Ошибки в коде – неотъемлемая часть процесса разработки. Однако, быстрое и точное их локализование часто становится ключевым для ускорения разработки и улучшения качества программы. При этом важно не только найти строку с ошибкой, но и понять её контекст, чтобы эффективно исправить проблему. На практике, существует несколько методов, которые позволяют точно и быстро определить местоположение ошибки в исходном коде.
Одним из первых инструментов, которые стоит использовать, является стек вызовов. Он отображает последовательность функций, вызвавших ошибку, и позволяет точно указать строку, на которой произошёл сбой. Для этого достаточно внимательно проанализировать трассировку ошибок, которая создается большинством языков программирования при возникновении исключений. Однако, стек вызовов не всегда полностью раскрывает суть проблемы, особенно если ошибка не приводит к исключению, а просто нарушает логику работы программы.
Другим полезным подходом является использование отладчика. С помощью отладчика можно пошагово пройти по коду и наблюдать, в какой момент программа начинает работать некорректно. Этот метод особенно полезен при поиске логических ошибок, когда нет явных сообщений об исключениях, но результат работы программы явно неправильный. Используя отладчик, вы можете ставить точки останова на подозрительных строках и анализировать значения переменных в реальном времени.
Не менее важным инструментом является логирование. Включение логирования на ключевых участках программы позволяет отслеживать, какие части кода были выполнены до возникновения ошибки. При этом важно логировать не только успешные операции, но и ошибки, предупреждения, а также значения критичных переменных. Это поможет найти ошибочную строку, а также даст контекст для дальнейшего исправления.
Как использовать стек вызовов для нахождения строки с ошибкой

При возникновении ошибки стек вызовов отображает цепочку функций с указанием номеров строк в исходном коде. Например, если программа на Python вызывает исключение, стек вызовов будет содержать список всех активных вызовов с их номерами строк. При этом в каждой записи будет указано, из какой функции был сделан вызов, и какая строка кода привела к ошибке. Анализируя эти записи, можно точно локализовать место возникновения проблемы.
Для эффективного использования стека вызовов необходимо внимательно прочитать каждую запись, начиная с самой последней. Первая строка в стеке вызовов указывает на ошибочную строку. Остальные записи показывают путь, по которому функция или метод были вызваны. Это позволяет проследить, как код дошёл до этой ошибки, и понять, что именно в логике работы программы пошло не так.
Для более точного анализа полезно включать в стек вызовов дополнительные данные, такие как аргументы функций или локальные переменные. Например, в Java или C++ можно использовать инструменты, которые автоматически добавляют в стек вызовов информацию о состоянии переменных в момент ошибки. В таких случаях, даже если ошибка не вызывает исключения, стек будет содержать полезные данные для диагностики.
Важно помнить, что стек вызовов будет полезен только в случае, если ошибка приводит к исключению или аварийному завершению программы. Для ошибок, которые не приводят к сбою (например, логические ошибки), стек вызовов сам по себе не даст ответа, но всё же поможет сузить круг поиска, указывая на потенциальные проблемные участки кода.
Роль отладчика в поиске проблемных строк в коде
С помощью отладчика можно установить точки останова (breakpoints) на конкретных строках кода. Когда программа достигает этой точки, её выполнение приостанавливается, и разработчик может исследовать состояние переменных, стек вызовов, а также понять, как изменяются данные. Это особенно полезно для выявления ошибок, которые сложно обнаружить с помощью логирования, например, ошибки в логике выполнения программы.
Отладчик позволяет не только остановить программу на нужной строке, но и шаг за шагом проследить её выполнение с переходом в каждую вызываемую функцию. Это помогает понять, где именно происходит сбой, особенно если ошибка возникла в глубокой вложенности функций. Например, в языках вроде C++ или Python можно использовать команды «шаг по шагу» (step over, step into), чтобы глубже понять, на каком уровне возникает проблема.
Кроме того, отладчик предоставляет возможность изменять значения переменных в процессе выполнения программы. Это дает уникальную возможность экспериментировать с различными значениями и быстро проверять гипотезы о том, где может быть ошибка. Например, если на какой-то строке происходит сбой из-за неправильного значения переменной, можно на месте заменить его и посмотреть, повлияет ли это на результат выполнения.
