Содержание статьи

Серверный обработчик – это программный компонент, который получает запросы от клиента, анализирует их и формирует ответ. В современных веб-приложениях обработчики часто реализуются через фреймворки вроде Node.js, Django или Spring, что позволяет настраивать маршрутизацию и управлять потоками данных.
Каждый обработчик имеет конкретную задачу: чтение параметров запроса, проверка их корректности, взаимодействие с базой данных и генерация ответа в формате JSON или HTML. Для уменьшения времени отклика рекомендуется ограничивать сложные вычисления в обработчике и использовать кэширование часто запрашиваемых данных.
Обработчики поддерживают работу с различными HTTP-методами. Например, GET используется для получения данных, а POST – для отправки информации на сервер. Практическая настройка маршрутов позволяет направлять конкретные запросы на соответствующие функции и оптимизировать обработку больших потоков пользователей.
Важно предусмотреть обработку ошибок и исключений: некорректные данные, сбои соединения или недоступность базы данных должны фиксироваться в логах и возвращать информативный ответ клиенту. Регулярная проверка логов и мониторинг производительности помогают выявлять узкие места и снижать риск сбоев при высокой нагрузке.
Серверный обработчик не ограничивается простым обменом данными. Он также управляет сессиями, авторизацией и безопасностью запросов. Правильная настройка ограничений и таймаутов предотвращает зависания и защищает сервер от перегрузок, что особенно критично для сервисов с большим числом одновременных подключений.
Роль серверного обработчика в обработке HTTP-запросов

Серверный обработчик принимает HTTP-запросы от клиента и выполняет их разбор на уровне протокола. Он извлекает метод запроса, заголовки, параметры URL и тело запроса, после чего направляет данные на соответствующую функцию обработки. Корректная маршрутизация запросов снижает вероятность задержек и исключений при высокой нагрузке.
Обработчик определяет тип запроса: GET для чтения ресурсов, POST для создания записей, PUT для обновления и DELETE для удаления. Практическая рекомендация – разделять логику обработки разных методов, чтобы минимизировать конфликты и упростить поддержку кода.
В процессе обработки серверный обработчик может взаимодействовать с базой данных, кэшами и сторонними сервисами. Использование асинхронных вызовов помогает избегать блокировки потока и ускоряет отклик на запросы, особенно при работе с внешними API.
Обработчик формирует окончательный ответ, включая статус HTTP, заголовки и тело данных, и отправляет его клиенту. Рекомендация по оптимизации – минимизировать размер передаваемого контента и использовать сжатие, что снижает нагрузку на сеть и ускоряет время загрузки страницы.
Как серверный обработчик получает и интерпретирует данные клиента
Серверный обработчик получает данные клиента через HTTP-запросы, которые могут содержать параметры в URL, тело запроса или заголовки. Для корректной работы важно различать источники данных и выбирать подходящий метод извлечения.
- Параметры URL: используются для передачи идентификаторов и фильтров. Обработчик парсит строку запроса и конвертирует значения в нужный тип данных.
- Тело запроса: применяется для передачи структурированных данных, чаще в формате JSON или form-data. Рекомендуется проверять схему данных и валидировать все поля перед использованием.
- Заголовки: содержат метаинформацию о клиенте, токены авторизации, тип контента. Интерпретация заголовков позволяет настроить обработку запроса и безопасность.
Для повышения надежности серверный обработчик выполняет следующие шаги:
- Разбор запроса и выделение ключевых элементов: метод, путь, параметры и тело.
- Проверка корректности данных: типы, обязательные поля, длина строк, допустимые значения.
- Очистка входных данных для предотвращения SQL-инъекций и XSS-атак.
- Конвертация формата данных в структуру, удобную для дальнейшей обработки внутри приложения.
Практическая рекомендация: использовать встроенные функции фреймворков для парсинга JSON и валидации параметров, чтобы снизить риск ошибок и ускорить обработку запросов.
Обработка разных типов запросов: GET, POST, PUT, DELETE
Серверный обработчик различает HTTP-методы для определения действий с ресурсами. Каждый метод имеет специфическую роль и требования к обработке данных.
| Метод | Назначение | Особенности обработки | Рекомендации |
|---|---|---|---|
| GET | Получение данных с сервера | Параметры передаются через URL, тело запроса игнорируется | Использовать для запросов без изменений данных, кешировать часто используемые ответы |
| POST | Создание новых записей | Данные передаются в теле запроса, обычно в формате JSON или form-data | Проверять обязательные поля, валидировать и фильтровать данные перед сохранением |
| PUT | Обновление существующих записей | Тело запроса содержит полные данные ресурса для замены | Проверять существование ресурса, обновлять только допустимые поля |
| DELETE | Удаление ресурсов | Идентификатор ресурса передается через URL или тело запроса | Подтверждать удаление, логировать действия для восстановления при необходимости |
Практическая рекомендация: разграничивать обработчики по методам для упрощения поддержки и предотвращения конфликтов, использовать middleware для общей валидации и авторизации запросов.
