В Python потоки (threads) и процессы (processes) предоставляют разные способы выполнения кода параллельно. Потоки разделяют память одного процесса, что позволяет быстро обмениваться данными, но из-за глобальной блокировки интерпретатора (GIL) одновременно выполняется только один поток Python-кода. Процессы создают отдельные адресные пространства, что исключает конфликты памяти и позволяет использовать несколько ядер CPU для вычислительных задач.
При выборе между потоками и процессами важно учитывать тип нагрузки. Для сетевых запросов, чтения файлов или работы с базами данных использование потоков уменьшает время ожидания и снижает накладные расходы на создание новых потоков. Для задач, требующих значительных вычислений, многопроцессность позволяет распределить нагрузку на несколько ядер и ускорить обработку.
Обмен данными между потоками осуществляется через общие переменные, но требует синхронизации с помощью Lock или Event. Между процессами данные передаются через Queue или Pipe, что обеспечивает изоляцию памяти и предотвращает случайные изменения данных.

В Python поток создается через класс Thread модуля threading. Для запуска необходимо определить функцию или метод, который будет выполняться в потоке, создать объект Thread с этим целевым объектом и вызвать метод start(). После этого поток переходит в состояние выполнения. Метод join() позволяет дождаться завершения потока перед продолжением основного кода.
Пример создания потока:
t = threading.Thread(target=worker_function)
t.start()
t.join()
Процесс создается через класс Process модуля multiprocessing. Каждый процесс имеет отдельное адресное пространство и не делит память с другими процессами. Для запуска процесса также указывается функция, вызывается start(), а join() используется для ожидания завершения. Процессы подходят для задач с высокой вычислительной нагрузкой, поскольку могут использовать несколько ядер CPU одновременно.
Пример создания процесса:
p = multiprocessing.Process(target=compute_task)
p.start()
p.join()
Для динамического управления количеством потоков используют ThreadPoolExecutor из модуля concurrent.futures, а для процессов – ProcessPoolExecutor. Они автоматизируют распределение задач и управление ресурсами, упрощая запуск параллельных вычислений.
Изоляция памяти: что получает каждый поток и процесс
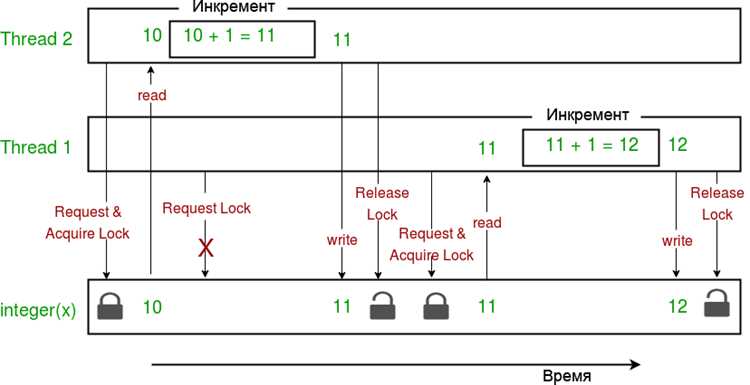
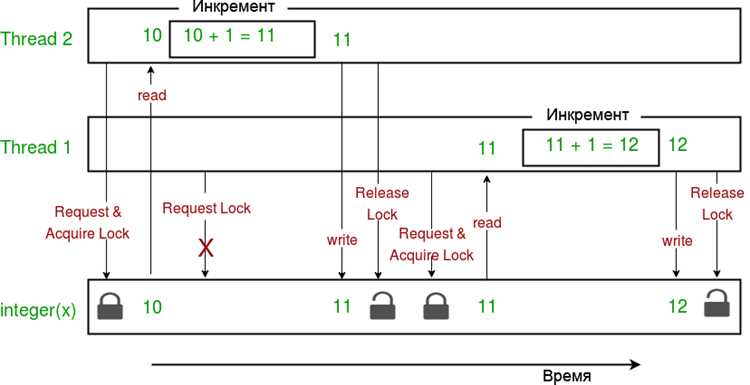
Потоки в Python разделяют память одного процесса. Все глобальные переменные, объекты и структуры данных доступны каждому потоку, что позволяет быстро обмениваться информацией без дополнительного копирования. Однако совместный доступ требует синхронизации с помощью Lock, Semaphore или Event, иначе возможны гонки данных и некорректные результаты.
