать разбор текущей конструкции. Попытки сложного восстановления на минимальном языке увеличивают код и редко оправдывают затраты.
Рекурсивный спуск особенно удобен для пошаговой отладки. Каждый уровень вызовов соответствует уровню грамматики, поэтому трассировка стека вызовов позволяет быстро определить, на каком правиле произошел сбой и какой токен стал причиной ошибки.
Описание структуры абстрактного синтаксического дерева в C

Абстрактное синтаксическое дерево представляет программу в виде связанной структуры узлов, где каждый элемент соответствует конкретной языковой конструкции. В реализации на C базовый узел удобно описывать структурой с обязательным полем типа, определяющим назначение узла: числовой литерал, идентификатор, бинарная операция или оператор присваивания. Это поле используется на всех этапах интерпретации для выбора корректной логики обработки.
Для хранения данных применяется комбинация struct и union. Такое решение позволяет описать разные варианты содержимого узла без дублирования памяти. Например, числовой узел хранит значение, а бинарный – указатели на левый и правый подузлы и код оператора. Выбор активного поля строго определяется типом узла, что требует аккуратной дисциплины при доступе к данным.
Каждый узел AST должен создаваться через отдельную функцию-фабрику. Внутри нее выполняется выделение памяти, инициализация типа и заполнение полей. Централизация создания узлов упрощает отладку и позволяет в одном месте добавить учет выделенной памяти или проверку ошибок malloc.
Связи между узлами реализуются исключительно через указатели. Для бинарных операций это два указателя, для унарных – один, для последовательностей инструкций – связный список или динамический массив указателей. Использование вложенных структур вместо универсальных контейнеров снижает накладные расходы и делает структуру дерева прозрачной для анализа.
Управление временем жизни AST требует явной стратегии освобождения памяти. Для этого обычно реализуется рекурсивная функция удаления узла, которая сначала освобождает все дочерние элементы, а затем сам узел. Такой порядок предотвращает утечки и гарантирует корректное завершение интерпретации даже при ошибках выполнения.
Организация таблицы символов и хранения переменных
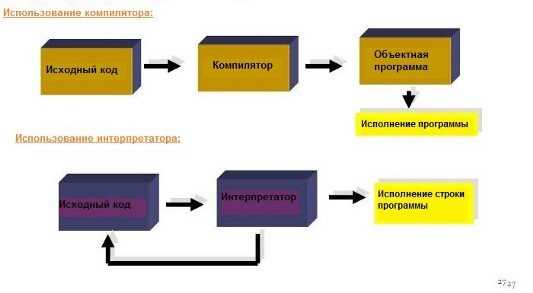
Таблица символов отвечает за сопоставление идентификаторов с их текущими значениями во время выполнения программы. В минимальном интерпретаторе на C достаточно структуры, хранящей имя переменной, тип значения и само значение. Идентификаторы обычно сохраняются как строки с динамическим временем жизни, чтобы избежать зависимостей от буфера лексера.
Для представления значения переменной удобно использовать union с полем для числового типа и возможными расширениями в будущем. Это позволяет унифицировать работу интерпретатора и сократить количество специализированных функций обработки. Тип значения фиксируется отдельным перечислением и проверяется при каждом чтении или записи.
Выбор структуры данных напрямую влияет на сложность операций доступа. На начальном этапе оправдано использование связного списка, где каждая запись содержит указатель на следующую. Поиск переменной выполняется линейно, что упрощает код и делает поведение предсказуемым при небольшом числе идентификаторов.
Добавление новой переменной должно выполняться строго в одном месте интерпретатора. При присваивании сначала выполняется поиск по имени, и если запись отсутствует, создается новая. Такой порядок исключает дублирование идентификаторов и позволяет централизованно контролировать выделение памяти.
Для поддержки областей видимости таблицу символов можно расширить вложенной структурой. Каждый блок кода получает собственный экземпляр таблицы с указателем на родительскую. При обращении к переменной поиск начинается с текущего уровня и продолжается вверх по цепочке, что корректно моделирует поведение локальных и глобальных переменных.
Освобождение памяти таблицы символов должно происходить синхронно с завершением области видимости. Рекурсивное удаление записей и связанных строк предотвращает накопление неосвобожденных объектов и упрощает диагностику ошибок, связанных с временем жизни переменных.
Выполнение выражений и операторов через обход AST
Выполнение программы в интерпретаторе сводится к рекурсивному обходу абстрактного синтаксического дерева. Для этого реализуется функция интерпретации, принимающая указатель на узел AST и контекст выполнения, включающий таблицу символов. Тип узла определяет ветку обработки и набор действий над данными.
Числовые узлы возвращают сохраненное значение без дополнительных вычислений. Узлы идентификаторов извлекают текущее значение из таблицы символов, при отсутствии записи фиксируется ошибка выполнения. Такой порядок позволяет выявлять обращения к неинициализированным переменным на этапе интерпретации.
Бинарные операции обрабатываются через последовательный вызов интерпретации для левого и правого подузлов. После получения операндов выполняется операция, соответствующая коду узла. Для арифметики важно явно проверять деление на ноль и корректно обрабатывать знаковые значения, чтобы избежать неопределенного поведения.