Особенно важным является использование отладчика в сочетании с другими методами поиска ошибок, такими как анализ стеков вызовов и логирование. В то время как стек вызовов позволяет локализовать ошибку на основе трассировки, отладчик дает возможность более детально исследовать поведение программы в момент ошибки, анализировать её контекст и точно понимать, что не так с данными или алгоритмами.
Как настроить логирование для автоматического отслеживания ошибок

Настройка логирования – важный шаг для эффективного отслеживания ошибок и анализа работы программы. Автоматическое логирование позволяет не только выявлять ошибки в реальном времени, но и собирать полезные данные для диагностики и оптимизации. Для настройки логирования необходимо учесть несколько ключевых аспектов, которые помогут правильно собирать информацию о сбоях.
Для начала, важно выбрать подходящий инструмент или библиотеку для логирования, в зависимости от используемого языка программирования. Например, в Python широко используется библиотека logging, а в Java – Log4j или SLF4J. Каждый из этих инструментов предоставляет гибкие настройки для записи ошибок, предупреждений, информации о событиях и других данных.
После выбора инструмента важно настроить уровни логирования, которые позволяют фильтровать важность записей. Обычно используются следующие уровни:
- DEBUG – информация, полезная при разработке, например, значения переменных и подробные сообщения о выполнении кода.
- INFO – общая информация о состоянии системы, например, успешные завершения операций.
- WARNING – предупреждения о потенциальных проблемах, которые могут повлиять на работу программы.
- ERROR – ошибки, которые нарушают выполнение программы, но не приводят к её аварийному завершению.
- CRITICAL – критические ошибки, которые могут привести к падению программы.
Для автоматического отслеживания ошибок можно настроить логирование таким образом, чтобы все сообщения об ошибках записывались в отдельный файл или отправлялись в систему мониторинга. Например, в Python можно настроить файл логов с фильтром уровня ERROR, чтобы записывать только ошибки и критические сбои:
import logging
logging.basicConfig(filename='error_log.txt', level=logging.ERROR)
def some_function():
try:
# код, который может вызвать ошибку
pass
except Exception as e:
logging.error(f"Произошла ошибка: {e}")
Важным моментом является настройка формата сообщений. Важно включить в каждое сообщение дату и время события, уровень логирования, имя файла и номер строки, где произошла ошибка. Это позволяет точно определить место сбоя и упрощает анализ причин. В Python это можно настроить так:
logging.basicConfig( filename='error_log.txt', level=logging.ERROR, format='%(asctime)s - %(levelname)s - %(message)s - %(filename)s:%(lineno)d' )
Чтобы логирование было эффективным, нужно регулярно анализировать полученные логи. Для этого можно интегрировать систему логирования с другими инструментами для анализа логов, например, ELK Stack (Elasticsearch, Logstash, Kibana) или использовать облачные сервисы для мониторинга, такие как Sentry или New Relic. Эти инструменты позволяют в реальном времени отслеживать ошибки, уведомлять о них и быстро реагировать на сбои.
Использование инструментов статического анализа для выявления ошибочных строк

Инструменты статического анализа кода позволяют обнаруживать потенциальные ошибки еще до выполнения программы. Эти инструменты проверяют исходный код на наличие ошибок, недочетов, уязвимостей и нарушений стиля, не требуя запуска программы. Статический анализ помогает определить проблемные строки на ранних этапах разработки, что сокращает время на отладку и повышает качество кода.
Одним из основных инструментов для статического анализа является SonarQube. Эта система позволяет автоматически анализировать код на разных языках программирования, включая Java, C#, Python и другие. SonarQube проверяет код на наличие ошибок, уязвимостей, а также оценивает его покрытие тестами и соблюдение стандартов кодирования. Все найденные проблемы отображаются с указанием строки кода, что помогает быстро локализовать ошибку.
Другим популярным инструментом является ESLint, который предназначен для анализа кода на JavaScript и TypeScript. ESLint выявляет синтаксические ошибки, проблемы с стилем и другие потенциальные ошибки, а также предоставляет возможности для автоматической фиксации простых проблем. С помощью ESLint можно настроить проверку на соответствие проектным стандартам, что помогает избежать ошибок, связанных с несоответствием кода общим требованиям.
