Содержание статьи

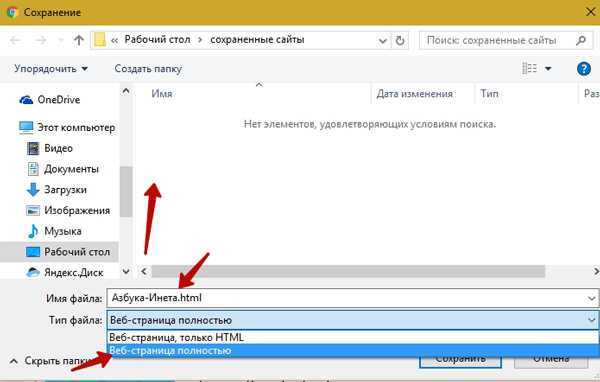
Сохранение HTML страницы на локальный диск позволяет анализировать контент без постоянного доступа к интернету и автоматизировать сбор данных. Для этого чаще всего используют библиотеку requests, которая позволяет получить исходный код страницы методом GET и сохранить его в текстовый файл через open() с указанием кодировки UTF-8.
Если страница использует динамическую подгрузку контента через JavaScript, стандартные HTTP-запросы будут возвращать неполный HTML. В таких случаях применяется Selenium, который управляет браузером, позволяет дождаться загрузки элементов и получить финальный HTML методом driver.page_source. Это особенно важно для сайтов с таблицами, графиками или интерактивными компонентами.
При массовом сохранении страниц стоит учитывать ограничения сервера: таймауты, блокировки по IP и требования к заголовкам User-Agent. Рекомендуется добавлять headers в запросы и использовать задержки между загрузками, чтобы снизить риск блокировки.
Для проектов, где важно сохранить не только HTML, но и связанные ресурсы (CSS, JS, изображения), можно комбинировать requests с библиотеками типа BeautifulSoup для парсинга ссылок на файлы. Это позволяет создавать локальные копии страниц с визуально идентичным отображением.
Таким образом, Python предоставляет полный инструментарий для скачивания как статических, так и динамических веб-страниц, с возможностью обработки ошибок и автоматизации повторяющихся задач. Практическое применение включает архивирование контента, парсинг данных и тестирование интерфейсов.
Установка и настройка библиотек для работы с веб-страницами
Для скачивания HTML страниц в Python чаще всего используют requests и urllib. Установка requests выполняется через команду pip install requests, при этом рекомендуется проверять версию Python: библиотека поддерживает версии 3.6 и выше. Для автоматизации работы с динамическими страницами понадобится Selenium, которую устанавливают через pip install selenium и подключают соответствующий веб-драйвер для браузера (Chrome, Firefox, Edge).
Для удобного парсинга и извлечения элементов из HTML применяют BeautifulSoup из пакета bs4, устанавливаемого через pip install beautifulsoup4. Рекомендуется сразу указать кодировку при создании объекта BeautifulSoup: BeautifulSoup(html, «html.parser»), чтобы избежать ошибок с кириллицей и спецсимволами.
При работе с Selenium важно синхронизировать версию веб-драйвера с версией браузера. Для Chrome можно использовать webdriver-manager (pip install webdriver-manager) для автоматической загрузки актуального драйвера и уменьшения риска несовместимости. Дополнительно можно настроить headless-режим браузера, чтобы страницы загружались без отображения окна, что ускоряет процесс и снижает нагрузку на систему.
Для тестирования установки и корректной работы библиотек рекомендуется сначала выполнить простой запрос через requests к https://example.com и вывести код страницы, а для Selenium проверить, что driver.get(«https://example.com») возвращает содержимое с динамическими элементами. Это позволяет убедиться, что среда настроена правильно перед массовым сохранением страниц.
Скачивание HTML с помощью requests и сохранение в файл

Для получения исходного кода страницы используйте метод requests.get(url). Рекомендуется передавать заголовок User-Agent в параметре headers, чтобы сервер корректно обрабатывал запросы и не блокировал их как бот-трафик. Например: headers = {‘User-Agent’: ‘Mozilla/5.0’}.