Процессы создают отдельное адресное пространство. Каждый процесс имеет собственные глобальные переменные и независимые объекты. Изоляция памяти предотвращает случайное изменение данных другими процессами, но обмен информацией требует явного использования Queue, Pipe или совместной памяти через multiprocessing.Value и Array.
Для задач с частым обменом небольшими данными потоки удобнее, так как не требуется сериализация объектов. Для ресурсоемких вычислений и многопроцессорной нагрузки процессы обеспечивают безопасное разделение памяти и использование нескольких ядер без риска влияния на другие вычисления.
Влияние GIL на многопоточность в Python
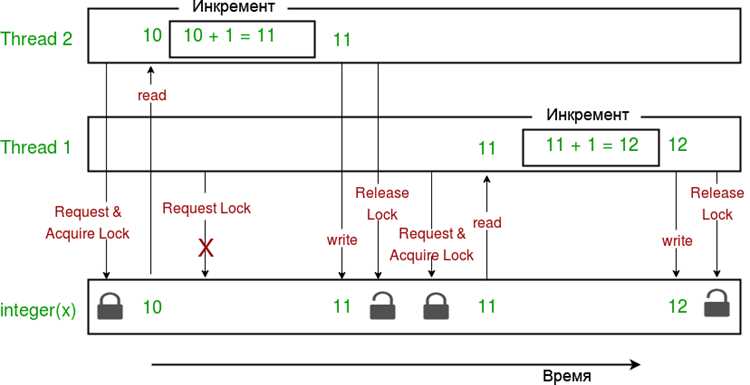
Global Interpreter Lock (GIL) ограничивает одновременное выполнение байт-кода Python в многопоточном приложении. Даже если запущено несколько потоков, только один поток Python-кода выполняется в любой момент времени. Это влияет на производительность вычислительно тяжелых задач.
Ключевые аспекты работы GIL:
- CPU-нагруженные вычисления не ускоряются с увеличением числа потоков.
- Многопроцессность обходится без GIL, так как каждый процесс имеет отдельный интерпретатор Python и отдельный GIL.
Рекомендации по использованию потоков с учетом GIL:
- Для сетевых операций и работы с файлами используйте threading, чтобы уменьшить простой при ожидании данных.
- Для тяжелых вычислений применяйте multiprocessing, чтобы распределить задачи на несколько ядер CPU.
Сравнение скорости выполнения вычислений в потоках и процессах
Потоки в Python ограничены глобальной блокировкой интерпретатора (GIL). Даже при запуске нескольких потоков для вычислительных задач одновременно выполняется только один поток Python-кода. Это делает многопоточность неприменимой для задач с высокой нагрузкой на CPU.
Процессы создают отдельные интерпретаторы Python с собственным GIL и независимым адресным пространством. Это позволяет распределять вычисления между ядрами CPU, увеличивая производительность для числовых и алгоритмических операций.
Наблюдения на практике:
- Многопоточность при суммировании больших массивов или вычислении факториалов не даёт прироста скорости.
- Многопроцессное выполнение тех же задач на 4 ядрах ускоряет обработку почти в 4 раза, если накладные расходы на создание процессов малы по сравнению с вычислениями.
- Процессы потребляют больше памяти и ресурсов ОС, но выигрыш в скорости оправдан при долгих вычислениях.
Рекомендации:
- Для тяжелых вычислений используйте multiprocessing.
- Для задач с небольшими вычислениями или частым обменом данными между потоками подходит threading.
Обмен данными между потоками и между процессами

Потоки делят память одного процесса, поэтому обмен данными осуществляется напрямую через общие переменные. Для предотвращения гонок данных и непредсказуемого поведения необходимо использовать синхронизацию с помощью Lock, RLock, Semaphore или Event. Потоки подходят для обмена небольшими объектами и быстрых операций с памятью.
Процессы имеют отдельные адресные пространства, поэтому прямой доступ к данным невозможен. Для обмена данными используют специальные механизмы:
- Queue – потокобезопасная очередь для передачи объектов между процессами.
