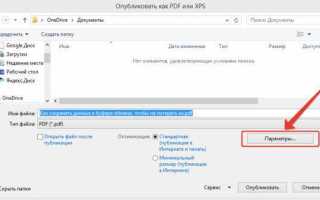
Работа с PDF-файлами часто вызывает сложности при извлечении данных, особенно если нужно скопировать только один столбец таблицы. В стандартном просмотрщике PDF текст в столбцах может объединяться в строки, что делает простое выделение неэффективным. Чтобы избежать ошибок, сначала проверьте, сохранён ли файл как «текстовый PDF» или «сканированный». Для сканированных документов потребуется распознавание текста с помощью OCR.
Если PDF содержит структурированную таблицу, стандартные функции выделения текста позволяют захватить столбец с точностью до символа. В Adobe Reader и Foxit Reader можно использовать инструмент «Выделение текста» с удержанием клавиши Alt для выбора конкретного столбца, а затем вставлять данные в Excel или Google Sheets через Вставка специального формата, чтобы сохранить структуру.
Для больших таблиц или повторяющихся операций удобно использовать специализированное ПО для работы с PDF, такое как Able2Extract, PDFTables или Tabula. Эти программы автоматически распознают границы столбцов и позволяют экспортировать их в CSV или Excel. После копирования всегда проверяйте данные на слияние ячеек и лишние пробелы, чтобы избежать ошибок при последующем анализе.
Проверка структуры PDF перед копированием
Перед копированием столбца важно убедиться, что PDF-файл содержит текстовые данные, а не только изображение страницы. Неправильная структура может привести к объединению ячеек или потере информации при вставке в Excel или Google Sheets.
Рекомендуемые шаги проверки:
- Откройте файл в Adobe Reader или Foxit Reader.
- Попробуйте выделить текст курсором. Если выделение невозможно, файл вероятно сканированный и потребуется OCR.
- Проверьте, как текст выделяется по столбцам. Если курсор прыгает через строки, столбцы не распознаются корректно.
- Сравните визуальное расположение данных и порядок при выделении. Это поможет выявить скрытые объединённые ячейки или разрывы между столбцами.
- Используйте команду Свойства документа → Шрифты, чтобы определить, применены ли стандартные шрифты, которые легко копируются.
Если файл сканированный, рекомендуется применить OCR через Adobe Acrobat Pro, ABBYY FineReader или онлайн-сервисы. После распознавания текста повторите проверку выделения столбцов, чтобы убедиться, что структура таблицы сохранена и столбцы можно копировать без ошибок.
Использование стандартного выделения текста в Adobe Reader
Adobe Reader позволяет копировать отдельные столбцы при помощи инструмента Выделение текста. Для этого откройте PDF и активируйте курсор текста через меню Правка → Выделить текст или сочетание клавиш Ctrl+A для полного выделения с последующей корректировкой.
Чтобы скопировать один столбец:
- Удерживайте клавишу Alt (Windows) или Option (Mac) при выделении текста. Это позволяет выделять вертикальные блоки вместо целых строк.
- Проверьте, чтобы весь текст столбца был полностью захвачен от первой до последней строки, без лишних пробелов слева или справа.
- Скопируйте выделение с помощью Ctrl+C и вставьте в Excel или Google Sheets через Вставка → Вставить специальным образом → Текст, чтобы сохранить формат столбца.
- Если при вставке текст смешивается с соседними столбцами, попробуйте повторное выделение с более точной вертикальной областью или разбейте таблицу на части для копирования.
Регулярная проверка точности выделения до вставки в таблицу минимизирует ошибки и сокращает время на последующую корректировку данных.
Копирование столбца с помощью Excel через вставку специального формата
После выделения столбца в PDF его можно вставить в Excel так, чтобы сохранить вертикальное расположение данных. Для этого используется функция Вставка специального формата.
Пошаговая инструкция:
- Скопируйте текст столбца из PDF с помощью Ctrl+C.
- Откройте Excel и выберите ячейку, с которой начнётся вставка столбца.