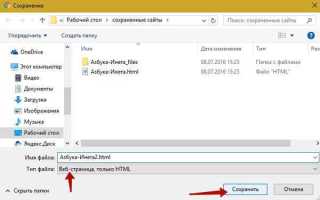
После получения ответа проверяйте статус код: response.status_code == 200 гарантирует успешную загрузку. Сохранять HTML следует в файл с указанием кодировки UTF-8: with open(‘page.html’, ‘w’, encoding=’utf-8′) as f: f.write(response.text). Это предотвращает искажение кириллических символов и спецсимволов.
Если страница содержит большие объемы данных, рекомендуется использовать stream=True в запросе и записывать HTML по частям с помощью iter_content(chunk_size=1024), чтобы избежать переполнения памяти при сохранении больших файлов.
Для повторного скачивания нескольких страниц удобно использовать цикл и формировать уникальные имена файлов, например f’page_{i}.html’. Это позволяет автоматизировать процесс без перезаписи ранее сохраненных файлов.
Использование Selenium для сохранения динамического контента

Selenium позволяет взаимодействовать с веб-страницами, где HTML формируется динамически через JavaScript. Для запуска браузера используют webdriver.Chrome() или webdriver.Firefox() и передают путь к драйверу или используют webdriver-manager для автоматической синхронизации версий.
После открытия страницы командой driver.get(url) важно дождаться загрузки необходимых элементов. Для этого применяют WebDriverWait с условиями ожидания: EC.presence_of_element_located((By.CSS_SELECTOR, ‘.target-class’)). Это предотвращает сохранение неполного HTML.
Сохранение HTML осуществляется через driver.page_source, который возвращает текущее состояние DOM. Рекомендуется сохранять результат с кодировкой UTF-8: with open(‘dynamic_page.html’, ‘w’, encoding=’utf-8′) as f: f.write(driver.page_source).
Для ускорения процесса при массовом сохранении страниц можно использовать headless-режим, добавив опцию options.add_argument(‘—headless’). Также полезно очищать кэш и куки между запросами через driver.delete_all_cookies(), чтобы получать свежий контент.
Обработка ошибок при загрузке страниц и таймауты

При скачивании HTML с помощью Python важно предусмотреть обработку ошибок и корректные таймауты, чтобы скрипт не зависал и не прерывался из-за сетевых проблем.
- Используйте параметр timeout в requests: requests.get(url, timeout=10). Значение в секундах определяет максимальное время ожидания ответа сервера.
- Обрабатывайте исключения через try-except: requests.exceptions.Timeout, requests.exceptions.ConnectionError и requests.exceptions.HTTPError. Это позволяет логировать ошибки и повторять запросы.
- Для повторных попыток применяйте backoff или циклы с задержкой: time.sleep(5) между попытками предотвращает перегрузку сервера.
- При работе с Selenium используйте page_load_timeout и implicitly_wait: driver.set_page_load_timeout(15) и driver.implicitly_wait(5). Это гарантирует, что драйвер не будет ожидать бесконечно при медленной загрузке страниц.
- Логируйте URL и код ошибки в отдельный файл, чтобы анализировать проблемные страницы и исключить повторяющиеся сбои.
Комбинация таймаутов, обработки исключений и повторных попыток позволяет создавать стабильные скрипты для массового сохранения HTML страниц без остановки из-за нестабильного соединения или медленных серверов.
Сохранение связанных ресурсов: CSS, JS и изображения
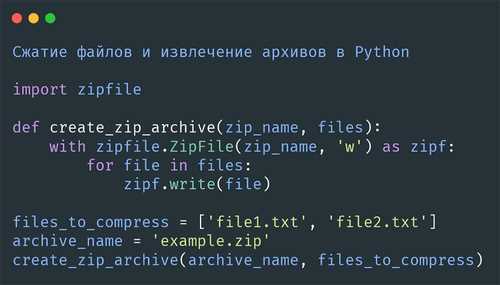
Для корректного отображения сохраненной страницы необходимо сохранять не только HTML, но и связанные файлы: CSS, JS и изображения. Их можно извлечь с помощью BeautifulSoup или регулярных выражений.
