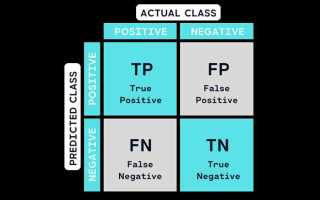
Confusion matrix (или матрица ошибок) – это основной инструмент для оценки качества классификационных моделей в машинном обучении. Она позволяет не только вычислить точность модели, но и понять, какие ошибки она совершает, что в свою очередь помогает улучшить её работу. В отличие от простого показателя точности, матрица ошибок предоставляет подробную картину о том, как модель классифицирует объекты в разные категории, а также позволяет выявить закономерности в ошибках.
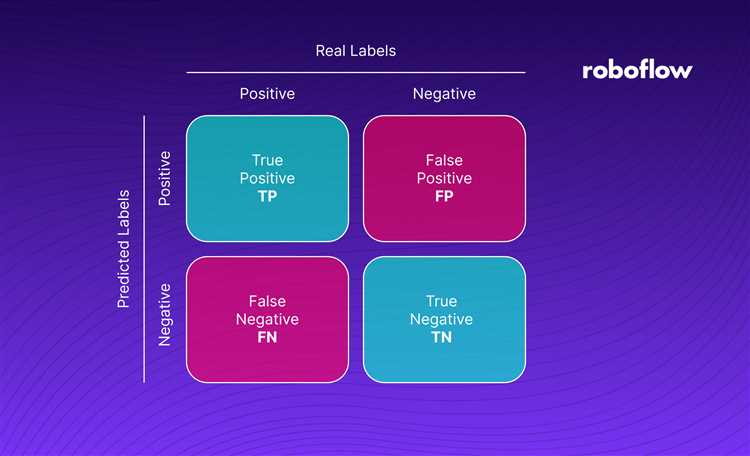
Каждый элемент матрицы представляет собой количество объектов, отнесённых к определённому классу с точки зрения модели, и соотнесённых с реальным классом. Основные параметры, которые из неё извлекаются, включают True Positive (TP), True Negative (TN), False Positive (FP) и False Negative (FN). Понимание этих показателей помогает более точно настраивать алгоритм, выбирая подходящие метрики для разных типов задач.
Использование confusion matrix особенно полезно при работе с несбалансированными данными, где стандартные метрики, такие как точность, могут не дать полного представления о работе модели. Например, если модель слишком часто ошибается в одном классе, это может привести к снижению её общей точности, несмотря на хорошее качество прогнозов для других классов. В таких случаях важно рассматривать recall, precision и F1-меру для более глубокого анализа.
В следующей части статьи мы рассмотрим, как построить и интерпретировать confusion matrix, а также как использовать её для диагностики и улучшения качества классификации.
Confusion matrix: что это и как читать матрицу ошибок
Матрица ошибок (confusion matrix) представляет собой таблицу, которая позволяет наглядно оценить, как классификатор предсказал результаты, а также насколько точно он их классифицировал. Она используется для анализа работы классификационных моделей, например, в задачах бинарной или многоклассовой классификации. В её структуре можно найти четыре ключевых показателя, которые помогают понять, где модель ошибается и насколько она эффективна в разных аспектах.
Матрица ошибок состоит из следующих элементов:
- True Positive (TP) – количество правильно классифицированных положительных примеров (объекты, которые действительно принадлежат к положительному классу и были классифицированы как положительные).
- True Negative (TN) – количество правильно классифицированных отрицательных примеров (объекты, которые действительно принадлежат к отрицательному классу и были классифицированы как отрицательные).
- False Positive (FP) – количество отрицательных примеров, ошибочно классифицированных как положительные (объекты, которые на самом деле принадлежат к отрицательному классу, но были ошибочно классифицированы как положительные).
- False Negative (FN) – количество положительных примеров, ошибочно классифицированных как отрицательные (объекты, которые на самом деле принадлежат к положительному классу, но были ошибочно классифицированы как отрицательные).
