Содержание статьи

Коды в информатике представляют собой системы символов и правил их преобразования для хранения, передачи и обработки информации. Двоичный код используется для представления всех типов данных в компьютерах: числа, текст, изображения и звук переводятся в последовательности нулей и единиц. Понимание структуры двоичного кода помогает оптимизировать использование памяти и ускорять обработку данных.
Коды обнаружения и исправления ошибок, такие как коды Хэмминга или циклические избыточные коды, позволяют выявлять и корректировать ошибки при передаче данных по каналам с шумом. Использование этих кодов критично в сетях связи и системах хранения информации, где даже единичная ошибка может привести к сбою.
Коды представления текста и символов, включая ASCII и Unicode, обеспечивают совместимость между различными устройствами и программными системами. При разработке приложений стоит выбирать Unicode для поддержки многозначных алфавитов и специальных символов, что снижает риск некорректного отображения текста.
Бар-коды, QR-коды и машинные коды применяются в промышленности, логистике и программировании для идентификации объектов и ускорения процессов обработки информации. Интеграция этих кодов в программное обеспечение или базы данных позволяет автоматизировать учет, сократить время поиска и повысить точность операций.
Шифровальные коды обеспечивают защиту данных при передаче и хранении. Использование современных алгоритмов шифрования и систем управления ключами рекомендуется для защиты конфиденциальной информации в корпоративных сетях и облачных сервисах, минимизируя риск несанкционированного доступа.
Двоичный код и его роль в хранении данных
Для эффективного использования двоичного кода рекомендуется учитывать следующие аспекты:
- Выбор минимального числа бит для хранения числовых значений снижает объем используемой памяти. Например, для чисел от 0 до 255 достаточно 8 бит, а не 16.
- Использование побитовых операций (AND, OR, XOR, NOT) ускоряет вычисления при обработке массивов данных и флагов состояния.
- Сжатие данных с применением двоичных алгоритмов, таких как Run-Length Encoding или Huffman Coding, уменьшает объем хранения без потери информации.
В системах хранения информации двоичный код также применяют для контроля целостности:
- Добавление контрольных битов позволяет обнаруживать ошибки при чтении данных с носителей.
- Системы RAID используют двоичный контроль для восстановления информации при сбоях отдельных дисков.
- Файловые форматы, например PNG или ZIP, применяют двоичные структуры с проверкой контрольных сумм для обеспечения надежности хранения.
Практическое применение двоичного кода требует анализа структуры данных и учета возможностей оборудования. Оптимизация кода и использование побитовых операций позволяют снизить нагрузку на процессор и ускорить обработку больших массивов информации.
Коды Хэмминга для обнаружения и исправления ошибок

Коды Хэмминга применяются для выявления и исправления одиночных ошибок в цифровых данных. Они основаны на добавлении контрольных битов к исходной информации, что позволяет вычислять позиции поврежденных битов при чтении данных.
Основные принципы работы кодов Хэмминга:
- Распределение контрольных битов: каждый контрольный бит проверяет несколько позиций данных, расположенных по степеням двойки.
- Обнаружение ошибок: при чтении данных вычисляется синдром – комбинация контрольных битов, указывающая на поврежденный бит.
- Исправление ошибок: позиция поврежденного бита определяется по синдрому, и бит автоматически корректируется без вмешательства пользователя.
Рекомендации по использованию кодов Хэмминга:
- Применять для памяти с ограниченным уровнем ошибок, например в оперативной памяти или микроконтроллерах, где возможны единичные сбои.
- Использовать расширенные версии кода для обнаружения двойных ошибок и исправления одиночных, если важна надежность передачи данных.
- Встраивать проверку и исправление на уровне программного обеспечения для уменьшения нагрузки на аппаратные ресурсы при передаче больших массивов информации.
Коды Хэмминга сохраняют баланс между количеством добавляемых битов и степенью надежности данных, что делает их востребованными в сетевых протоколах, системах хранения и встроенных устройствах.
Коды Грея в цифровой электронике и сенсорах
Коды Грея используются для минимизации ошибок при преобразовании аналоговых сигналов в цифровые и при работе вращающихся датчиков положения. Основное преимущество кода Грея заключается в том, что при изменении значения изменяется только один бит, что снижает вероятность ложных переходов.
Применение кодов Грея включает:
- Энкодеры для измерения углового положения в промышленной автоматике.
- Системы цифрового измерения и АЦП, где важно избегать ошибок при смене состояния нескольких бит одновременно.
- Оптимизация микропроцессорных операций для быстрого и точного считывания данных с датчиков.
Пример преобразования двоичных чисел в код Грея представлен в таблице:
| Двоичное число | Код Грея |
|---|---|
| 0000 | 0000 |
| 0001 | 0001 |
| 0010 | 0011 |
| 0011 | 0010 |
| 0100 | 0110 |
| 0101 | 0111 |
Рекомендации по использованию кодов Грея:
- Выбирать код Грея для высокоскоростных цифровых интерфейсов, чтобы снизить шум при одновременной смене нескольких бит.
- Применять для энкодеров в робототехнике и станках с ЧПУ для точного контроля положения.
- Использовать вместе с фильтрацией сигналов для уменьшения влияния механических дребезгов и колебаний на точность измерений.
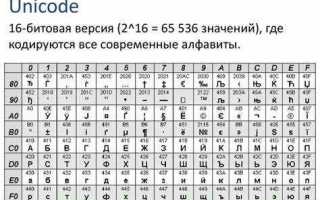
ASCII и Unicode для представления текстовой информации

