Содержание статьи

Начинающему специалисту трудно выбрать первую учебную площадку: программы различаются по уровню, длительности и набору инструментов. Одни дают упор на математику, другие – на работу с Python и практические задачи. Поэтому важнее сразу определить, какие навыки нужны на старте: основы статистики, умение работать с таблицами, опыт применения библиотек для анализа.
Площадки вроде Coursera, Stepik и ODS.ai предлагают курсы по статистике и Python с возможностью практиковаться в Jupyter Notebook. Там же можно найти задания на обработку реальных датасетов, что помогает быстрее освоить базовые приёмы. Для изучения машинного обучения подойдут программы, в которых есть разбор алгоритмов, примеры кода и проверка домашних работ.
Тем, кто предпочитает структурированное обучение, стоит рассмотреть интенсивные программы от российских и международных школ. В них есть поддержка наставников, разбор типичных ошибок и проекты, которые можно включить в портфолио. Такой формат помогает быстрее перейти от теории к реальным задачам.
Обучение базовой математике и статистике на онлайн-курсах

Для уверенного старта в дата сайнс требуется знание статистики, линейной алгебры и основ теории вероятностей. Эти дисциплины можно пройти на платформах, где материалы разбиты на небольшие блоки с задачами и проверкой решений. Такой формат помогает освоить фундамент, необходимый для анализа данных и работы с моделями.
- Stepik: курсы по математическому анализу, линейной алгебре и вероятностным методам. Часто встречаются практические задания с расчётами и интерпретацией результатов.
- Coursera: программы университетов, в которых используется Python для демонстрации статистических приёмов. В заданиях требуется выполнять вычисления в Jupyter Notebook.
- Khan Academy: структурированные уроки по вероятностям и статистике, подходящие для быстрого пополнения пробелов.
Для начинающих полезно сочетать видеолекции и решенные примеры. Такой подход формирует навык чтения формул и понимания того, как математические методы применяются в коде.
- Пройти курс по базовой статистике с акцентом на средние значения, вариацию и распределения.
- Изучить линейную алгебру до уровня работы с матрицами и векторами.
- Закрепить материал на задачах и мини-проектах: расчёт корреляций, проверка гипотез, анализ выборок.
В результате формируется база, которая позволяет уверенно переходить к изучению алгоритмов машинного обучения и обработке датасетов.
Изучение Python для анализа данных на учебных платформах
Python остаётся основным инструментом в дата сайнс благодаря широкому набору библиотек для обработки данных. Начинающим важно освоить не только синтаксис, но и приёмы работы с таблицами, массивами, файлами и простыми вычислительными задачами. Учебные платформы предлагают пошаговые модули, где каждая тема закрепляется задачами в интерактивных средах.
На Stepik доступны курсы, в которых разбор базовых конструкций сочетается с применением Pandas и NumPy. Учащийся сразу работает с реальными фрагментами данных: загружает CSV, выполняет группировки, сортирует строки, вычисляет агрегаты. Coursera предоставляет программы университетского уровня с заданиями в Jupyter Notebook, где требуется писать код и анализировать промежуточные результаты.
Для продвижения вперёд важно выполнять небольшие проекты: очистка датасета, преобразование колонок, расчёт показателей, подготовка данных к обучению моделей. Такой формат позволяет закрепить навыки, которые затем будут использоваться при изучении машинного обучения и работе с более крупными наборами данных.
Практика в Jupyter Notebook через бесплатные ресурсы
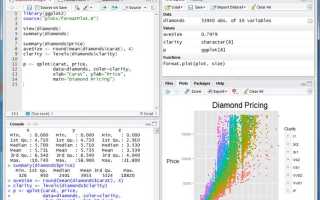
Jupyter Notebook позволяет выполнять код по шагам, фиксировать промежуточные результаты и сочетать вычисления с текстовыми пояснениями. Начинающим удобно использовать его для отработки приёмов анализа данных, поскольку структура блоков упрощает проверку гипотез и разбор ошибок.
- Google Colab: бесплатный доступ к Jupyter-среде без установки. Поддерживает загрузку файлов, работу с Pandas, NumPy и визуализацией. Можно подключать GPU для последующих экспериментов.