С этими показателями легко вычисляются различные метрики для оценки качества модели:
- Точность (Accuracy) – доля правильных предсказаний. Рассчитывается как (TP + TN) / (TP + TN + FP + FN).
- Precision (точность) – доля правильно классифицированных положительных примеров среди всех предсказанных положительных. Формула: TP / (TP + FP).
- Recall (полнота) – доля правильно классифицированных положительных примеров среди всех реальных положительных. Формула: TP / (TP + FN).
- F1-меры – гармоническое среднее между точностью и полнотой. Формула: 2 * (Precision * Recall) / (Precision + Recall).
Важно понимать, что в зависимости от задачи разные метрики могут иметь разное значение. Например, в медицинских исследованиях для задач диагностики важнее иметь высокий recall (чтобы не пропустить заболевания), чем точность, потому что даже малая вероятность ошибки может привести к серьёзным последствиям. В то время как в финансовых приложениях точность может быть более критичной.
Таким образом, правильное чтение и анализ матрицы ошибок позволяет не только оценить общее качество классификации, но и выявить слабые места модели, которые нужно доработать. Это может быть особенно полезно при работе с несбалансированными данными, когда одна из категорий встречается гораздо реже, чем другая, и стандартная точность может не дать полного представления о работе модели.
Что такое confusion matrix и зачем она нужна в машинном обучении
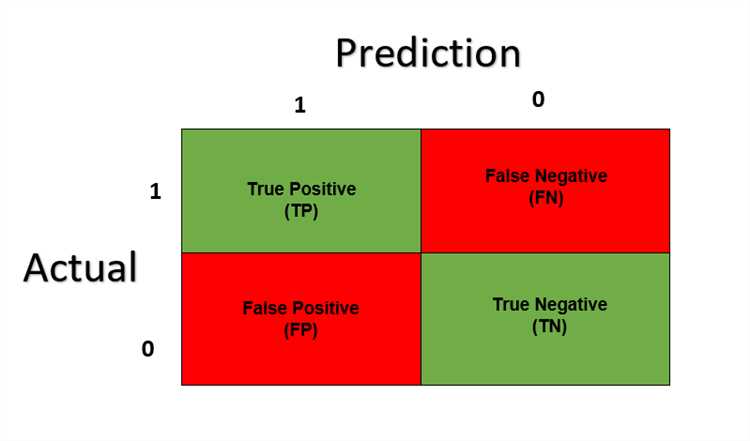
Вместо того чтобы просто вычислять точность модели, confusion matrix помогает выявить, какие классы модель путает друг с другом. Это особенно важно, когда данные несбалансированы, а точность может быть обманчивой. Например, если модель всегда предсказывает отрицательный класс, её точность будет высокой, но это не будет означать, что она полезна для реальных задач, где важно точно предсказать положительные примеры.
Каждый элемент матрицы ошибок позволяет извлечь полезную информацию о поведении модели:
- True Positive (TP) – правильные положительные классификации.
- True Negative (TN) – правильные отрицательные классификации.
- False Positive (FP) – ошибочные положительные классификации.
- False Negative (FN) – ошибочные отрицательные классификации.
С помощью этих данных можно рассчитывать важные метрики, такие как точность, полнота, точность и F1-меру. Эти метрики предоставляют более глубокую информацию о качестве работы модели в разных аспектах. Например, для задач, где важно не пропустить положительные примеры (например, в медицине), важно ориентироваться на recall, а не только на точность.
Матрица ошибок является важным инструментом в процессе обучения модели, поскольку она позволяет не только измерить её эффективность, но и помогает выявить области для улучшения. Например, если модель часто ошибается при классификации одного из классов, это может быть сигналом для дополнительной настройки алгоритма или для работы с несбалансированными данными.