ASCII представляет собой 7-битный код для символов английского алфавита, цифр и базовых знаков препинания, что позволяет хранить 128 различных символов. Он широко используется в старых системах и протоколах передачи данных, где требуется минимальный объем памяти.
Unicode расширяет возможности кодирования, предоставляя более 140 000 символов, включая символы всех современных языков, специальные знаки и эмодзи. Для хранения каждого символа в Unicode применяются форматы UTF-8, UTF-16 и UTF-32, которые различаются объемом памяти и совместимостью с ASCII.
Рекомендации по выбору кодировки:
- Использовать UTF-8 для веб-приложений и баз данных, чтобы поддерживать многоязычный текст и сохранить совместимость с ASCII.
- Выбирать UTF-16 при работе с внутренними текстовыми структурами в приложениях на платформах Windows, где преобладают символы за пределами базовой латиницы.
- Обращать внимание на порядок байт (BOM) при передаче данных между различными системами для корректного отображения символов.
- Применять проверку и нормализацию текста, чтобы исключить дублирование символов с одинаковым визуальным представлением, особенно при сравнении и поиске.
Использование Unicode гарантирует правильное отображение текста независимо от языка и устройства, а корректный выбор формата кодирования снижает нагрузку на память и улучшает совместимость между системами.
Шифровальные коды для защиты данных
Шифровальные коды используются для преобразования информации в формат, недоступный для неавторизованных пользователей. Основные методы включают симметричное и асимметричное шифрование, а также хэширование для контроля целостности данных.
Симметричное шифрование применяет один ключ для шифрования и дешифрования. Популярные алгоритмы: AES, DES, RC4. Применение симметричных кодов рекомендуется для локального хранения данных и защищенных каналов с ограниченным количеством участников.
Асимметричное шифрование использует пару ключей – открытый и закрытый. Алгоритмы RSA и ECC обеспечивают безопасную передачу данных через открытые сети и управление цифровыми подписями.
Хэширование позволяет проверить целостность информации без раскрытия исходного содержимого. Алгоритмы SHA-256 и MD5 применяются для контроля файлов и паролей, но MD5 рекомендуется использовать только для совместимости, так как он уязвим к коллизиям.
Рекомендации по использованию шифровальных кодов:
- Для передачи конфиденциальных данных в сети использовать комбинацию асимметричного шифрования для обмена ключами и симметричного для самой информации.
- Регулярно обновлять ключи шифрования и использовать длину ключей не менее 128 бит для AES и 2048 бит для RSA.
- Применять хэш-функции для проверки целостности переданных и сохраненных данных.
- Хранить закрытые ключи в защищенных хранилищах и использовать аппаратные модули безопасности (HSM) для критических систем.
Бар-коды и QR-коды в системах учета и логистике

Бар-коды и QR-коды применяются для идентификации товаров, упаковок и документов в системах учета и логистики. Бар-коды представляют собой последовательности чередующихся черных и белых полос, каждая из которых кодирует цифру или символ, а QR-коды – двумерные матрицы, способные хранить текстовую информацию, ссылки и данные о товаре.
Основные области использования:
- Складской учет: автоматическое сканирование поступающих и отгружаемых товаров снижает ошибки и ускоряет обработку.
- Розничная торговля: бар-коды и QR-коды обеспечивают быстрый расчет на кассе и управление ассортиментом.
- Транспорт и логистика: отслеживание местоположения посылок и контроль сроков доставки с помощью сканеров и мобильных приложений.
Рекомендации по внедрению:
- Выбирать тип кода в зависимости от объема данных: для простой нумерации товаров достаточно линейного бар-кода, для хранения больших массивов информации – QR-кода.
- Использовать стойкие к повреждениям материалы и методы печати, чтобы снизить вероятность ошибки при сканировании.
- Интегрировать системы сканирования с базами данных и ERP-системами для автоматического обновления информации и отчетности.
- Регулярно проверять корректность кодов и сканеров, чтобы исключить проблемы с идентификацией и логистическими процессами.
Коды коррекции в сетевых протоколах передачи данных