Использование маршрутизации для распределения запросов
Маршрутизация позволяет серверному обработчику направлять входящие HTTP-запросы к конкретным функциям в зависимости от URL и метода запроса. В современных фреймворках, таких как Express, Django или Spring, маршруты описываются в виде шаблонов с переменными, что упрощает обработку динамических данных.
Для оптимальной маршрутизации рекомендуется:
- Использовать четкую иерархию URL, отражающую структуру ресурсов (например, /users/{id}/orders).
- Разделять маршруты по методам: отдельные функции для GET, POST, PUT и DELETE позволяют избежать ошибок при изменении логики.
- Применять middleware для общей обработки запросов, таких как авторизация, проверка формата данных и логирование.
- Использовать именованные маршруты для упрощения генерации URL в коде и уменьшения числа жестко закодированных ссылок.
Практическая рекомендация: тестировать каждый маршрут с разными комбинациями параметров и методами запроса, чтобы убедиться в корректной маршрутизации и предсказуемой обработке ошибок.
Взаимодействие с базой данных через серверный обработчик

Серверный обработчик обеспечивает связь между клиентскими запросами и базой данных. Он формирует SQL-запросы или использует ORM для чтения, создания, обновления и удаления записей. Правильная структура запросов снижает нагрузку на сервер и минимизирует время отклика.
Для надежного взаимодействия с базой данных рекомендуется:
- Валидация входных данных перед отправкой в запрос, чтобы исключить SQL-инъекции и некорректные значения.
- Использование транзакций для операций, затрагивающих несколько таблиц, чтобы сохранить целостность данных.
- Применение индексов и оптимизированных запросов для ускорения выборки больших объемов данных.
- Кэширование часто запрашиваемых данных, чтобы снизить число обращений к базе и уменьшить нагрузку.
Серверный обработчик должен отслеживать ошибки базы данных и возвращать клиенту информативный, но безопасный ответ. Логирование и мониторинг помогают выявлять узкие места в работе с базой и предотвращать простои приложения.
Формирование и отправка ответа клиенту
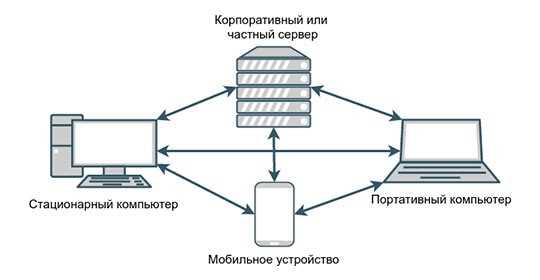
После обработки запроса серверный обработчик формирует ответ в формате, который понимает клиент. Наиболее распространённые форматы – HTML, JSON, XML и бинарные данные. Для REST API обычно используется JSON, для веб-страниц – HTML с корректными заголовками Content-Type.
Перед отправкой важно установить правильный HTTP-статус. Например, 200 указывает на успешную обработку, 404 – на отсутствие ресурса, 500 – на внутреннюю ошибку сервера. Неправильный статус может привести к некорректной обработке на стороне клиента и затруднить отладку.
Заголовки ответа управляют кэшированием, типом содержимого и длиной данных. Заголовок Content-Length ускоряет передачу больших файлов, а Cache-Control и ETag помогают клиенту повторно использовать закэшированные данные, снижая нагрузку на сервер. Для передачи файлов часто используют Content-Disposition с указанием имени и режима скачивания.
Формирование тела ответа требует строгого соответствия спецификации выбранного формата. Для JSON следует избегать невалидных символов и гарантировать корректную сериализацию объектов. Для HTML – закрывать теги и экранировать специальные символы, чтобы предотвратить XSS-уязвимости.
После подготовки заголовков и тела данные отправляются через сетевой сокет клиенту. Серверные фреймворки обычно управляют буферизацией, но при больших объёмах рекомендуется использовать потоковую передачу, чтобы минимизировать задержки и потребление памяти.
Логирование отправленных ответов помогает отслеживать ошибки и анализировать производительность. Включение точной информации о времени формирования ответа и размере данных позволяет оптимизировать обработку и ускорить взаимодействие с клиентами.
Обработка ошибок и логирование на сервере
Серверный обработчик должен разделять ошибки клиентского и серверного уровня. Клиентские ошибки, например 400 или 404, возвращаются с корректными статусами и минимальной информацией, чтобы не раскрывать внутреннюю логику. Серверные ошибки 500 фиксируются в логах с полным стек-трейсом и деталями запроса для последующего анализа.
Логирование следует строить по уровням: INFO для успешных операций, WARN для потенциальных проблем, ERROR для критических сбоев. Каждая запись должна содержать метку времени, идентификатор запроса, IP клиента и параметры запроса, чтобы точно воспроизвести ситуацию при отладке.
Для высоконагруженных систем рекомендуется асинхронная запись логов в файл или внешнюю систему мониторинга, чтобы не блокировать обработку запросов. Логи больших объёмов разделяют по дате или размеру файла и архивируют для экономии дискового пространства.
Ошибки валидации данных следует фиксировать отдельно, чтобы различать проблемы на стороне клиента и баги в логике сервера. Использование структурированных форматов, например JSON для логов, облегчает поиск и агрегацию ошибок с помощью инструментов анализа.