Как интерпретировать элементы матрицы ошибок: TP, TN, FP, FN
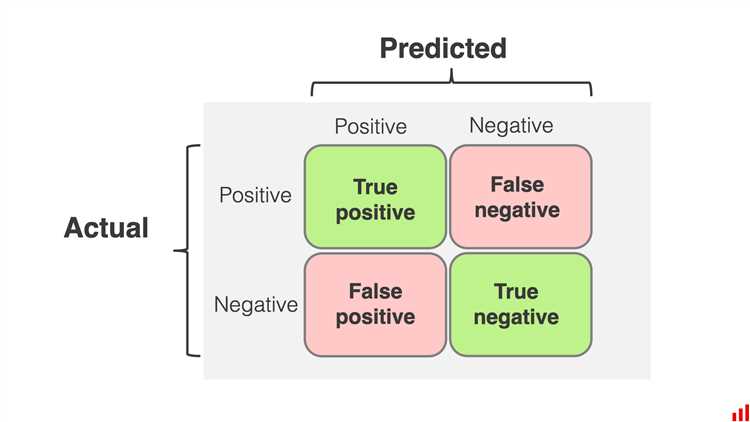
Матрица ошибок состоит из четырёх элементов, которые дают чёткое представление о работе классификационной модели. Каждый из этих элементов имеет своё значение и помогает глубже понять, где модель работает хорошо, а где её необходимо улучшить. Рассмотрим их более подробно:
True Positive (TP) – это количество объектов, которые действительно принадлежат к положительному классу и были правильно классифицированы моделью как положительные. Чем выше это значение, тем лучше модель распознаёт положительные примеры. Например, в задаче диагностики болезни TP – это количество правильно выявленных больных людей.
True Negative (TN) – количество объектов, которые принадлежат к отрицательному классу и были правильно классифицированы моделью как отрицательные. Этот показатель отражает способность модели точно не ошибаться в случае отрицательных примеров. В медицинской диагностике это будут здоровые люди, правильно определённые как здоровые.
False Positive (FP) – это количество объектов, которые принадлежат к отрицательному классу, но были ошибочно классифицированы как положительные. Такая ошибка называется ложным срабатыванием. Например, модель может ошибочно поставить диагноз, что человек болен, хотя на самом деле он здоров. Важно, чтобы это число было как можно меньше, особенно в таких задачах, как диагностика, где ложные положительные могут привести к ненужным обследованиям или лечению.
False Negative (FN) – количество объектов, которые принадлежат к положительному классу, но были ошибочно классифицированы как отрицательные. Это ложный отрицательный результат, который может быть более критичным в некоторых задачах. Например, если модель пропустит больного человека, который останется без диагностики и лечения, последствия могут быть серьёзными. Поэтому важно стремиться минимизировать это значение в таких областях, как медицина и безопасность.
Каждый из этих элементов может быть использован для вычисления различных метрик, таких как точность, полнота, точность (precision) и F1-меру. Интерпретация этих элементов в контексте задачи помогает понять, где модель совершает ошибки, и какие именно ошибки она делает. Например, если модель ошибается в классификации отрицательных примеров (большие значения FP), это может означать, что она слишком часто ошибается в свою пользу. Если же ошибки связаны с положительными примерами (FN), это может указывать на необходимость улучшения обнаружения важных объектов.
Как вычислить точность модели на основе confusion matrix

Формула для расчёта точности выглядит так:
Точность = (TP + TN) / (TP + TN + FP + FN)
Где:
- TP – количество правильно классифицированных положительных примеров;
- TN – количество правильно классифицированных отрицательных примеров;
- FP – количество отрицательных примеров, ошибочно классифицированных как положительные;
- FN – количество положительных примеров, ошибочно классифицированных как отрицательные.
Точность рассчитывается как сумма правильных предсказаний (TP и TN), делённая на общее количество всех примеров. Эта метрика полезна, когда классы в задаче сбалансированы, то есть количество примеров каждого класса примерно одинаково. В таких случаях точность даёт хорошее представление о том, насколько модель выполняет свою задачу.