Оператор присваивания выполняется в два шага: вычисление правой части и запись результата в таблицу символов по имени, указанному в левом узле. Если переменная отсутствует, создается новая запись; если присутствует, значение перезаписывается. Такой механизм обеспечивает единообразную модель хранения данных.
Последовательности операторов выполняются в порядке их следования в дереве. Для этого используется связный список или массив узлов, обход которых происходит в цикле. Возвращаемое значение промежуточных выражений игнорируется, если конструкция не предполагает его использования.
Функция обхода AST должна быть чисто детерминированной и не изменять состояние вне переданного контекста. Это упрощает тестирование, позволяет локализовать ошибки выполнения и делает добавление новых типов узлов предсказуемым по объему изменений.
Обработка ошибок разбора и выполнения без аварийного завершения

Интерпретатор на C не должен завершать процесс при первой же ошибке, так как это затрудняет отладку и делает поведение непредсказуемым для пользователя. Вместо прямых вызовов exit или abort все этапы – лексический анализ, синтаксический разбор и выполнение – должны возвращать код состояния или структуру результата с признаком ошибки.
На этапе синтаксического анализа ошибка фиксируется при обнаружении неожиданного токена. Парсер сохраняет сообщение с указанием типа ошибки и позиции в исходном коде, после чего прекращает разбор текущей конструкции. AST в этом случае либо не создается, либо помечается как некорректный, что исключает его дальнейшее выполнение.
Ошибки выполнения возникают при интерпретации корректного дерева, но недопустимых действий: деление на ноль, обращение к неопределенной переменной, несовпадение типов. Такие ситуации обрабатываются внутри функции обхода AST путем возврата специального значения ошибки и остановки дальнейших вычислений.
Практика показывает, что удобно использовать единый механизм представления ошибок:
| Источник ошибки | Содержимое |
|---|---|
| Лексер | позиция символа, описание недопустимого символа |
| Парсер | тип ожидаемого токена, фактический токен, номер строки |
| Исполнение | тип операции, контекст переменной, текст ошибки |
Все ошибки должны передаваться вверх по стеку вызовов без потери информации. Это достигается возвратом структуры, содержащей код ошибки и сообщение, либо использованием глобального объекта состояния интерпретатора. Второй вариант упрощает сигнатуры функций, но требует строгой дисциплины доступа.
После фиксации ошибки интерпретатор обязан корректно освободить уже выделенные ресурсы: узлы AST, строки идентификаторов, записи таблицы символов. Отделение логики обработки ошибок от логики завершения программы позволяет вывести сообщение пользователю и безопасно завершить работу без повреждения памяти.
Вопрос-ответ:
Почему для интерпретатора на C часто выбирают минимальный язык, а не сразу сложный синтаксис?
Минимальный язык позволяет проверить всю цепочку: лексический анализ, разбор, построение AST и выполнение. При небольшом наборе конструкций проще отследить ошибки управления памятью и логические сбои в парсере. Добавление новых элементов языка после этого сводится к расширению уже работающих механизмов, а не к переписыванию архитектуры.
Нужно ли использовать генераторы парсеров или лучше писать разбор вручную?
При обучающем или исследовательском проекте ручная реализация дает полный контроль над тем, как обрабатываются токены и ошибки. Рекурсивный спуск легко сопоставляется с грамматикой и хорошо читается в коде на C. Генераторы оправданы при больших языках, но для первого интерпретатора они скрывают значительную часть логики.
Как избежать утечек памяти при работе с AST и таблицей символов?
Каждый объект должен иметь четко определенное место создания и уничтожения. Для AST применяется рекурсивное освобождение снизу вверх, для таблицы символов — удаление записей при выходе из области видимости. Полезно сразу писать функции удаления вместе с функциями создания и проверять код под инструментами анализа памяти.
Почему выполнение программы строится через обход AST, а не напрямую по токенам?
AST отделяет синтаксис от семантики. После построения дерева приоритеты операторов и структура выражений уже зафиксированы, и интерпретатору не нужно повторно анализировать порядок вычислений. Это упрощает выполнение и снижает количество проверок в рантайме.
Как корректно сообщать об ошибках, не завершая программу аварийно?
Все этапы интерпретации возвращают статус выполнения и описание ошибки. При сбое информация передается вверх по стеку вызовов до управляющего кода, который выводит сообщение пользователю. Такой подход позволяет освободить ресурсы и завершить работу предсказуемо, без падения процесса.
Как лучше организовать поддержку областей видимости переменных в простом интерпретаторе?
Проще всего связать каждую область видимости с отдельной таблицей символов, содержащей указатель на родительскую. При входе в блок создается новая таблица, при выходе — она уничтожается. Поиск переменной начинается с текущей таблицы и продолжается вверх по цепочке. Такой механизм легко реализуется на C и не требует сложных структур данных.
Стоит ли сразу добавлять типы данных или ограничиться одним числовым типом?
На раннем этапе разумно оставить один числовой тип, например double. Это снижает количество проверок и упрощает код выполнения. Когда интерпретатор стабильно обрабатывает выражения и операторы, можно добавить строки или логические значения, расширив union значений и обработку операций без изменения общей схемы работы.