- Выберите Главная → Вставить → Вставить специальным образом.
- В появившемся окне выберите Текст или Unicode текст и нажмите ОК. Это позволит Excel распознать каждый элемент столбца как отдельную ячейку.
- Проверьте таблицу на наличие лишних пробелов или объединённых ячеек и при необходимости примените функцию Текст по столбцам через Данные → Текст по столбцам → Разделители.
После вставки столбца данные в Excel будут представлены в виде отдельного столбца таблицы:
| Наименование |
|---|
| Элемент 1 |
| Элемент 2 |
| Элемент 3 |
Использование вставки специальным форматом позволяет избежать слияния столбцов и сохраняет читаемость данных для дальнейшего анализа.
Применение онлайн-сервисов для извлечения столбцов
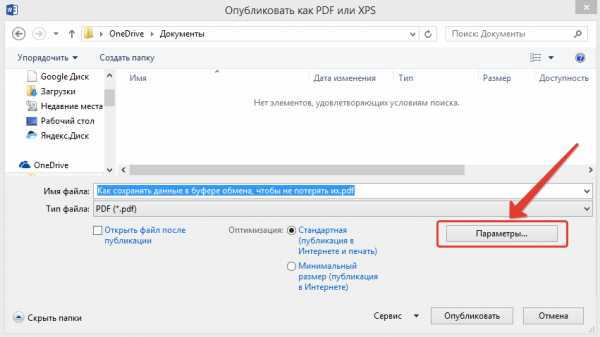
Онлайн-сервисы позволяют быстро извлечь один столбец из PDF без установки дополнительного ПО. Популярные инструменты, такие как ILovePDF, Smallpdf и PDFTables, распознают структуру таблиц и экспортируют данные в Excel или CSV.
Рекомендации по использованию:
- Загрузите PDF на выбранный сервис. Обратите внимание на ограничение размера файла и конфиденциальность данных.
- Выберите режим экспорта в таблицу или Excel/CSV, чтобы столбцы сохранили структуру.
- После загрузки проверьте автоматически выделенный столбец. Если сервис выделил лишние данные, воспользуйтесь функцией редактирования или разделения таблицы.
- Скачайте результат и откройте в Excel для проверки правильности форматирования и корректировки пробелов.
Онлайн-сервисы подходят для одноразового извлечения данных, особенно когда PDF содержит стандартные таблицы с чёткими границами столбцов. Для сканированных документов лучше выбрать сервис с поддержкой OCR для распознавания текста.
Использование специализированного ПО для работы с PDF таблицами

Специализированное ПО облегчает извлечение отдельных столбцов из PDF с высокой точностью, особенно если таблицы сложные или содержат объединённые ячейки. Программы, такие как Able2Extract, Tabula и PDFTables, автоматически распознают структуру таблиц и позволяют экспортировать данные в Excel или CSV.
Рекомендованная последовательность действий:
- Откройте PDF в программе и выберите инструмент распознавания таблиц.
- Определите нужный столбец вручную или с помощью функции выделения столбцов.
- Проверьте предварительный просмотр. Убедитесь, что данные столбца не объединены с соседними столбцами.
- Выберите формат экспорта: Excel, CSV или Текст.
- Сохраните результат и откройте в Excel для окончательной проверки и корректировки пробелов или формата чисел.
Использование специализированного ПО особенно полезно при работе с большими PDF-файлами и регулярном извлечении столбцов, так как оно снижает вероятность ошибок, ускоряет процесс и сохраняет точную структуру данных.
Преобразование PDF в CSV для быстрого выделения столбца
Конвертация PDF в CSV упрощает работу с отдельными столбцами, так как CSV хранит данные в виде отдельных ячеек без лишнего форматирования. Это особенно полезно для таблиц с большим количеством строк и столбцов.
Пошаговые действия:
- Выберите сервис или программу для конвертации PDF в CSV, например Tabula, Adobe Acrobat Pro или онлайн-конвертеры.
- Загрузите PDF и настройте распознавание таблицы. Убедитесь, что границы столбцов определены корректно.