Однако, если данные сильно несбалансированы, точность может быть обманчивой. Например, если модель классифицирует все примеры как принадлежащие к отрицательному классу, её точность может быть высокой, но она не будет полезной для реальной задачи. В таких случаях стоит дополнительно оценивать другие метрики, такие как precision, recall и F1-меру, чтобы получить более полное представление о качестве работы модели.
Важно помнить, что точность – это лишь одна из метрик, и её нужно учитывать в контексте других показателей, чтобы объективно оценить производительность классификатора. Особенно это важно, когда вы имеете дело с задачами, где ошибки в классификации одного из классов могут быть более критичными, чем в других.
Как использовать recall и precision для анализа модели

Recall (полнота) измеряет способность модели обнаруживать все положительные примеры в данных. Эта метрика важна, когда критично не пропустить положительные объекты. Recall рассчитывается по формуле:
Recall = TP / (TP + FN)
Здесь TP – это количество верно классифицированных положительных примеров, а FN – количество положительных примеров, которые модель ошибочно отнесла к отрицательному классу. Высокий recall означает, что модель редко пропускает положительные примеры, что особенно важно в задачах, где нужно минимизировать ложные отрицательные (например, в медицине).
Precision (точность) отражает, насколько правильно модель классифицирует объекты как положительные среди всех объектов, которые она предсказала как положительные. Это критично, когда ложные положительные ошибки могут быть более дорогими, чем пропуск положительного примера. Precision вычисляется по формуле:
Precision = TP / (TP + FP)
Здесь FP – это количество отрицательных примеров, которые модель ошибочно классифицировала как положительные. Высокая precision означает, что из всех предсказанных положительных объектов большинство действительно являются положительными.
Обе эти метрики дают полезную информацию, но они отражают разные аспекты работы модели. Например, если ваша задача – минимизировать количество ложных отрицательных, вам важно увеличить recall, даже если это приведёт к снижению precision. В случае, если важно избегать ложных положительных, стоит больше ориентироваться на precision. В идеале, баланс между этими метриками можно найти с помощью F1-меры, которая является гармоническим средним recall и precision.
Таким образом, использование recall и precision помогает не только измерить общую точность модели, но и выявить, на каких ошибках она ошибается, что помогает более точно настроить алгоритм и улучшить его поведение в зависимости от требований задачи.
Что такое F1-скор и как он связан с матрицей ошибок
F1-скор вычисляется по формуле:
F1 = 2 * (Precision * Recall) / (Precision + Recall)
Этот показатель особенно полезен, когда важен компромисс между recall и precision. Если модель слишком фокусируется на одном из этих показателей, её общая производительность может быть нарушена. F1-скор позволяет объединить информацию о том, как хорошо модель находит положительные примеры (recall), и насколько она точна при их классификации (precision).
Связь между F1-скором и матрицей ошибок очевидна: все элементы матрицы – TP, TN, FP, FN – влияют на вычисление точности и полноты, а значит, и на F1-скор. Например, увеличение TP (правильно классифицированных положительных) повысит как recall, так и precision, улучшив тем самым F1-скор. В то время как увеличение FP или FN приведёт к снижению одной из этих метрик и, как следствие, снижению F1-скора.
F1-скор полезен в задачах с несбалансированными данными, где одна из классовых категорий встречается реже, чем другая. В таких ситуациях точность может быть высоким числом, даже если модель ошибается в предсказаниях относительно меньшего класса. Используя F1-скор, можно добиться более справедливой оценки модели, учитывающей ошибки в обеих категориях.
Таким образом, F1-скор – это ключевая метрика для анализа моделей, где важно минимизировать как ложные положительные, так и ложные отрицательные результаты, и он помогает более точно оценивать производительность классификаторов в сложных задачах.