Коды коррекции ошибок обеспечивают надежную передачу данных в сетях с шумом и нестабильным соединением. Они позволяют обнаруживать и исправлять ошибки без повторной отправки пакета, что снижает задержки и повышает качество связи.
Основные методы применяются в протоколах TCP/IP, LTE и Wi-Fi:
- Циклические избыточные коды (CRC) используются для проверки целостности пакетов данных и обнаружения ошибок при передаче по кабелю или радиоканалу.
- Коды Хэмминга применяются в протоколах передачи малых объемов данных и в системах с ограниченным уровнем ошибок.
- Рид-Соломон (Reed-Solomon) широко применяются в мобильных сетях, оптических каналах и спутниковой связи для исправления многобитовых ошибок.
Рекомендации по использованию кодов коррекции:
- Выбирать тип кода в зависимости от частоты ошибок и скорости канала: CRC подходит для обнаружения, Хэмминга – для одиночных ошибок, Рид-Соломон – для burst-ошибок.
- Интегрировать проверку и исправление на уровне сетевых стеков для минимизации задержек и нагрузки на приложения.
- Использовать комбинированные методы (например, CRC с Рид-Соломон) для критичных данных, где недопустимы потери информации.
- Периодически обновлять алгоритмы и параметры кодов в соответствии с изменением характеристик сети и требований к надежности передачи.
Машинные коды и их использование в программировании

Машинные коды представляют собой набор инструкций, непосредственно исполняемых процессором. Каждая инструкция закодирована в виде бинарной последовательности, которая управляет регистрами, памятью и периферийными устройствами.
Основные области применения:
- Оптимизация программного кода: ручная или компиляторная генерация машинных инструкций позволяет уменьшить количество операций и ускорить выполнение критичных функций.
- Встраиваемые системы: программирование микроконтроллеров и FPGA требует работы с машинными кодами для минимизации объема памяти и быстродействия.
- Анализ и отладка: изучение машинного кода помогает выявлять ошибки на уровне выполнения и предотвращать сбои, связанные с неправильным управлением памятью.
Рекомендации при работе с машинными кодами:
- Использовать ассемблер для точного контроля инструкций и адресации памяти в критичных по производительности приложениях.
- Сочетать высокоуровневые языки с машинными вставками для ускорения отдельных вычислительных участков.
- Проверять корректность инструкций и их совместимость с архитектурой процессора, чтобы избежать сбоев и неопределенного поведения программы.
- Применять симуляторы и отладочные среды для тестирования машинного кода перед внедрением в рабочие системы.
Вопрос-ответ:
Для чего используют коды Хэмминга в современных сетях?
Коды Хэмминга применяются для обнаружения и исправления одиночных ошибок в передаваемых данных. Они добавляют контрольные биты к исходной информации, что позволяет определить позицию поврежденного бита и исправить его без повторной передачи пакета. Это особенно важно в беспроводных сетях и системах хранения данных, где вероятность случайных ошибок выше.
В чем преимущество использования кода Грея в энкодерах и датчиках?
Код Грея минимизирует количество битовых изменений при переходе между соседними значениями, что снижает вероятность ложных считываний из-за дребезга контактов или временных рассогласований сигналов. В практике это повышает точность измерений угловых положений и положения линейных сенсоров, особенно в высокоскоростных устройствах.
Как выбрать между ASCII и Unicode для хранения текстовых данных?
Если требуется хранить текст только на латинице с базовыми символами, можно использовать ASCII, так как он экономит память и совместим со старыми системами. Для поддержки многоязычных текстов, специальных символов и эмодзи рекомендуется использовать Unicode в формате UTF-8, который совместим с ASCII и позволяет передавать текст между различными платформами без потерь.
Почему применяют Рид-Соломон в протоколах мобильной связи?
Коды Рид-Соломон позволяют исправлять многобитовые ошибки в последовательности данных, что делает их полезными в каналах с высоким уровнем помех, например, в LTE или спутниковой связи. Они обеспечивают восстановление информации без повторной передачи и поддерживают стабильность связи при шумных или нестабильных соединениях.
Какие рекомендации по использованию QR-кодов для отслеживания товаров в логистике?
При применении QR-кодов важно выбирать формат, подходящий для объема информации: для простой идентификации достаточно небольшого кода, для хранения данных о поставках или инструкций — более крупного. Код должен быть напечатан устойчиво к повреждениям и интегрирован с базой данных или системой учета, чтобы сканирование автоматически обновляло информацию о движении товара. Регулярная проверка сканеров и качества печати помогает избежать ошибок при обработке.
Зачем в микроконтроллерах используют машинные коды вместо высокоуровневых языков?
Машинные коды выполняются напрямую процессором без промежуточной компиляции, что позволяет минимизировать задержки и объем используемой памяти. В микроконтроллерах с ограниченными ресурсами это помогает управлять регистрами и периферией с точностью до отдельных тактов, а также оптимизировать критичные участки программы, где требуется высокая скорость реакции.
Как выбор между линейными бар-кодами и QR-кодами влияет на учет и логистику?
Линейные бар-коды подходят для простых задач идентификации, например, для нумерации товаров на складе, так как они занимают меньше места и легко считываются стандартными сканерами. QR-коды способны хранить больше информации, включая текстовые данные и ссылки, что позволяет отслеживать историю перемещений, срок годности и сопроводительные документы. Выбор зависит от объема данных и скорости обработки: для больших и комплексных логистических систем QR-коды обеспечивают более подробный контроль.