- Экспортируйте файл в CSV. Проверьте разделители столбцов; обычно используется запятая или точка с запятой.
- Откройте CSV в Excel или Google Sheets и выделите нужный столбец для дальнейшей работы.
- При необходимости удалите лишние строки или пустые ячейки для сохранения чистой структуры столбца.
Использование CSV ускоряет процесс извлечения столбцов и минимизирует ошибки, возникающие при прямом копировании из PDF, особенно когда таблицы содержат сложные объединения ячеек или нестандартное форматирование.
Проверка и корректировка скопированных данных после вставки
После вставки столбца из PDF в Excel или Google Sheets важно убедиться, что данные сохранили правильную структуру и формат. Ошибки могут проявляться в виде объединённых ячеек, лишних пробелов или неправильного разделения строк.
Рекомендации по проверке:
- Просмотрите каждую ячейку на наличие лишних пробелов слева и справа и удалите их с помощью функции TRIM или Очистить пробелы.
- Проверьте числовые и текстовые значения. Если числа вставились как текст, примените функцию Преобразовать в число для корректных вычислений.
- Используйте Фильтр для выявления пустых ячеек и дубликатов.
- Если столбец был скопирован с объединёнными ячейками, разбейте их через Разделить ячейки или вручную распределите данные по строкам.
- Сравните исходный PDF и вставленный столбец на случай пропущенных строк или слияния данных с соседними столбцами.
Тщательная проверка после вставки позволяет сохранить точность данных и избежать ошибок при дальнейшем анализе или обработке информации.
Вопрос-ответ:
Почему при копировании столбца из PDF в Excel данные сливаются с соседними ячейками?
Это происходит, когда PDF не содержит чёткой структуры таблицы или текст в столбцах размещён визуально, но не в виде отдельных ячеек. Чтобы избежать слияния, нужно использовать инструменты с поддержкой распознавания таблиц, например Adobe Reader с вертикальным выделением или специализированное ПО, а при вставке в Excel выбирать Вставка специальным образом → Текст.
Как определить, что PDF содержит текст, а не изображение для столбца?
Попробуйте выделить текст курсором в стандартном просмотрщике. Если выделение невозможно или курсор ведёт себя как на картинке, это означает, что PDF является сканированным изображением. В таком случае необходимо применить OCR через программы вроде ABBYY FineReader или онлайн-сервисы с распознаванием текста.
Можно ли скопировать один столбец из большого PDF без установки программ?
Да, для одноразовой работы подходят онлайн-сервисы вроде ILovePDF, Smallpdf или PDFTables. Вы загружаете PDF, выбираете режим экспорта таблицы, скачиваете результат в Excel или CSV, а затем выделяете нужный столбец. Для сложных таблиц с объединёнными ячейками может понадобиться предварительная корректировка.
Почему после вставки столбца из PDF в Excel появляются лишние пробелы и пустые строки?
Это связано с особенностями копирования текста из PDF, где визуальные пробелы могут быть распознаны как символы. Чтобы исправить ситуацию, используйте функции TRIM или Очистить пробелы для удаления лишних пробелов, а пустые строки можно удалить вручную или с помощью фильтров.
Как выделить столбец в PDF с объединёнными ячейками?
Стандартное выделение текста может захватывать объединённые ячейки как единый блок. В таких случаях лучше использовать программы с функцией распознавания таблиц и возможностью выбора отдельных столбцов. После экспорта в Excel или CSV объединённые ячейки можно разделить с помощью функции Текст по столбцам или вручную распределить данные по строкам.
Как правильно выделить один столбец из PDF, если таблица не распознаётся корректно при стандартном копировании?
Если стандартное выделение текста захватывает строки целиком или объединяет соседние столбцы, лучше использовать программы с распознаванием таблиц, такие как Tabula или Able2Extract. В этих приложениях можно вручную указать границы столбца и экспортировать его в Excel или CSV. После экспорта проверьте данные на наличие лишних пробелов и объединённых ячеек, при необходимости используйте функции Excel Текст по столбцам и TRIM для корректировки.