Как построить confusion matrix в Python с помощью библиотеки scikit-learn
Для построения confusion matrix в Python используется библиотека scikit-learn, которая предоставляет простой и удобный инструмент для анализа качества классификационных моделей. Для этого необходимо использовать функцию confusion_matrix(), которая принимает два аргумента: истинные значения (реальные метки классов) и предсказанные моделью значения.
Пример построения матрицы ошибок в Python:
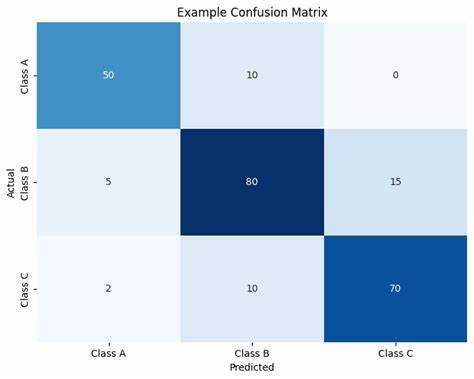
from sklearn.metrics import confusion_matrix # Истинные метки классов y_true = [0, 1, 0, 1, 0, 1, 0, 1] # Предсказания модели y_pred = [0, 0, 0, 1, 0, 1, 1, 1] # Построение confusion matrix cm = confusion_matrix(y_true, y_pred) print(cm)
Этот код создаст confusion matrix, сравнив истинные и предсказанные значения. На выходе вы получите массив, где:
- Первый элемент (первый ряд, первый столбец) – количество верно классифицированных отрицательных примеров (True Negatives, TN);
- Второй элемент (первый ряд, второй столбец) – количество ложных положительных предсказаний (False Positives, FP);
- Третий элемент (второй ряд, первый столбец) – количество ложных отрицательных предсказаний (False Negatives, FN);
- Четвертый элемент (второй ряд, второй столбец) – количество верно классифицированных положительных примеров (True Positives, TP).
После получения матрицы можно визуализировать её с помощью matplotlib или seaborn, чтобы легче интерпретировать результаты:
import seaborn as sns
import matplotlib.pyplot as plt
# Визуализация confusion matrix
sns.heatmap(cm, annot=True, fmt="d", cmap="Blues", xticklabels=["0", "1"], yticklabels=["0", "1"])
plt.xlabel("Предсказанный")
plt.ylabel("Истинный")
plt.title("Confusion Matrix")
plt.show()
С помощью этой визуализации можно наглядно увидеть, сколько примеров было правильно классифицировано, а сколько – ошибочно. Это поможет быстро определить, где модель нуждается в улучшении.
Таким образом, построение confusion matrix в Python с использованием библиотеки scikit-learn является простым, но мощным инструментом для анализа и улучшения качества классификационных моделей.
Что делать, если модель дает сбалансированные ошибки: пример анализа
Когда модель даёт сбалансированные ошибки, это означает, что количество ложных положительных (FP) и ложных отрицательных (FN) примерно одинаково. Такой результат может указывать на несколько различных проблем или особенностей в данных, которые требуют дополнительного анализа и корректировки модели.
Пример сбалансированных ошибок: предположим, что модель для задачи классификации находит одинаковое количество ложных положительных и ложных отрицательных. Это может быть признаком того, что модель не делает явного предпочтения одному из классов, что в некоторых случаях может быть желаемым результатом, но в других – сигнализировать о неэффективной работе модели.
Что делать в такой ситуации:
- Провести анализ данных. Сбалансированные ошибки могут быть результатом неправильной или неполной выборки данных. Например, если классы в выборке недостаточно репрезентативны, модель может не обучаться должным образом. Рекомендуется провести более тщательную проверку данных, возможно, стоит провести перераспределение данных или использовать технику oversampling для недопредставленных классов.