Кроме того, для языков C и C++ широко используется Clang Static Analyzer, который проверяет код на наличие ошибок и уязвимостей, включая ошибки работы с памятью. Этот инструмент позволяет выявить такие проблемы, как утечки памяти, некорректные указатели и другие серьезные ошибки, которые трудно заметить при обычной отладке или тестировании.
Для успешного использования инструментов статического анализа важно правильно настроить их под конкретный проект и его требования. В большинстве случаев необходимо настроить правила анализа, чтобы фокусироваться на наиболее критичных ошибках, таких как использование неинициализированных переменных, ошибки типов и потенциальные проблемы с производительностью. Например, в PyLint для Python можно настроить проверку на использование недекларированных переменных или неправильные отступы, что помогает избежать синтаксических и логических ошибок.
Кроме того, важно интегрировать инструменты статического анализа в процесс CI/CD (непрерывной интеграции и доставки). Это позволит автоматически запускать анализ при каждом коммите и обнаруживать ошибки на ранних стадиях, до того как они попадут в продакшн. Использование таких систем как Jenkins или GitLab CI в связке с инструментами статического анализа ускоряет процесс разработки и уменьшает количество багов в готовом продукте.
Как локализовать ошибку с помощью простого тестирования и проверки гипотез
Первым шагом является выделение предполагаемых источников ошибки. Это можно сделать на основе анализа кода, проверки последних изменений или логов. Например, если программа начинает вести себя некорректно после изменений в определенной функции, то можно начать тестирование именно с этой части кода. Важно создать несколько гипотез о том, какие участки программы могут вызывать ошибку.
Затем следует поочередно проверять каждую гипотезу, изолируя проблемные участки кода. Для этого можно использовать простые тесты, чтобы убедиться, что та или иная часть программы работает корректно. Например, если подозрение падает на вычисления в определенной функции, можно добавить несколько тестов, которые проверят корректность работы этой функции с разными входными данными.
Одним из эффективных методов является подход «разделяй и властвуй», когда код разбивается на небольшие части, каждая из которых тестируется отдельно. Например, если в коде есть несколько функций, объединенных в один большой блок, можно временно закомментировать все кроме одной функции и проверить её работу. Если ошибка не возникает, можно постепенно возвращать остальные функции, проверяя, в какой момент снова появляется сбой.
Для ускорения процесса можно использовать модульные тесты, чтобы проверить не только сами функции, но и их взаимодействие друг с другом. Модульные тесты позволяют быстро выявить ошибочные строки, проверяя код на различных входных данных и условиях. Если ошибка не возникает на базовых тестах, но появляется при определенных значениях, это указывает на конкретный участок, в котором проблема.
Очень важно правильно интерпретировать результаты тестов. Если гипотеза о проблемной части кода подтвердилась, то это уже сужает круг поиска и дает понимание, что именно в коде вызывает ошибку. В случае неудачных тестов можно отклонить гипотезу и проверить другие части программы. Такой итеративный процесс позволяет быстро локализовать ошибку и исправить её, не тратя время на тщательную отладку всего кода.
Как анализировать сообщения об ошибках и трассировки для нахождения проблемы
Первое, на что стоит обратить внимание в сообщении об ошибке – это тип ошибки. В разных языках программирования могут использоваться разные категории ошибок: синтаксические, логические, ошибки выполнения и т.д. Например, ошибка типа в JavaScript может означать, что в коде пытались выполнить операцию с несовместимыми типами данных, в то время как исключение в Python часто связано с проблемами работы с файлами или неправильной индексацией списка. Понимание типа ошибки позволяет сузить круг поиска и сразу нацелиться на вероятные источники проблемы.
Второй важный элемент – это строка, в которой произошла ошибка. Почти все языки программирования предоставляют точное местоположение сбоя в виде номера строки, а иногда и имени файла. Важно внимательно прочитать строку с ошибкой и проверить её на соответствие ожидаемому поведению. Если ошибка происходит в месте, где работа с данными или ресурсами несанкционирована (например, обращение к несуществующему элементу массива), это сразу указывает на возможную проблему в логике программы.