- Pipe – канал для двунаправленной передачи данных.
- Shared Memory – объекты Value и Array для совместного доступа к примитивным типам и массивам.
Сравнение потоков и процессов по обмену данными:
| Характеристика | Потоки | Процессы |
|---|---|---|
| Доступ к памяти | Общее адресное пространство | Отдельное адресное пространство |
| Синхронизация | Lock, Semaphore, Event | Queue, Pipe, Shared Memory |
| Производительность передачи данных | Высокая, без сериализации | Средняя, требуется сериализация объектов |
| Использование для задач | Частый обмен небольшими данными | Вычислительные задачи с безопасным разделением данных |
Рекомендации:
- Для интенсивного обмена небольшими объектами используйте потоки с синхронизацией.
- Для больших объемов данных между независимыми вычислениями применяйте процессы и очередь Queue.
- Использование разделяемой памяти оправдано для массивов чисел и больших структур данных при многопроцессной обработке.
Когда лучше использовать поток, а когда процесс в реальном коде

Процессы оправданы для CPU-нагруженных задач, таких как обработка больших массивов, вычисления факториалов или моделирование. Каждый процесс выполняется независимо на отдельном ядре, обходя ограничения GIL и обеспечивая линейное ускорение при увеличении числа процессов.
Рекомендации по выбору:
- Если задача требует частого взаимодействия с внешними ресурсами и малая нагрузка на CPU – используйте потоки.
- Если задача включает интенсивные вычисления, используйте процессы для распределения нагрузки на несколько ядер.
- Оценивайте накладные расходы: процессы требуют больше памяти и времени на создание, потоки – меньше, но ограничены GIL.
Вопрос-ответ:
В чем принципиальная разница между потоками и процессами в Python?
Потоки работают внутри одного процесса и используют общую память, что позволяет быстро обмениваться данными, но они ограничены GIL — одновременно выполняется только один поток Python-кода. Процессы создают отдельные адресные пространства и интерпретаторы Python, обходя GIL, поэтому могут одновременно использовать несколько ядер CPU для вычислений.
Когда стоит использовать потоки вместо процессов?
Потоки лучше подходят для задач, где узким местом является ввод-вывод: сетевые запросы, чтение и запись файлов, работа с базами данных. Они позволяют параллельно запускать несколько операций без высокой нагрузки на CPU и без создания дополнительных процессов.
Как обмен данными между потоками отличается от обмена между процессами?
Потоки делят память одного процесса, поэтому данные можно передавать через общие переменные с использованием синхронизации через Lock, Semaphore или Event. Процессы имеют отдельные адресные пространства, поэтому данные передаются через Queue, Pipe или объекты Shared Memory, что требует сериализации и контроля доступа.
Почему GIL ограничивает многопоточность в Python?
Global Interpreter Lock не позволяет одновременно выполнять несколько потоков Python-кода внутри одного процесса. Это значит, что для вычислительно интенсивных задач увеличение числа потоков не ускоряет выполнение, хотя потоки остаются полезными для операций с вводом-выводом.
Какая стратегия выбора между потоками и процессами подойдет для смешанных задач?
Если приложение сочетает ввод-вывод и тяжёлые вычисления, разумно использовать процессы для вычислительных блоков, чтобы задействовать несколько ядер, и потоки для фоновых операций ввода-вывода, чтобы не блокировать выполнение основного кода. Такой подход позволяет распределять нагрузку и уменьшать простои.
В чем преимущество процессов перед потоками для вычислительно интенсивных задач в Python?
Процессы создают отдельные интерпретаторы Python с собственными GIL и памятью, что позволяет одновременно использовать несколько ядер CPU. Это делает процессы подходящими для задач с большим количеством числовых операций или сложных алгоритмов, где потоки не дают ускорения из-за ограничений GIL.
Как правильно организовать обмен данными между процессами и потоками?
Для потоков данные можно передавать через общие переменные внутри одного процесса, используя синхронизацию через Lock, Semaphore или Event, чтобы избежать гонок данных. Для процессов необходимы Queue, Pipe или Shared Memory, так как каждый процесс имеет отдельное адресное пространство. Это позволяет безопасно обмениваться объектами и массивами между процессами без риска случайного изменения данных.