Реакция на критические сбои должна включать автоматическое уведомление разработчиков через email или системы оповещений, а также возможность временной деградации сервиса для минимизации воздействия на пользователей.
Настройка времени отклика и управления нагрузкой
Время отклика серверного обработчика напрямую зависит от конфигурации соединений, обработки запросов и ресурсов системы. Для точного контроля используют следующие методы:
- Установка таймаутов на уровне HTTP-запросов и баз данных. Рекомендуется устанавливать таймаут соединения 2–5 секунд для внешних сервисов и 500–1000 мс для внутренних операций.
- Использование пулов соединений для баз данных и внешних API, чтобы сократить время установки соединения и снизить нагрузку на сервер.
- Оптимизация кода обработчиков: избегать блокирующих операций и использовать асинхронную обработку для параллельных запросов.
- Кэширование часто запрашиваемых данных в памяти (Redis, Memcached) для сокращения времени генерации ответа.
Для управления нагрузкой применяются следующие стратегии:
- Лимитирование количества одновременных подключений на сервере с помощью очередей или семафоров.
- Распределение нагрузки между несколькими экземплярами сервера с использованием балансировщиков нагрузки (Load Balancer).
- Динамическое масштабирование: автоматическое добавление серверов при превышении порогового значения запросов в секунду.
- Мониторинг производительности с использованием метрик CPU, памяти, времени отклика и числа активных соединений для своевременной оптимизации.
Для критически нагруженных систем рекомендуется комбинировать кэширование, асинхронную обработку и горизонтальное масштабирование, чтобы поддерживать стабильное время отклика ниже 200–300 мс при пиковых нагрузках.
Вопрос-ответ:
Что именно делает серверный обработчик при получении запроса?
Серверный обработчик принимает входящий HTTP-запрос, анализирует его метод (GET, POST, PUT и др.), извлекает параметры и тело запроса, а затем выполняет нужные действия: обращается к базе данных, запускает вычисления или обрабатывает файлы. После этого он формирует ответ с подходящими заголовками и содержимым и отправляет его клиенту.
Как серверный обработчик управляет ошибками во время выполнения?
Обработчик делит ошибки на клиентские и серверные. Клиентские ошибки фиксируются через коды 4xx, а серверные через 5xx. Внутри кода обработчика ошибки можно перехватывать с помощью try/catch или аналогичных конструкций, записывать стек вызовов и параметры запроса в лог, чтобы позже понять причину сбоя. Для некоторых ошибок можно настроить уведомления разработчиков или автоматическое восстановление процессов.
Почему важно правильно формировать заголовки ответа от сервера?
Заголовки определяют тип содержимого, управление кэшированием и корректность передачи данных. Например, Content-Type указывает браузеру, как интерпретировать тело ответа. Content-Length ускоряет отправку больших файлов, а Cache-Control позволяет клиенту использовать закэшированные данные без повторного запроса. Неправильные заголовки могут вызвать ошибки на клиентской стороне или увеличить нагрузку на сервер.
Какие методы помогают снизить время отклика серверного обработчика при высокой нагрузке?
Для сокращения времени отклика применяют несколько подходов: асинхронная обработка запросов позволяет выполнять параллельные операции без блокировки, кэширование уменьшает количество обращений к базе данных, а пул соединений ускоряет работу с внешними сервисами. Балансировщики нагрузки распределяют запросы между несколькими серверами, а лимиты одновременных соединений предотвращают перегрузку одного экземпляра.
Как правильно вести логирование, чтобы отслеживать работу сервера и ошибки?
Логи разделяют по уровням: INFO фиксирует нормальные операции, WARN — потенциальные проблемы, ERROR — критические сбои. Каждая запись содержит метку времени, идентификатор запроса, IP клиента и параметры запроса. Для больших объёмов данных используют асинхронную запись или внешние системы мониторинга. Структурированные форматы, например JSON, упрощают анализ и поиск проблем. Также полезно вести отдельные логи валидации данных, чтобы отличать ошибки клиента от сбоев сервера.
Как серверный обработчик определяет, какие данные отправлять клиенту?
Серверный обработчик формирует ответ на основе типа запроса и логики приложения. Для REST API это чаще всего JSON с нужными полями, для веб-страниц — HTML. Обработчик выбирает данные из базы, проверяет права доступа и применяет фильтры. Затем он формирует тело ответа и устанавливает заголовки, указывающие формат, длину и правила кэширования, чтобы клиент корректно обработал информацию.
Какие ошибки чаще всего возникают на уровне серверного обработчика и как их отслеживать?
На уровне обработчика встречаются ошибки синтаксиса запросов, нарушения валидации данных, таймауты обращения к базам и внутренние сбои кода. Для отслеживания используют логирование с указанием времени, идентификатора запроса, IP клиента и параметров. Ошибки разделяют по типу: клиентские (4xx) и серверные (5xx). В критических случаях на основе логов можно настроить уведомления для быстрого реагирования и предотвращения повторных сбоев.