После того как найдена строка, в которой возникла ошибка, следует обратить внимание на трассировку стека вызовов. Это последовательность функций, которые были вызваны до момента сбоя. Трассировка позволяет проследить путь выполнения программы и понять, какие именно функции и методы привели к ошибке. Важно не просто смотреть на последние строки трассировки, а анализировать всю цепочку вызовов, начиная с самой первой. Это поможет понять, из-за чего произошел сбой и в какой момент выполнения программы ошибка стала критической.
В некоторых случаях трассировки могут быть длинными и сложными. Чтобы упростить анализ, полезно искать повторяющиеся паттерны или частые проблемы. Например, если несколько трассировок ведут к одной и той же функции, это может указывать на ошибку, которая повторяется при различных входных данных. Также стоит обратить внимание на промежуточные вызовы и проверить, не возникает ли ошибка из-за неправильной передачи данных между функциями.
Если в сообщениях об ошибках или трассировках не указано точное место сбоя, можно использовать дополнительные методы. Например, добавление логирования перед важными функциями или блоками кода поможет отслеживать состояние переменных и контекст выполнения программы. Это также позволит лучше понять, какие данные передаются в функцию и какие изменения происходят до того, как возникнет ошибка.
Интеграция инструментов для автоматического поиска ошибок в процессе разработки
Одним из первых шагов в интеграции инструментов для автоматического поиска ошибок является настройка системы CI/CD. Популярные решения, такие как Jenkins, GitLab CI, или CircleCI, предоставляют удобные средства для автоматического запуска тестов и анализаторов кода при каждом коммите или pull request. Важно настроить пайплайны таким образом, чтобы инструменты статического анализа, тестирования и покрытия кода запускались автоматически, обеспечивая непрерывный мониторинг состояния проекта.
Для интеграции инструментов статического анализа, таких как SonarQube или ESLint, можно настроить автоматический запуск анализа кода на каждом этапе пайплайна. Например, при каждом коммите можно автоматически проверять код на наличие ошибок, недочетов в стиле и проблем с производительностью. Для этого необходимо добавить шаг в конфигурацию CI, который будет запускать соответствующие команды для анализа кода. В случае обнаружения проблем система CI может автоматически остановить процесс сборки и уведомить разработчиков о найденных ошибках.
Кроме того, стоит интегрировать инструменты для автоматического запуска модульных и интеграционных тестов. Такие инструменты, как JUnit (для Java), PyTest (для Python) или Mocha (для JavaScript), позволяют проверять корректность функционала программы. Важно, чтобы каждый новый код был протестирован на совместимость и правильность работы. Запуск тестов при каждом коммите и автоматическая генерация отчетов позволяет быстро выявлять проблемные участки кода.
Для улучшения качества кода можно интегрировать инструменты для анализа покрытия тестами, такие как Jacoco (для Java) или Coverage.py (для Python). Эти инструменты показывают, какие части кода были покрыты тестами, а какие нет, и позволяют определить области, которые нуждаются в дополнительной проверке. Например, если система показывает, что определенная функция или метод не покрыты тестами, это сигнализирует о том, что данный участок кода может быть уязвим для ошибок.
Важным аспектом интеграции является настройка уведомлений. При обнаружении ошибок или несоответствий в коде система CI должна отправлять уведомления разработчикам через email, мессенджеры или системы управления задачами (например, Jira). Это позволяет быстро реагировать на проблемы, устранять их на ранних этапах и поддерживать высокий уровень качества кода.
Наконец, для максимальной эффективности важно регулярно обновлять инструменты анализа и тестирования, а также адаптировать их под новые требования проекта. Важно, чтобы пайплайны CI/CD были настроены с учетом изменений в проекте и текущих стандартов разработки, чтобы поддерживать актуальность автоматической проверки ошибок на протяжении всего цикла разработки.
Вопрос-ответ:
Как найти строку с ошибкой, если программа не выдает явных сообщений об исключении?