- Kaggle Notebooks: готовые окружения с установленными библиотеками. Есть примеры ноутбуков по анализу датасетов, которые можно копировать и модифицировать.
- Binder: запуск репозиториев GitHub в виде интерактивных ноутбуков. Подходит для изучения чужих проектов и повторения вычислений.
Для формирования стабильных навыков рекомендуется регулярная практика на небольших задачах:
- Загрузка данных из открытых источников и их первичная обработка.
- Построение таблиц с помощью Pandas и вычисление ключевых показателей.
- Создание графиков для проверки распределений и взаимосвязей.
- Подготовка входных данных для последующих моделей.
Такая среда помогает переходить от изучения синтаксиса Python к выполнению задач, близких к реальной работе с данными.
Получение навыков работы с библиотеками NumPy и Pandas
NumPy и Pandas формируют основу технических навыков дата сайнс. NumPy используется для работы с многомерными массивами и быстрых вычислений, а Pandas – для обработки табличных данных. Освоить эти инструменты можно через практические задания на платформах с интерактивными средами.
Начинающим полезно выполнять упражнения, в которых требуется:
- создавать и модифицировать массивы NumPy, применять арифметические операции и функции агрегирования;
- работать с DataFrame: фильтрация строк, преобразование колонок, группировки, объединение таблиц;
- загружать CSV и Excel, приводить данные к нужным типам, обрабатывать пропуски;
- вычислять показатели по выборкам и формировать сводные таблицы.
Для регулярной практики подходят Stepik, Kaggle Learn и курсы университетского уровня на Coursera. Они предлагают задания с проверкой кода, что помогает закрепить навыки манипулирования массивами и таблицами.
Дополнительно стоит разбирать примеры из открытых репозиториев GitHub: изучение чужих решений даёт представление о том, как использовать NumPy и Pandas в реальных задачах – от подготовки данных до вычисления статистических показателей.
Освоение визуализации данных на специализированных курсах
Визуализация помогает разбирать распределения, выявлять отклонения и сравнивать группы. Специализированные курсы дают возможность освоить инструменты, которые применяются в аналитических проектах: Matplotlib, Seaborn и библиотеки для интерактивных графиков. Учащийся получает навыки построения диаграмм, настройки осей, выбора подходящего типа графика и подготовки итоговых отчётов.
Площадки, где можно пройти такие программы, различаются по глубине и формату:
| Платформа | Содержание | Особенности |
|---|---|---|
| Stepik | Материалы по построению линейных, столбчатых и коробчатых диаграмм | Задания с загрузкой датасетов и разбором графиков |
| Coursera | Уроки по визуализации с применением Python и инструкциями по интерпретации графиков | Задачи в Jupyter Notebook |
| Kaggle Learn | Краткие практические модули по Seaborn и Plotly | Примеры из открытых наборов данных |
Для качественного освоения материала рекомендуется выполнять собственные мини-проекты: анализ продаж, визуализация сезонности, сравнение категорий, построение корреляционных полей. Такой формат позволяет закрепить навыки и уверенно переходить к дальнейшим этапам изучения дата сайнс.
Изучение машинного обучения на структурированных программах

Структурированные программы дают пошаговое изучение алгоритмов машинного обучения и их применения на практике. Курсы включают разбор моделей регрессии, деревьев решений, кластеризации и базовых нейронных сетей, с акцентом на подготовку данных, обучение моделей и оценку качества предсказаний.
Для начинающих полезны платформы с проверкой домашних заданий и проектами:
- Coursera: программы университетов с последовательным изучением алгоритмов, заданиями в Jupyter Notebook и примерами работы с реальными датасетами.
- Stepik: курсы с интерактивными упражнениями по классификации, регрессии и кластеризации на Python.
- Udemy: структурированные видеокурсы с проектами по машинному обучению, где объясняется код и результаты моделей.
Рекомендуется выполнять практические проекты: предсказание цен, классификация объектов, анализ пользовательских данных. Такой подход позволяет закрепить навыки работы с библиотеками scikit-learn, обработку данных и оценку точности моделей.
Тренировка на открытых датасетах и соревнованиях