- Использовать метрики, такие как F1-скор. Точность может быть не лучшим показателем при сбалансированных ошибках. Если модель одинаково ошибается по обоим классам, важнее будет оценить её performance через F1-скор, который учитывает как точность, так и полноту. Это поможет выявить, насколько хорошо модель находит правильные примеры, минимизируя ошибки с обеих сторон.
- Проблемы с threshold. Часто сбалансированные ошибки возникают, когда модель использует стандартный порог (threshold) для принятия решений. Попробуйте настроить порог для классификации (например, изменить его с 0.5 на более подходящее значение), чтобы сместить предпочтение в сторону одного из классов. Это поможет уменьшить количество ложных положительных или ложных отрицательных.
- Проверить модель на разные гиперпараметры. Возможно, модель не настроена оптимально. Регулировка гиперпараметров, таких как регуляризация или параметры для деревьев решений, может уменьшить сбалансированные ошибки, улучшив общий результат.
- Использовать более сложные модели. Иногда более сложные модели, такие как ансамбли или нейронные сети, могут справляться с проблемами сбалансированных ошибок лучше, чем простые алгоритмы. Рассмотрите использование методов, таких как Random Forest или XGBoost, которые могут обеспечить лучшую работу с несбалансированными данными и ошибками.
В случае сбалансированных ошибок ключевым моментом является выявление причины такого поведения модели. Использование метрик, которые оценивают как полноту, так и точность, таких как F1-скор, поможет объективно оценить эффективность модели, а корректировка подходов к обработке данных и настройке гиперпараметров может значительно улучшить её работу.
Вопрос-ответ:
Что такое confusion matrix и как она помогает в анализе модели?
Confusion matrix — это таблица, которая используется для оценки качества классификационной модели. Она позволяет понять, сколько правильных и ошибочных предсказаний модель сделала для каждого класса. В отличие от общей точности, confusion matrix даёт подробную информацию о том, как модель ошибается. Это позволяет выявить, какие классы модель путает и где она может быть улучшена. Используя такие показатели, как точность, полнота и F1-скор, можно получить более полную картину о производительности модели, особенно в случае несбалансированных данных.
Как интерпретировать ложные положительные и ложные отрицательные ошибки в матрице ошибок?
Ложные положительные ошибки (FP) возникают, когда модель ошибочно классифицирует отрицательные примеры как положительные. Это может привести к ненужным действиям, например, неправильной диагностике или ненужному лечению в медицине. Ложные отрицательные ошибки (FN) происходят, когда модель не распознает положительные примеры и классифицирует их как отрицательные. Это может быть более опасным, например, если модель не выявляет заболевание, которое на самом деле присутствует у пациента. Важно анализировать баланс этих ошибок в зависимости от задачи, чтобы минимизировать негативные последствия.
Можно ли использовать confusion matrix для многоклассовых задач?
Да, confusion matrix можно использовать для многоклассовых задач. В этом случае она будет представлять собой матрицу размером n x n, где n — количество классов. Каждый элемент матрицы будет показывать, сколько объектов из одного класса было предсказано как другой класс. В многоклассовых задачах важно анализировать не только общую точность, но и классификацию каждого класса отдельно. Для этого можно использовать такие метрики, как макро-среднее и микро-среднее для precision, recall и F1-меры, чтобы получить сводные показатели по всем классам.
Как confusion matrix помогает в выборе метрик для модели?
Confusion matrix позволяет глубже понять, как модель классифицирует данные, а также выделить, где именно она ошибается. Например, на основе матрицы можно рассчитать точность, полноту и F1-меру, что помогает выбрать оптимальные метрики для задачи. Если важно избежать ложных положительных ошибок, стоит ориентироваться на precision. Если же задача требует максимального покрытия всех положительных примеров, то следует обратить внимание на recall. В случае, когда важно сбалансировать точность и полноту, F1-скор станет полезной метрикой. Confusion matrix помогает делать такие выборы более осознанно, учитывая тип ошибок модели.