В таких случаях можно использовать методы логирования или отладки. Если программа не выдает исключения, это может означать, что ошибка не приводит к сбою, но нарушает логику работы. Настройте логирование на ключевых участках кода, чтобы отслеживать данные о выполнении программы. Это поможет выявить, в какой момент программа начинает работать неправильно. Также можно использовать отладчик для пошагового выполнения программы и проверки значений переменных на разных этапах работы.
Как интерпретировать стек вызовов для поиска строки с ошибкой?
Стек вызовов показывает последовательность вызовов функций, которые привели к ошибке. Самая последняя строка в стек вызовов указывает на строку, в которой произошел сбой. Однако не стоит ограничиваться только этой строкой. Трассировка может содержать полезные данные о функциях, которые были вызваны до ошибки, что помогает понять контекст ошибки и сузить область поиска. Анализируйте стек начиная с первой строки и проследите весь путь, который привел к сбою.
Какие инструменты для статического анализа помогают найти ошибки в строках кода?
Для статического анализа существуют различные инструменты, такие как SonarQube, ESLint (для JavaScript), PyLint (для Python) или Clang Static Analyzer (для C++). Эти инструменты анализируют код без его выполнения и помогают выявлять синтаксические ошибки, проблемы с типами данных, нарушения стиля и потенциальные уязвимости. Они могут указать на проблемные строки до того, как программа начнет работать, что помогает предотвратить многие ошибки на ранних стадиях разработки.
Почему логирование важно для поиска ошибочных строк, и как правильно настроить логирование?
Логирование позволяет отслеживать, что происходит в программе в реальном времени, и записывать важные данные, которые могут помочь в поиске ошибок. Оно полезно для понимания, какие функции выполняются и какие значения передаются между ними. Чтобы настроить логирование, выберите инструмент для своего языка программирования (например, Python — logging, Java — Log4j) и установите уровни логирования: от обычной информации до ошибок и критических исключений. Записывайте в логи даты и время событий, а также номера строк, где происходят изменения состояния программы. Это даст вам четкое представление о том, на каком этапе возникает сбой.
Как использовать отладчик для нахождения строк с ошибкой в сложных функциях?
Отладчик позволяет шаг за шагом проследить выполнение программы и увидеть, на каком этапе происходит сбой. Для сложных функций, особенно тех, которые вызывают другие функции, можно установить точки останова в ключевых местах. Пошагово выполняйте программу, проверяя значения переменных и состояния на каждом этапе. Если ошибка возникает в глубокой вложенности, используйте команды «step over» или «step into», чтобы перейти на следующий уровень или внутрь вызываемой функции. Это поможет локализовать ошибку в конкретной строке кода.
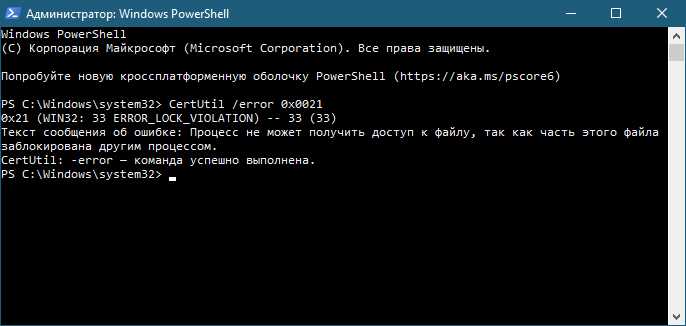
Что делать, если программа падает с ошибкой во время выполнения, а сообщение не содержит номера строки?
В такой ситуации полезно использовать несколько приёмов одновременно. Сначала стоит включить максимально подробный режим вывода ошибок, если язык или среда это позволяют: часто дополнительная информация появляется после изменения настроек. Далее имеет смысл проанализировать стек вызовов — даже без явного номера строки он показывает цепочку функций, в которых произошёл сбой. Это помогает сузить круг поиска до конкретного участка кода. Если стек недоступен, можно добавить временные сообщения вывода перед подозрительными строками и посмотреть, какое из них не успевает выполниться. Такой метод позволяет локализовать проблемное место шаг за шагом. В сложных случаях удобнее воспользоваться отладчиком: пошаговое выполнение и просмотр значений переменных дают понимание, на какой строке данные принимают неверное значение и приводят к аварийному завершению программы.