CSS-файлы находятся в тегах <link rel=»stylesheet»>. Для каждого найденного href выполняют запрос requests.get() и сохраняют содержимое в локальную папку, например css/. После этого ссылки в HTML можно заменить на локальные пути.
JS-файлы подключаются через <script src=»…»></script>. Алгоритм аналогичен CSS: скачивание содержимого и сохранение с повторной заменой пути в HTML. Для динамических скриптов, загружаемых через Ajax, Selenium позволяет получить сгенерированные ссылки и сохранить их вручную.
Изображения хранятся в тегах <img src=»…»>. Для скачивания учитывайте относительные и абсолютные пути: urljoin(base_url, img_src). Размер chunk_size лучше установить 1024–4096 байт, чтобы избежать переполнения памяти при больших файлах.
После сохранения всех ресурсов рекомендуется проверить локальную копию страницы в браузере и убедиться, что CSS и JS корректно применяются, а изображения отображаются без ошибок. Это гарантирует полную автономность локальной версии страницы.
Автоматизация сохранения нескольких страниц через цикл
Для массового сохранения страниц используют циклы, которые перебирают список URL или формируют их программно. Это позволяет избежать ручного скачивания каждой страницы и гарантирует единообразное именование файлов.
Простейший подход – создать список URL и пройтись по нему в цикле for, сохраняя HTML через requests:
| Пример кода |
import requests
urls = ['https://site.com/page1', 'https://site.com/page2', 'https://site.com/page3']
for i, url in enumerate(urls, 1):
try:
response = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'}, timeout=10)
response.raise_for_status()
with open(f'page_{i}.html', 'w', encoding='utf-8') as f:
f.write(response.text)
except requests.exceptions.RequestException as e:
print(f'Ошибка загрузки {url}: {e}')
|
Для страниц с динамическим контентом цикл можно объединить с Selenium, применяя driver.get(url) и driver.page_source. Важно добавлять time.sleep() между запросами, чтобы сервер не заблокировал IP, и очищать куки для каждой новой страницы.
Автоматизация через цикл также позволяет логировать успешные и неудачные загрузки в отдельный файл. Это упрощает повторное выполнение скрипта только для неудачных страниц без перезаписи ранее сохраненных HTML файлов.
Вопрос-ответ:
Можно ли сохранить страницу, которая подгружает данные через JavaScript, с помощью requests?
Нет, requests возвращает только исходный HTML, который сервер отправляет при первом запросе. Контент, который подгружается динамически через JavaScript, не появится в сохраненном файле. Для таких страниц нужно использовать Selenium или другой инструмент, который управляет браузером и позволяет дождаться полной загрузки DOM.
Как правильно обрабатывать ошибки при скачивании нескольких страниц подряд?
Для обработки ошибок создают блоки try-except, где ловят исключения requests, например Timeout, ConnectionError и HTTPError. Рекомендуется логировать URL и текст ошибки в отдельный файл, чтобы повторно пытаться скачать только те страницы, которые не удалось загрузить с первого раза. Также полезно ставить задержку между запросами через time.sleep(), чтобы сервер не блокировал скрипт.
Каким образом сохранить изображения, CSS и JS вместе с HTML?
Сначала нужно получить HTML и проанализировать его с помощью BeautifulSoup, извлекая теги <img>, <link rel=»stylesheet»> и <script src>. Для каждого ресурса выполняют запрос через requests и сохраняют в соответствующую папку, например css/, js/ или images/. Затем в HTML заменяют исходные ссылки на локальные пути, чтобы при открытии страницы в браузере ресурсы подгружались корректно.
Как автоматизировать сохранение большого числа страниц с одинаковой структурой URL?
Создают цикл, который генерирует или перебирает список URL, и для каждого выполняют запрос через requests или Selenium. Файлы сохраняют с уникальными именами, например page_1.html, page_2.html и так далее. Для динамических страниц добавляют ожидание элементов через WebDriverWait. Также полезно вести лог успешных и неудачных загрузок, чтобы можно было повторно обработать только проблемные страницы.