Работа с реальными наборами данных помогает закрепить теоретические знания и освоить практические приёмы анализа. Начинающим важно выбирать открытые датасеты, которые содержат разные типы данных: числовые, категориальные, временные ряды и текст. Это формирует навыки предобработки и подготовки данных к моделям.
Основные ресурсы для тренировки:
- Kaggle: бесплатные датасеты и соревнования по классификации, регрессии, обработке изображений и текста. Есть ноутбуки с решениями, которые можно изучать и модифицировать.
- UCI Machine Learning Repository: коллекция классических наборов данных для обучения алгоритмам машинного обучения.
- Open Data Portals: государственные и корпоративные порталы с открытыми наборами, например, данные о транспорте, экономике или здравоохранении.
Практика должна включать следующие этапы:
- Загрузка и изучение структуры датасета.
- Очистка данных: обработка пропусков, преобразование типов и кодирование категорий.
- Применение алгоритмов для построения моделей и проверка качества предсказаний.
- Анализ ошибок и улучшение моделей через эксперимент с параметрами.
Регулярное участие в соревнованиях помогает сравнивать свои результаты с другими и ускоряет освоение инструментов анализа данных.
Выбор учебных программ с наставниками и проверкой задач

Программы с наставниками позволяют получать обратную связь по решениям и избегать типичных ошибок на начальном этапе. В таких курсах домашние задания проверяются экспертами или автоматически, что помогает отслеживать прогресс и понимать, где нужны дополнительные упражнения.
Рекомендуемые форматы:
- GeekBrains и SkillFactory: курсы с наставниками, где каждое задание проверяется и сопровождается комментариями по улучшению кода и аналитических решений.
- Coursera с проектными модулями: эксперты проверяют проекты и дают рекомендации по оптимизации моделей и подготовке данных.
- ODS.ai и Kaggle Learn: менторы разбирают задания по анализу реальных датасетов и помогают в интерпретации результатов.
При выборе программы важно оценить:
- Наличие проектов с реальными данными.
- Качество обратной связи и скорость её предоставления.
- Доступ к менторской поддержке и возможности задавать вопросы в процессе обучения.
Такой подход ускоряет освоение практических навыков, позволяет формировать портфолио и повышает уверенность при переходе к самостоятельной работе с данными.
Вопрос-ответ:
С каких онлайн-курсов начать изучение математики для дата сайнс?
Для новичков подходят курсы Stepik и Khan Academy, где есть последовательные модули по статистике, линейной алгебре и теории вероятностей. Они предлагают упражнения с реальными вычислениями и разбор формул, что помогает понять, как применять математику для анализа данных.
Как выбрать курсы по Python для анализа данных?
Важно искать программы, где практические задания связаны с обработкой таблиц и массивов. Stepik и Coursera предлагают курсы с использованием Jupyter Notebook и библиотек Pandas и NumPy, позволяя сразу работать с реальными данными и закреплять навыки через проекты.
Стоит ли начинать с Jupyter Notebook, если нет опыта в программировании?
Да, Jupyter Notebook позволяет писать код блоками, видеть результаты сразу и добавлять текстовые пояснения. Бесплатные ресурсы вроде Google Colab и Kaggle Notebooks позволяют тренироваться с готовыми датасетами без установки программного обеспечения.
Какие платформы предлагают наставников при изучении дата сайнс?
Платформы SkillFactory, GeekBrains и некоторые программы Coursera предоставляют проверку домашних заданий экспертами и консультации наставников. Такой формат помогает исправлять ошибки на раннем этапе и быстрее закреплять практические навыки.
Как практиковаться на реальных данных без платного обучения?
Можно использовать открытые датасеты на Kaggle, UCI Machine Learning Repository или государственных порталах открытых данных. Работая с ними, можно выполнять очистку данных, строить модели и проверять качество предсказаний, что имитирует реальные рабочие задачи.